 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCompositional Zero-shot Learning via Progressive Language-based Observations
Paper and Code
Nov 23, 2023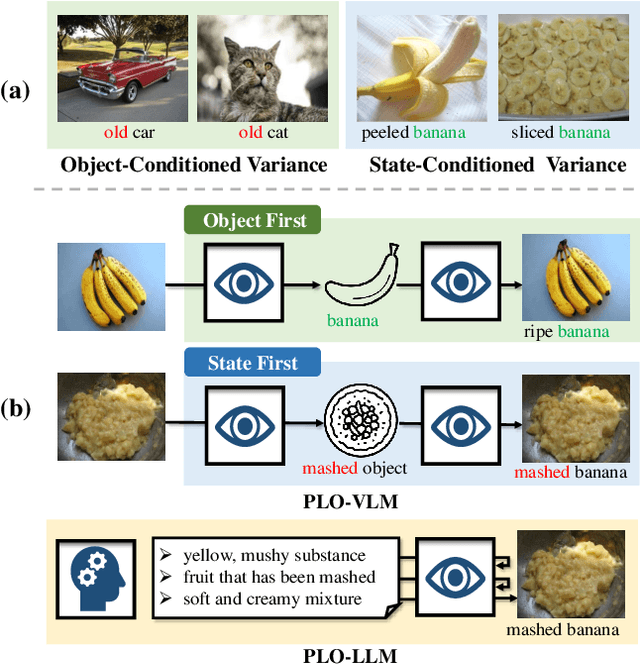
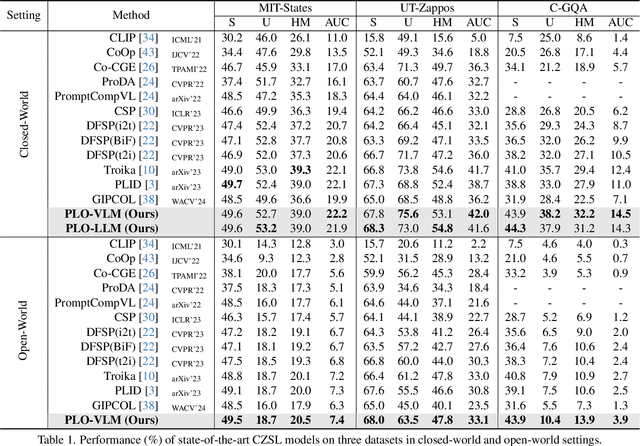
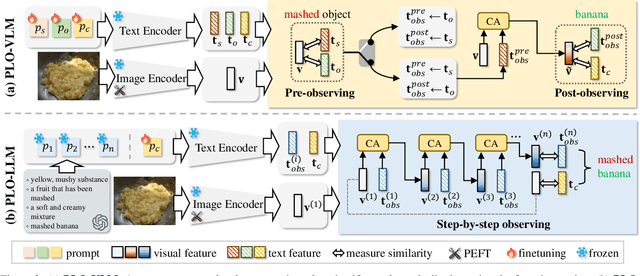
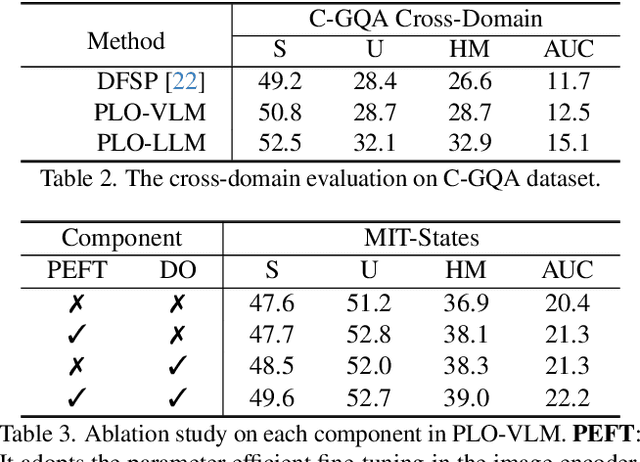
Compositional zero-shot learning aims to recognize unseen state-object compositions by leveraging known primitives (state and object) during training. However, effectively modeling interactions between primitives and generalizing knowledge to novel compositions remains a perennial challenge. There are two key factors: object-conditioned and state-conditioned variance, i.e., the appearance of states (or objects) can vary significantly when combined with different objects (or states). For instance, the state "old" can signify a vintage design for a "car" or an advanced age for a "cat". In this paper, we argue that these variances can be mitigated by predicting composition categories based on pre-observed primitive. To this end, we propose Progressive Language-based Observations (PLO), which can dynamically determine a better observation order of primitives. These observations comprise a series of concepts or languages that allow the model to understand image content in a step-by-step manner. Specifically, PLO adopts pre-trained vision-language models (VLMs) to empower the model with observation capabilities. We further devise two variants: 1) PLO-VLM: a two-step method, where a pre-observing classifier dynamically determines the observation order of two primitives. 2) PLO-LLM: a multi-step scheme, which utilizes large language models (LLMs) to craft composition-specific prompts for step-by-step observing. Extensive ablations on three challenging datasets demonstrate the superiority of PLO compared with state-of-the-art methods, affirming its abilities in compositional recognition.