 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSEED-GRPO: Semantic Entropy Enhanced GRPO for Uncertainty-Aware Policy Optimization
May 18, 2025Large language models (LLMs) exhibit varying levels of confidence across input prompts (questions): some lead to consistent, semantically similar answers, while others yield diverse or contradictory outputs. This variation reflects LLM's uncertainty about the input prompt, a signal of how confidently the model understands a given problem. However, vanilla Group Relative Policy Optimization (GRPO) treats all prompts equally during policy updates, ignoring this important information about the model's knowledge boundaries. To address this limitation, we propose SEED-GRPO (Semantic Entropy EnhanceD GRPO), which explicitly measures LLMs' uncertainty of the input prompts semantic entropy. Semantic entropy measures the diversity of meaning in multiple generated answers given a prompt and uses this to modulate the magnitude of policy updates. This uncertainty-aware training mechanism enables dynamic adjustment of policy update magnitudes based on question uncertainty. It allows more conservative updates on high-uncertainty questions while maintaining the original learning signal on confident ones. Experimental results on five mathematical reasoning benchmarks (AIME24 56.7, AMC 68.7, MATH 83.4, Minerva 34.2, and OlympiadBench 48.0) demonstrate that SEED-GRPO achieves new state-of-the-art performance in average accuracy, validating the effectiveness of uncertainty-aware policy optimization.
Chemical knowledge-informed framework for privacy-aware retrosynthesis learning
Feb 26, 2025



Chemical reaction data is a pivotal asset, driving advances in competitive fields such as pharmaceuticals, materials science, and industrial chemistry. Its proprietary nature renders it sensitive, as it often includes confidential insights and competitive advantages organizations strive to protect. However, in contrast to this need for confidentiality, the current standard training paradigm for machine learning-based retrosynthesis gathers reaction data from multiple sources into one single edge to train prediction models. This paradigm poses considerable privacy risks as it necessitates broad data availability across organizational boundaries and frequent data transmission between entities, potentially exposing proprietary information to unauthorized access or interception during storage and transfer. In the present study, we introduce the chemical knowledge-informed framework (CKIF), a privacy-preserving approach for learning retrosynthesis models. CKIF enables distributed training across multiple chemical organizations without compromising the confidentiality of proprietary reaction data. Instead of gathering raw reaction data, CKIF learns retrosynthesis models through iterative, chemical knowledge-informed aggregation of model parameters. In particular, the chemical properties of predicted reactants are leveraged to quantitatively assess the observable behaviors of individual models, which in turn determines the adaptive weights used for model aggregation. On a variety of reaction datasets, CKIF outperforms several strong baselines by a clear margin (e.g., ~20% performance improvement over FedAvg on USPTO-50K), showing its feasibility and superiority to stimulate further research on privacy-preserving retrosynthesis.
Scene Graph Generation with Role-Playing Large Language Models
Oct 20, 2024


Current approaches for open-vocabulary scene graph generation (OVSGG) use vision-language models such as CLIP and follow a standard zero-shot pipeline -- computing similarity between the query image and the text embeddings for each category (i.e., text classifiers). In this work, we argue that the text classifiers adopted by existing OVSGG methods, i.e., category-/part-level prompts, are scene-agnostic as they remain unchanged across contexts. Using such fixed text classifiers not only struggles to model visual relations with high variance, but also falls short in adapting to distinct contexts. To plug these intrinsic shortcomings, we devise SDSGG, a scene-specific description based OVSGG framework where the weights of text classifiers are adaptively adjusted according to the visual content. In particular, to generate comprehensive and diverse descriptions oriented to the scene, an LLM is asked to play different roles (e.g., biologist and engineer) to analyze and discuss the descriptive features of a given scene from different views. Unlike previous efforts simply treating the generated descriptions as mutually equivalent text classifiers, SDSGG is equipped with an advanced renormalization mechanism to adjust the influence of each text classifier based on its relevance to the presented scene (this is what the term "specific" means). Furthermore, to capture the complicated interplay between subjects and objects, we propose a new lightweight module called mutual visual adapter. It refines CLIP's ability to recognize relations by learning an interaction-aware semantic space. Extensive experiments on prevalent benchmarks show that SDSGG outperforms top-leading methods by a clear margin.
Hydra-SGG: Hybrid Relation Assignment for One-stage Scene Graph Generation
Sep 16, 2024



DETR introduces a simplified one-stage framework for scene graph generation (SGG). However, DETR-based SGG models face two challenges: i) Sparse supervision, as each image typically contains fewer than 10 relation annotations, while the models employ over 100 relation queries. This sparsity arises because each ground truth relation is assigned to only one single query during training. ii) False negative samples, since one ground truth relation may have multiple queries with similar matching scores. These suboptimally matched queries are simply treated as negative samples, causing the loss of valuable supervisory signals. As a response, we devise Hydra-SGG, a one-stage SGG method that adopts a new Hybrid Relation Assignment. This assignment combines a One-to-One Relation Assignment with a newly introduced IoU-based One-to-Many Relation Assignment. Specifically, each ground truth is assigned to multiple relation queries with high IoU subject-object boxes. This Hybrid Relation Assignment increases the number of positive training samples, alleviating sparse supervision. Moreover, we, for the first time, empirically show that self-attention over relation queries helps reduce duplicated relation predictions. We, therefore, propose Hydra Branch, a parameter-sharing auxiliary decoder without a self-attention layer. This design promotes One-to-Many Relation Assignment by enabling different queries to predict the same relation. Hydra-SGG achieves state-of-the-art performance with 10.6 mR@20 and 16.0 mR@50 on VG150, while only requiring 12 training epochs. It also sets a new state-of-the-art on Open Images V6 and and GQA.
Neural Clustering based Visual Representation Learning
Mar 26, 2024
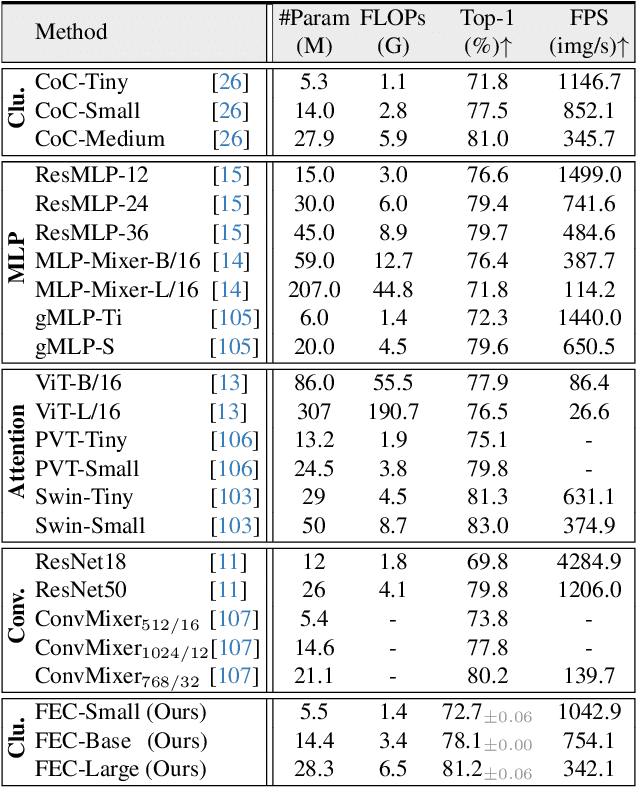
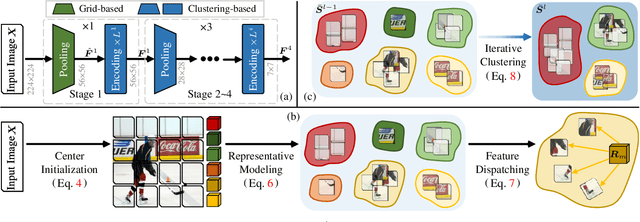
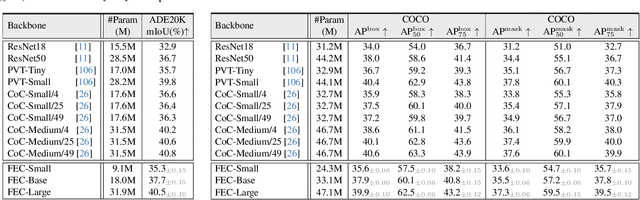
We investigate a fundamental aspect of machine vision: the measurement of features, by revisiting clustering, one of the most classic approaches in machine learning and data analysis. Existing visual feature extractors, including ConvNets, ViTs, and MLPs, represent an image as rectangular regions. Though prevalent, such a grid-style paradigm is built upon engineering practice and lacks explicit modeling of data distribution. In this work, we propose feature extraction with clustering (FEC), a conceptually elegant yet surprisingly ad-hoc interpretable neural clustering framework, which views feature extraction as a process of selecting representatives from data and thus automatically captures the underlying data distribution. Given an image, FEC alternates between grouping pixels into individual clusters to abstract representatives and updating the deep features of pixels with current representatives. Such an iterative working mechanism is implemented in the form of several neural layers and the final representatives can be used for downstream tasks. The cluster assignments across layers, which can be viewed and inspected by humans, make the forward process of FEC fully transparent and empower it with promising ad-hoc interpretability. Extensive experiments on various visual recognition models and tasks verify the effectiveness, generality, and interpretability of FEC. We expect this work will provoke a rethink of the current de facto grid-style paradigm.
DoraemonGPT: Toward Understanding Dynamic Scenes with Large Language Models
Jan 16, 2024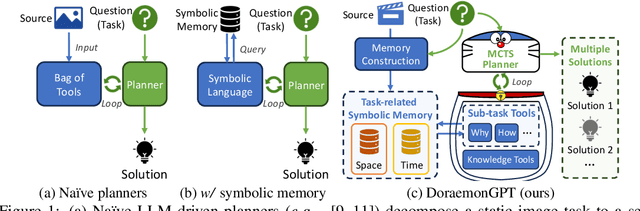

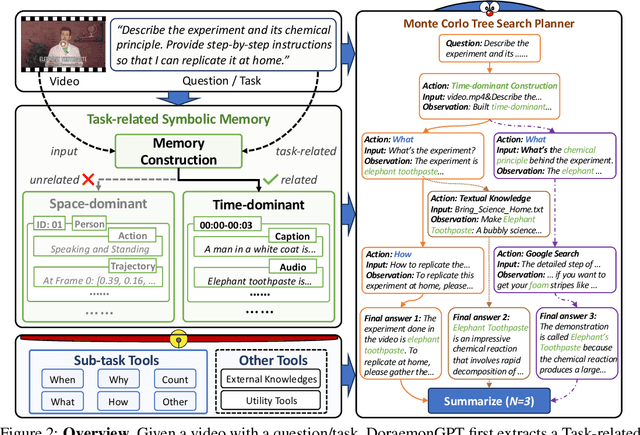
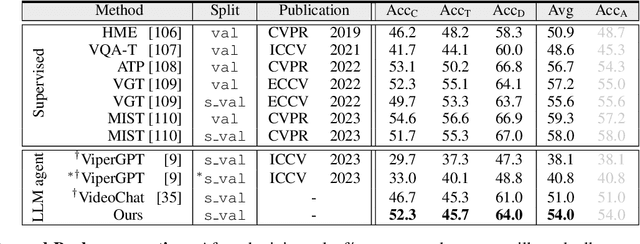
The field of AI agents is advancing at an unprecedented rate due to the capabilities of large language models (LLMs). However, LLM-driven visual agents mainly focus on solving tasks for the image modality, which limits their ability to understand the dynamic nature of the real world, making it still far from real-life applications, e.g., guiding students in laboratory experiments and identifying their mistakes. Considering the video modality better reflects the ever-changing and perceptually intensive nature of real-world scenarios, we devise DoraemonGPT, a comprehensive and conceptually elegant system driven by LLMs to handle dynamic video tasks. Given a video with a question/task, DoraemonGPT begins by converting the input video with massive content into a symbolic memory that stores \textit{task-related} attributes. This structured representation allows for spatial-temporal querying and reasoning by sub-task tools, resulting in concise and relevant intermediate results. Recognizing that LLMs have limited internal knowledge when it comes to specialized domains (e.g., analyzing the scientific principles underlying experiments), we incorporate plug-and-play tools to assess external knowledge and address tasks across different domains. Moreover, we introduce a novel LLM-driven planner based on Monte Carlo Tree Search to efficiently explore the large planning space for scheduling various tools. The planner iteratively finds feasible solutions by backpropagating the result's reward, and multiple solutions can be summarized into an improved final answer. We extensively evaluate DoraemonGPT in dynamic scenes and provide in-the-wild showcases demonstrating its ability to handle more complex questions than previous studies.
A Survey on 3D Gaussian Splatting
Jan 08, 2024

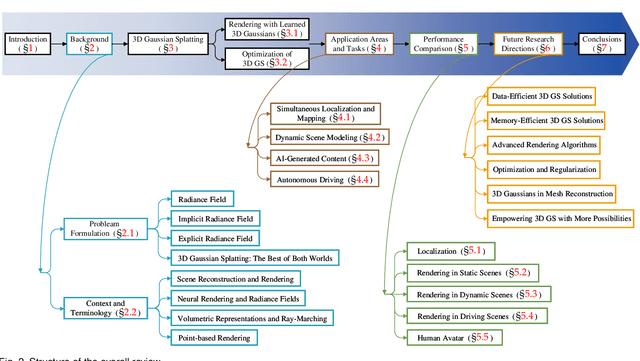

3D Gaussian splatting (3D GS) has recently emerged as a transformative technique in the explicit radiance field and computer graphics landscape. This innovative approach, characterized by the utilization of millions of 3D Gaussians, represents a significant departure from the neural radiance field (NeRF) methodologies, which predominantly use implicit, coordinate-based models to map spatial coordinates to pixel values. 3D GS, with its explicit scene representations and differentiable rendering algorithms, not only promises real-time rendering capabilities but also introduces unprecedented levels of control and editability. This positions 3D GS as a potential game-changer for the next generation of 3D reconstruction and representation. In the present paper, we provide the first systematic overview of the recent developments and critical contributions in the domain of 3D GS. We begin with a detailed exploration of the underlying principles and the driving forces behind the advent of 3D GS, setting the stage for understanding its significance. A focal point of our discussion is the practical applicability of 3D GS. By facilitating real-time performance, 3D GS opens up a plethora of applications, ranging from virtual reality to interactive media and beyond. This is complemented by a comparative analysis of leading 3D GS models, evaluated across various benchmark tasks to highlight their performance and practical utility. The survey concludes by identifying current challenges and suggesting potential avenues for future research in this domain. Through this survey, we aim to provide a valuable resource for both newcomers and seasoned researchers, fostering further exploration and advancement in applicable and explicit radiance field representation.
Compositional Zero-shot Learning via Progressive Language-based Observations
Nov 23, 2023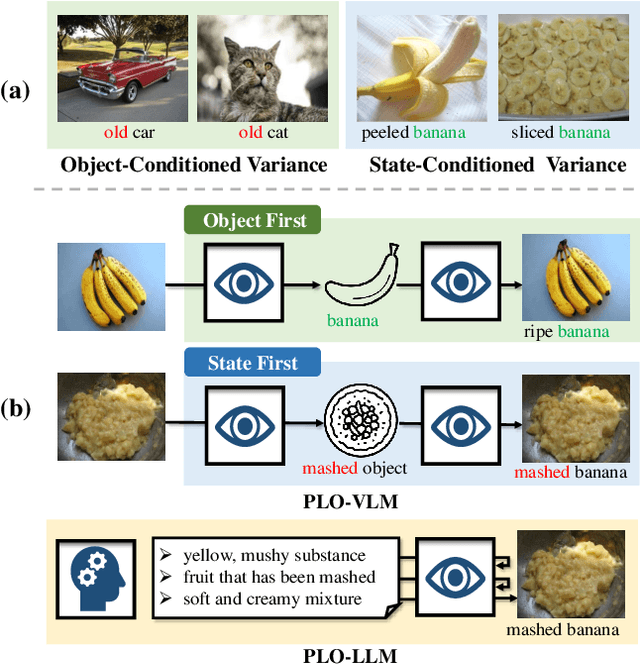
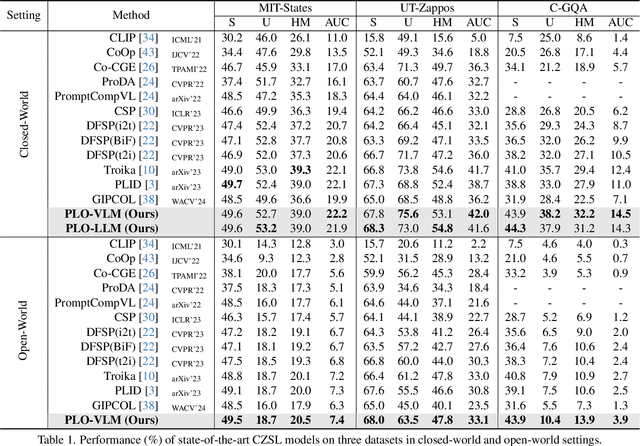
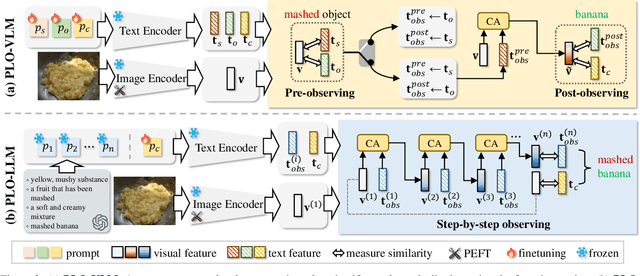
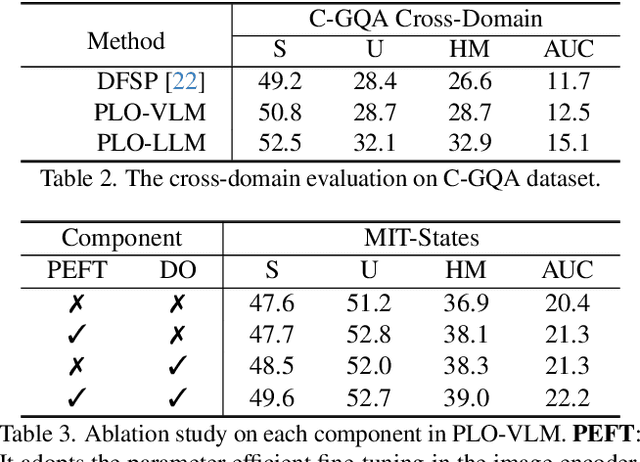
Compositional zero-shot learning aims to recognize unseen state-object compositions by leveraging known primitives (state and object) during training. However, effectively modeling interactions between primitives and generalizing knowledge to novel compositions remains a perennial challenge. There are two key factors: object-conditioned and state-conditioned variance, i.e., the appearance of states (or objects) can vary significantly when combined with different objects (or states). For instance, the state "old" can signify a vintage design for a "car" or an advanced age for a "cat". In this paper, we argue that these variances can be mitigated by predicting composition categories based on pre-observed primitive. To this end, we propose Progressive Language-based Observations (PLO), which can dynamically determine a better observation order of primitives. These observations comprise a series of concepts or languages that allow the model to understand image content in a step-by-step manner. Specifically, PLO adopts pre-trained vision-language models (VLMs) to empower the model with observation capabilities. We further devise two variants: 1) PLO-VLM: a two-step method, where a pre-observing classifier dynamically determines the observation order of two primitives. 2) PLO-LLM: a multi-step scheme, which utilizes large language models (LLMs) to craft composition-specific prompts for step-by-step observing. Extensive ablations on three challenging datasets demonstrate the superiority of PLO compared with state-of-the-art methods, affirming its abilities in compositional recognition.
Compositional Feature Augmentation for Unbiased Scene Graph Generation
Aug 13, 2023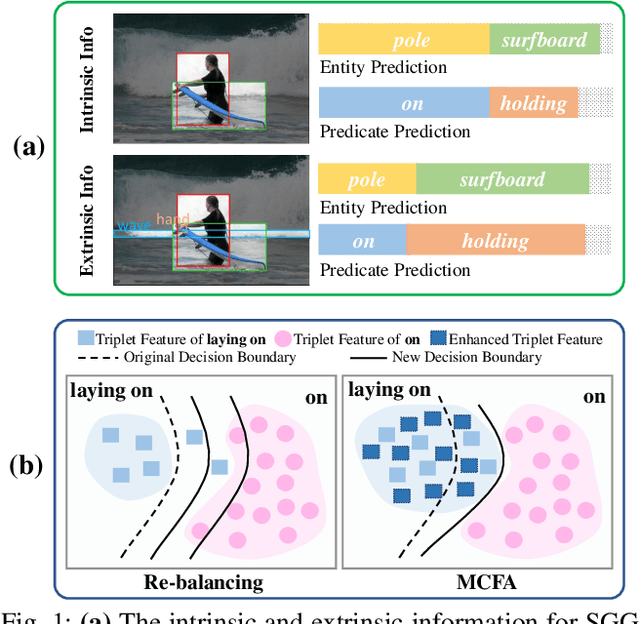
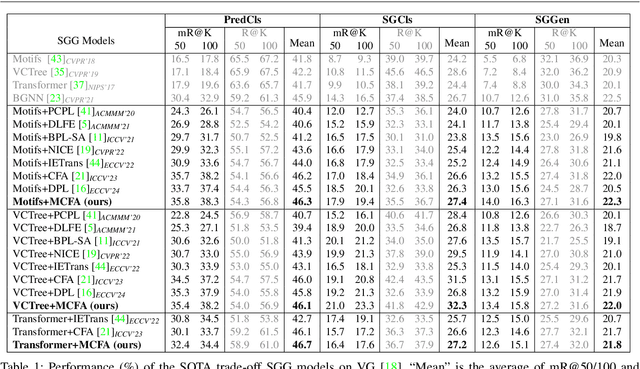
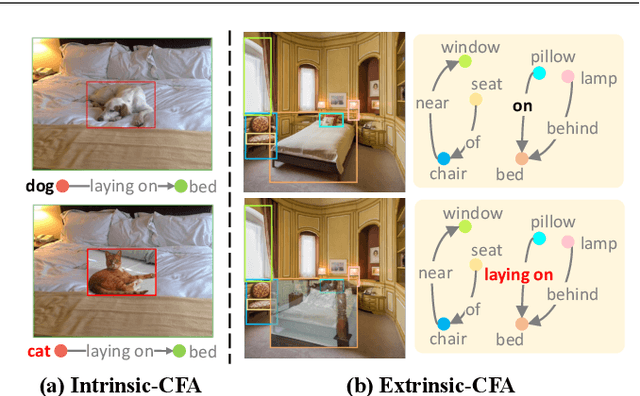
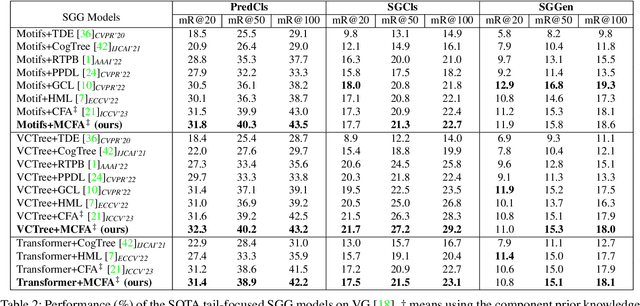
Scene Graph Generation (SGG) aims to detect all the visual relation triplets <sub, pred, obj> in a given image. With the emergence of various advanced techniques for better utilizing both the intrinsic and extrinsic information in each relation triplet, SGG has achieved great progress over the recent years. However, due to the ubiquitous long-tailed predicate distributions, today's SGG models are still easily biased to the head predicates. Currently, the most prevalent debiasing solutions for SGG are re-balancing methods, e.g., changing the distributions of original training samples. In this paper, we argue that all existing re-balancing strategies fail to increase the diversity of the relation triplet features of each predicate, which is critical for robust SGG. To this end, we propose a novel Compositional Feature Augmentation (CFA) strategy, which is the first unbiased SGG work to mitigate the bias issue from the perspective of increasing the diversity of triplet features. Specifically, we first decompose each relation triplet feature into two components: intrinsic feature and extrinsic feature, which correspond to the intrinsic characteristics and extrinsic contexts of a relation triplet, respectively. Then, we design two different feature augmentation modules to enrich the feature diversity of original relation triplets by replacing or mixing up either their intrinsic or extrinsic features from other samples. Due to its model-agnostic nature, CFA can be seamlessly incorporated into various SGG frameworks. Extensive ablations have shown that CFA achieves a new state-of-the-art performance on the trade-off between different metrics.
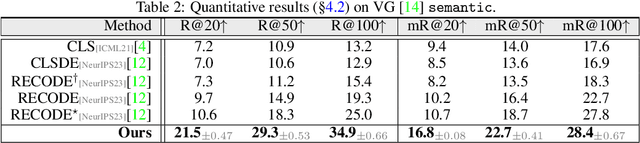
Zero-shot Visual Relation Detection via Composite Visual Cues from Large Language Models
May 21, 2023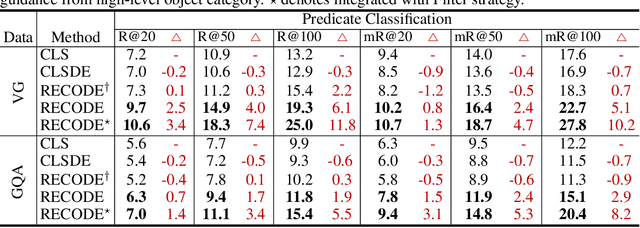
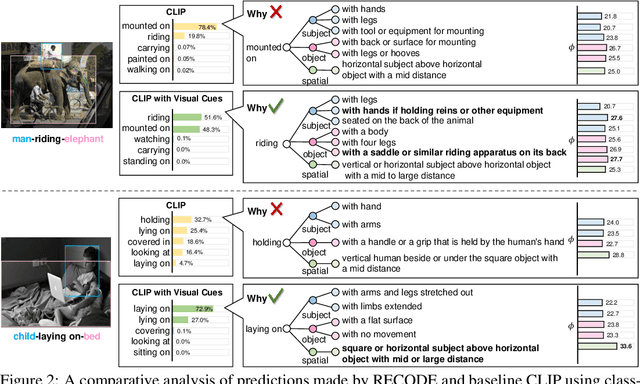
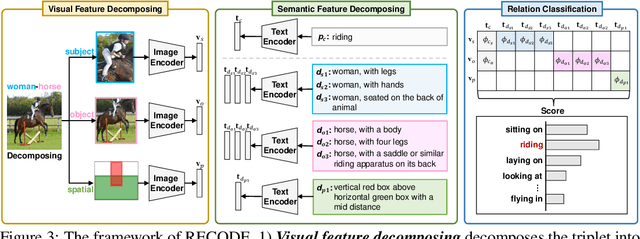
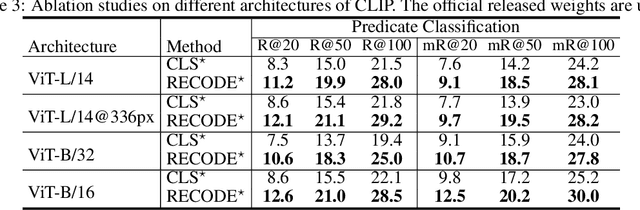
Pretrained vision-language models, such as CLIP, have demonstrated strong generalization capabilities, making them promising tools in the realm of zero-shot visual recognition. Visual relation detection (VRD) is a typical task that identifies relationship (or interaction) types between object pairs within an image. However, naively utilizing CLIP with prevalent class-based prompts for zero-shot VRD has several weaknesses, e.g., it struggles to distinguish between different fine-grained relation types and it neglects essential spatial information of two objects. To this end, we propose a novel method for zero-shot VRD: RECODE, which solves RElation detection via COmposite DEscription prompts. Specifically, RECODE first decomposes each predicate category into subject, object, and spatial components. Then, it leverages large language models (LLMs) to generate description-based prompts (or visual cues) for each component. Different visual cues enhance the discriminability of similar relation categories from different perspectives, which significantly boosts performance in VRD. To dynamically fuse different cues, we further introduce a chain-of-thought method that prompts LLMs to generate reasonable weights for different visual cues. Extensive experiments on four VRD benchmarks have demonstrated the effectiveness and interpretability of RECODE.