 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneration of Human Comprehensible Access Control Policies from Audit Logs
Mar 15, 2026Over the years, access control systems have become increasingly more complex, often causing a disconnect between what is envisaged by the stakeholders in decision-making positions and the actual permissions granted as evidenced from access logs. For instance, Attribute-based Access Control (ABAC), which is a flexible yet complex model typically configured by system security officers, can be made understandable to others only when presented at a high level in natural language. Although several algorithms have been proposed in the literature for automatic extraction of ABAC rules from access logs, there is no attempt yet to bridge the semantic gap between the machine-enforceable formal logic and human-centric policy intent. Our work addresses this problem by developing a framework that generates human understandable natural language access control policies from logs. We investigate to what extent the power of Large Language Models (LLMs) can be harnessed to achieve both accuracy and scalability in the process. Named LANTERN (LLM-based ABAC Natural Translation and Explanation for Rule Navigation), we have instantiated the framework as a publicly accessible web based application for reproducibility of our results.
Closing Speed Computation using Stereo Camera and Applications in Unsignalized T-Intersection
Dec 30, 2024



This letter presents a conflict resolution strategy for an autonomous vehicle mounted with a stereo camera approaching an unsignalized T-intersection. A mathematical model for uncertainty in stereo camera depth measurements is considered and an analysis establishes the proposed adaptive depth sampling logic which guarantees an upper bound on the computed closing speed. Further, a collision avoidance logic is proposed that utilizes the closing speed bound and generates a safe trajectory plan based on the convex hull property of a quadratic B\'ezier curve-based reference path. Realistic validation studies are presented with neighboring vehicle trajectories generated using Next Generation Simulation (NGSIM) dataset.
Controllability-Constrained Deep Network Models for Enhanced Control of Dynamical Systems
Nov 11, 2023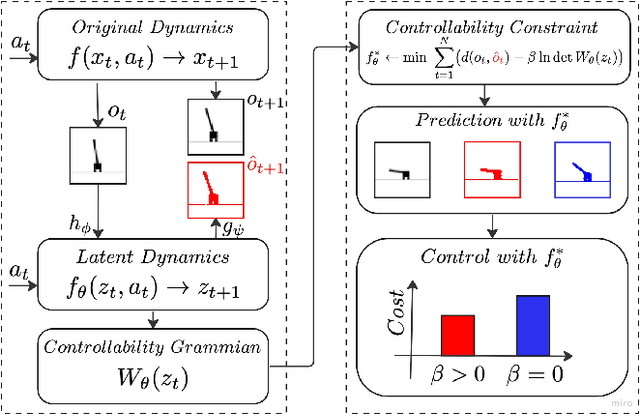
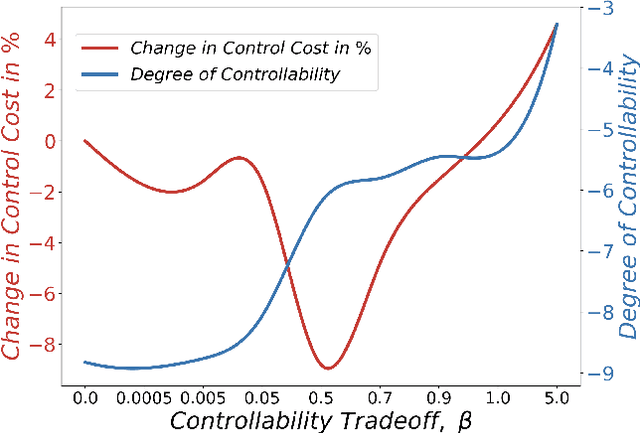
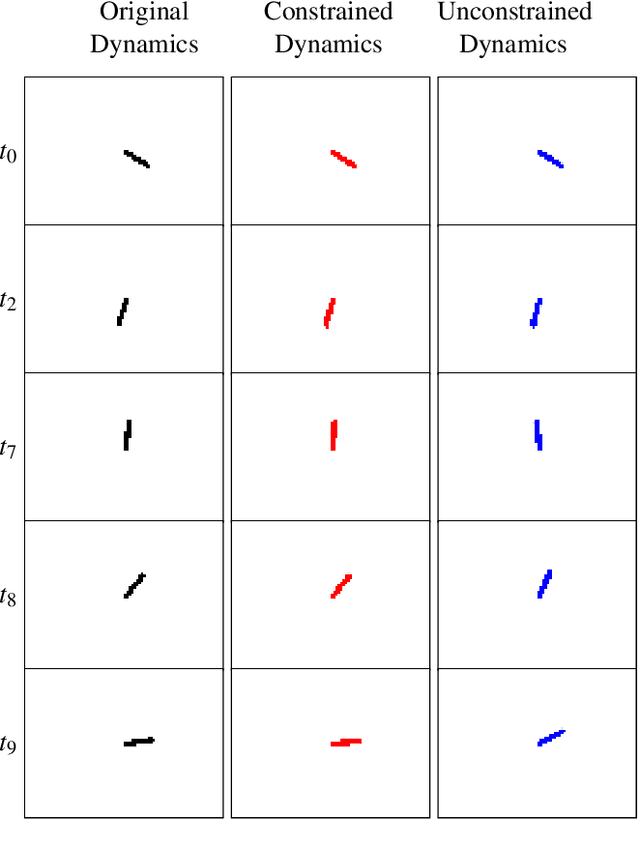
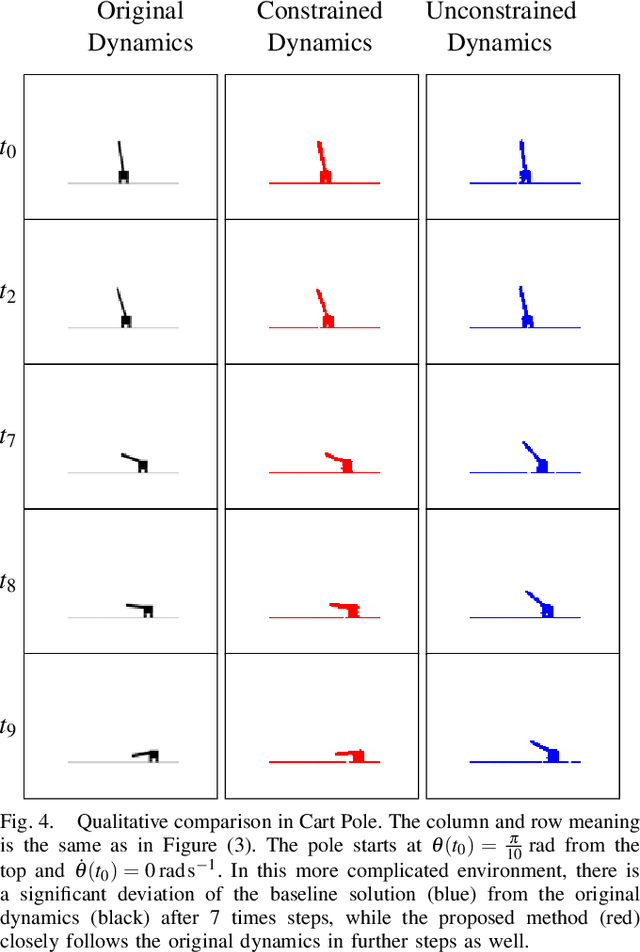
Control of a dynamical system without the knowledge of dynamics is an important and challenging task. Modern machine learning approaches, such as deep neural networks (DNNs), allow for the estimation of a dynamics model from control inputs and corresponding state observation outputs. Such data-driven models are often utilized for the derivation of model-based controllers. However, in general, there are no guarantees that a model represented by DNNs will be controllable according to the formal control-theoretical meaning of controllability, which is crucial for the design of effective controllers. This often precludes the use of DNN-estimated models in applications, where formal controllability guarantees are required. In this proof-of-the-concept work, we propose a control-theoretical method that explicitly enhances models estimated from data with controllability. That is achieved by augmenting the model estimation objective with a controllability constraint, which penalizes models with a low degree of controllability. As a result, the models estimated with the proposed controllability constraint allow for the derivation of more efficient controllers, they are interpretable by the control-theoretical quantities and have a lower long-term prediction error. The proposed method provides new insights on the connection between the DNN-based estimation of unknown dynamics and the control-theoretical guarantees of the solution properties. We demonstrate the superiority of the proposed method in two standard classical control systems with state observation given by low resolution high-dimensional images.
Data-Driven Predictive Modeling of Neuronal Dynamics using Long Short-Term Memory
Aug 11, 2019

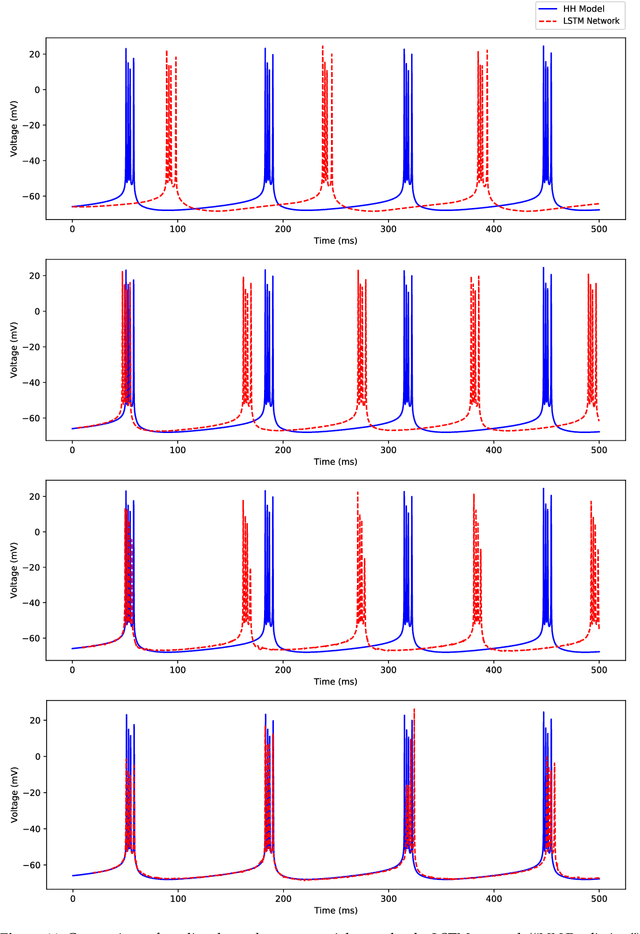
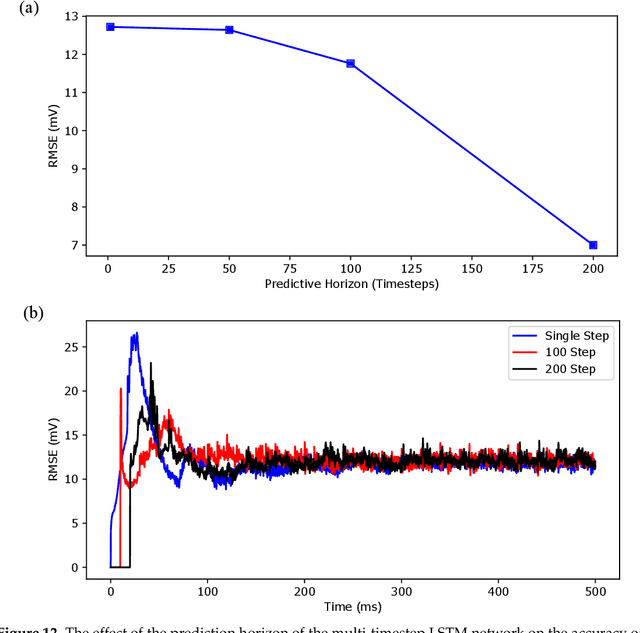
Modeling brain dynamics to better understand and control complex behaviors underlying various cognitive brain functions are of interests to engineers, mathematicians, and physicists from the last several decades. With a motivation of developing computationally efficient models of brain dynamics to use in designing control-theoretic neurostimulation strategies, we have developed a novel data-driven approach in a long short-term memory (LSTM) neural network architecture to predict the temporal dynamics of complex systems over an extended long time-horizon in future. In contrast to recent LSTM-based dynamical modeling approaches that make use of multi-layer perceptrons or linear combination layers as output layers, our architecture uses a single fully connected output layer and reversed-order sequence-to-sequence mapping to improve short time-horizon prediction accuracy and to make multi-timestep predictions of dynamical behaviors. We demonstrate the efficacy of our approach in reconstructing the regular spiking to bursting dynamics exhibited by an experimentally-validated 9-dimensional Hodgkin-Huxley model of hippocampal CA1 pyramidal neurons. Through simulations, we show that our LSTM neural network can predict the multi-time scale temporal dynamics underlying various spiking patterns with reasonable accuracy. Moreover, our results show that the predictions improve with increasing predictive time-horizon in the multi-timestep deep LSTM neural network.
Large-Scale 3D Shape Reconstruction and Segmentation from ShapeNet Core55
Oct 27, 2017
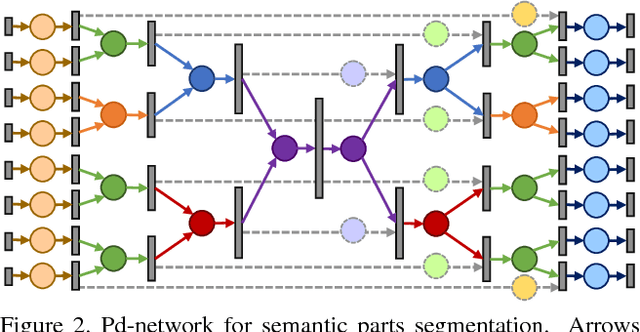
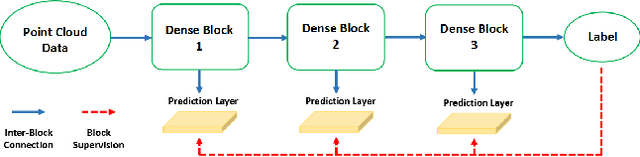
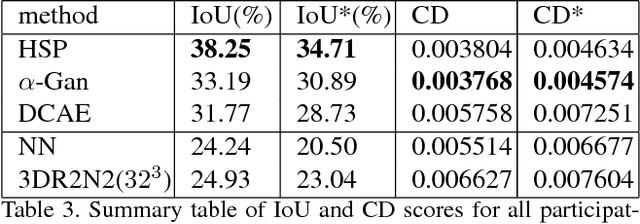
We introduce a large-scale 3D shape understanding benchmark using data and annotation from ShapeNet 3D object database. The benchmark consists of two tasks: part-level segmentation of 3D shapes and 3D reconstruction from single view images. Ten teams have participated in the challenge and the best performing teams have outperformed state-of-the-art approaches on both tasks. A few novel deep learning architectures have been proposed on various 3D representations on both tasks. We report the techniques used by each team and the corresponding performances. In addition, we summarize the major discoveries from the reported results and possible trends for the future work in the field.
Text Recognition in Scene Image and Video Frame using Color Channel Selection
Jul 27, 2017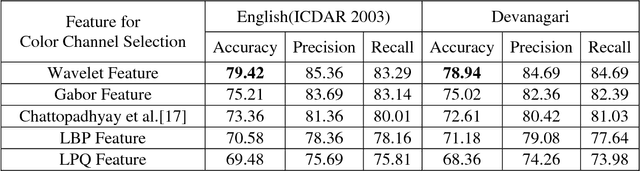
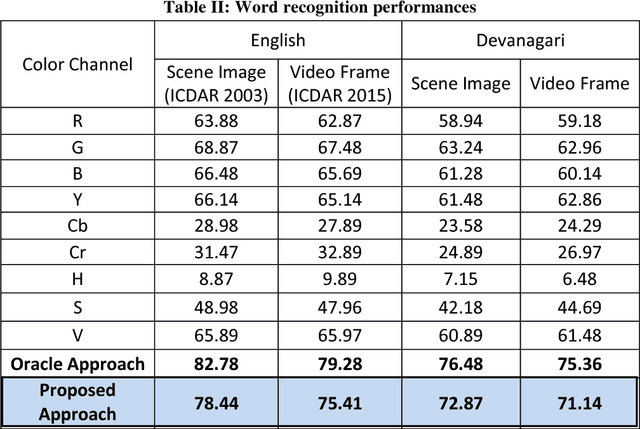
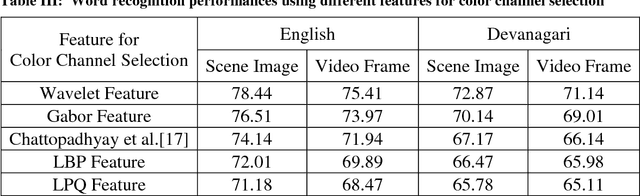

In recent years, recognition of text from natural scene image and video frame has got increased attention among the researchers due to its various complexities and challenges. Because of low resolution, blurring effect, complex background, different fonts, color and variant alignment of text within images and video frames, etc., text recognition in such scenario is difficult. Most of the current approaches usually apply a binarization algorithm to convert them into binary images and next OCR is applied to get the recognition result. In this paper, we present a novel approach based on color channel selection for text recognition from scene images and video frames. In the approach, at first, a color channel is automatically selected and then selected color channel is considered for text recognition. Our text recognition framework is based on Hidden Markov Model (HMM) which uses Pyramidal Histogram of Oriented Gradient features extracted from selected color channel. From each sliding window of a color channel our color-channel selection approach analyzes the image properties from the sliding window and then a multi-label Support Vector Machine (SVM) classifier is applied to select the color channel that will provide the best recognition results in the sliding window. This color channel selection for each sliding window has been found to be more fruitful than considering a single color channel for the whole word image. Five different features have been analyzed for multi-label SVM based color channel selection where wavelet transform based feature outperforms others. Our framework has been tested on different publicly available scene/video text image datasets. For Devanagari script, we collected our own data dataset. The performances obtained from experimental results are encouraging and show the advantage of the proposed method.