 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScene Graph Generation with Role-Playing Large Language Models
Paper and Code



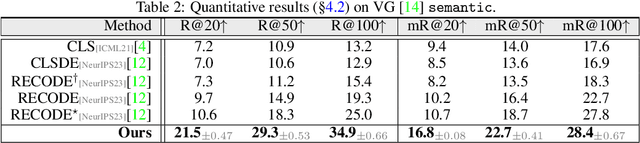
Current approaches for open-vocabulary scene graph generation (OVSGG) use vision-language models such as CLIP and follow a standard zero-shot pipeline -- computing similarity between the query image and the text embeddings for each category (i.e., text classifiers). In this work, we argue that the text classifiers adopted by existing OVSGG methods, i.e., category-/part-level prompts, are scene-agnostic as they remain unchanged across contexts. Using such fixed text classifiers not only struggles to model visual relations with high variance, but also falls short in adapting to distinct contexts. To plug these intrinsic shortcomings, we devise SDSGG, a scene-specific description based OVSGG framework where the weights of text classifiers are adaptively adjusted according to the visual content. In particular, to generate comprehensive and diverse descriptions oriented to the scene, an LLM is asked to play different roles (e.g., biologist and engineer) to analyze and discuss the descriptive features of a given scene from different views. Unlike previous efforts simply treating the generated descriptions as mutually equivalent text classifiers, SDSGG is equipped with an advanced renormalization mechanism to adjust the influence of each text classifier based on its relevance to the presented scene (this is what the term "specific" means). Furthermore, to capture the complicated interplay between subjects and objects, we propose a new lightweight module called mutual visual adapter. It refines CLIP's ability to recognize relations by learning an interaction-aware semantic space. Extensive experiments on prevalent benchmarks show that SDSGG outperforms top-leading methods by a clear margin.