 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTask-wise Split Gradient Boosting Trees for Multi-center Diabetes Prediction
Aug 16, 2021



Diabetes prediction is an important data science application in the social healthcare domain. There exist two main challenges in the diabetes prediction task: data heterogeneity since demographic and metabolic data are of different types, data insufficiency since the number of diabetes cases in a single medical center is usually limited. To tackle the above challenges, we employ gradient boosting decision trees (GBDT) to handle data heterogeneity and introduce multi-task learning (MTL) to solve data insufficiency. To this end, Task-wise Split Gradient Boosting Trees (TSGB) is proposed for the multi-center diabetes prediction task. Specifically, we firstly introduce task gain to evaluate each task separately during tree construction, with a theoretical analysis of GBDT's learning objective. Secondly, we reveal a problem when directly applying GBDT in MTL, i.e., the negative task gain problem. Finally, we propose a novel split method for GBDT in MTL based on the task gain statistics, named task-wise split, as an alternative to standard feature-wise split to overcome the mentioned negative task gain problem. Extensive experiments on a large-scale real-world diabetes dataset and a commonly used benchmark dataset demonstrate TSGB achieves superior performance against several state-of-the-art methods. Detailed case studies further support our analysis of negative task gain problems and provide insightful findings. The proposed TSGB method has been deployed as an online diabetes risk assessment software for early diagnosis.
Deep Multi-Scale Resemblance Network for the Sub-class Differentiation of Adrenal Masses on Computed Tomography Images
Jul 29, 2020
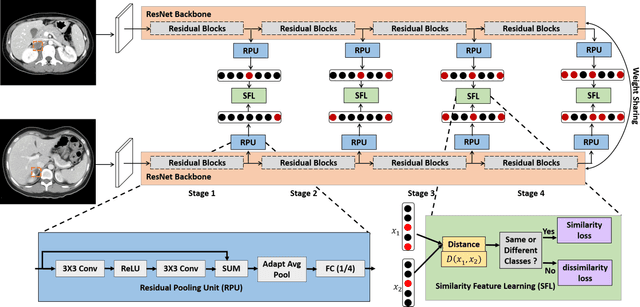
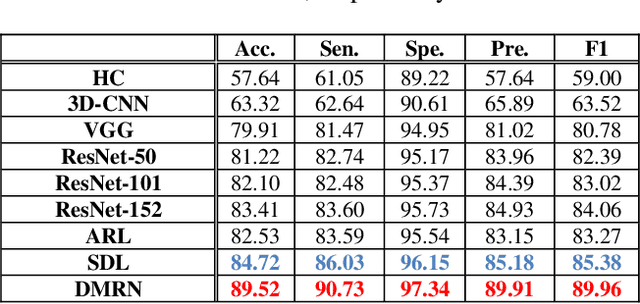
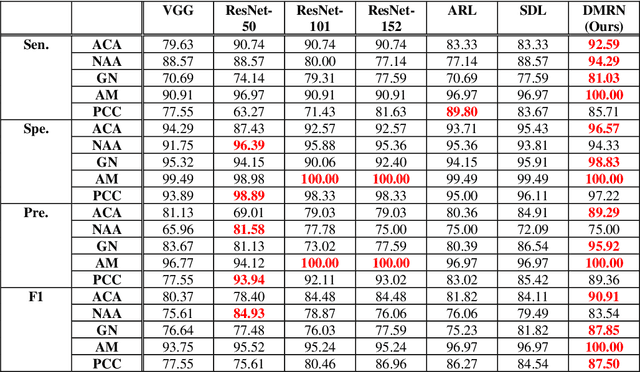
Objective: The accurate classification of mass lesions in the adrenal glands ('adrenal masses'), detected with computed tomography (CT), is important for diagnosis and patient management. Adrenal masses can be benign or malignant and the benign masses have varying prevalence. Classification methods based on convolutional neural networks (CNN) are the state-of-the-art in maximizing inter-class differences in large medical imaging training datasets. The application of CNNs, to adrenal masses is challenging due to large intra-class variations, large inter-class similarities and imbalanced training data due to the size of masses. Methods: We developed a deep multi-scale resemblance network (DMRN) to overcome these limitations and leveraged paired CNNs to evaluate the intra-class similarities. We used multi-scale feature embedding to improve the inter-class separability by iteratively combining complementary information produced at different scales of the input to create structured feature descriptors. We also augmented the training data with randomly sampled paired adrenal masses to reduce the influence of imbalanced training data. We used 229 CT scans of patients with adrenal masses. Results: Our method had the best results compared to state-of-the-art methods. Conclusion: Our DMRN sub-classified adrenal masses on CT and was superior to state-of-the-art approaches.