 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEVAL: EigenVector-based Average-reward Learning
Jan 15, 2025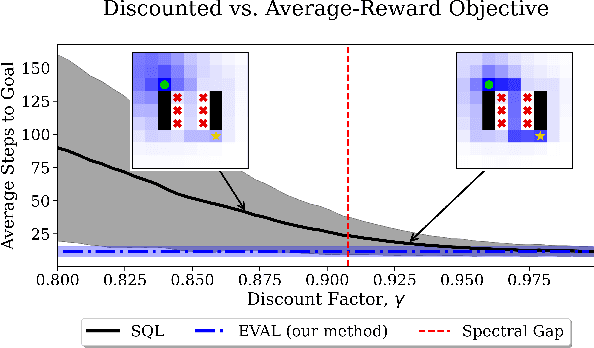


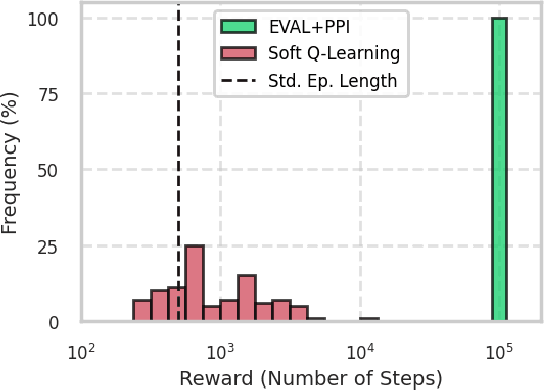
In reinforcement learning, two objective functions have been developed extensively in the literature: discounted and averaged rewards. The generalization to an entropy-regularized setting has led to improved robustness and exploration for both of these objectives. Recently, the entropy-regularized average-reward problem was addressed using tools from large deviation theory in the tabular setting. This method has the advantage of linearity, providing access to both the optimal policy and average reward-rate through properties of a single matrix. In this paper, we extend that framework to more general settings by developing approaches based on function approximation by neural networks. This formulation reveals new theoretical insights into the relationship between different objectives used in RL. Additionally, we combine our algorithm with a posterior policy iteration scheme, showing how our approach can also solve the average-reward RL problem without entropy-regularization. Using classic control benchmarks, we experimentally find that our method compares favorably with other algorithms in terms of stability and rate of convergence.
Bootstrapped Reward Shaping
Jan 02, 2025



In reinforcement learning, especially in sparse-reward domains, many environment steps are required to observe reward information. In order to increase the frequency of such observations, "potential-based reward shaping" (PBRS) has been proposed as a method of providing a more dense reward signal while leaving the optimal policy invariant. However, the required "potential function" must be carefully designed with task-dependent knowledge to not deter training performance. In this work, we propose a "bootstrapped" method of reward shaping, termed BSRS, in which the agent's current estimate of the state-value function acts as the potential function for PBRS. We provide convergence proofs for the tabular setting, give insights into training dynamics for deep RL, and show that the proposed method improves training speed in the Atari suite.
Boosting Soft Q-Learning by Bounding
Jun 26, 2024



An agent's ability to leverage past experience is critical for efficiently solving new tasks. Prior work has focused on using value function estimates to obtain zero-shot approximations for solutions to a new task. In soft Q-learning, we show how any value function estimate can also be used to derive double-sided bounds on the optimal value function. The derived bounds lead to new approaches for boosting training performance which we validate experimentally. Notably, we find that the proposed framework suggests an alternative method for updating the Q-function, leading to boosted performance.
Controllability-Constrained Deep Network Models for Enhanced Control of Dynamical Systems
Nov 11, 2023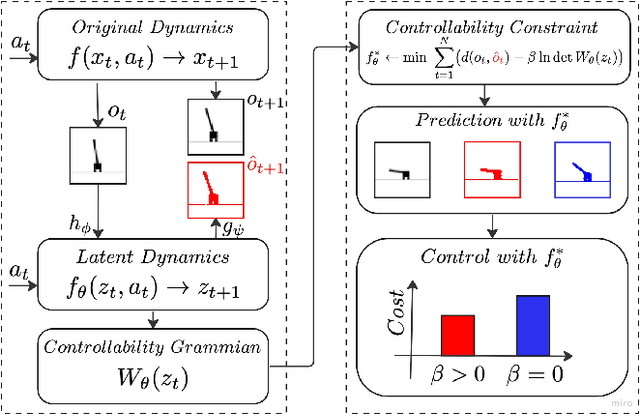
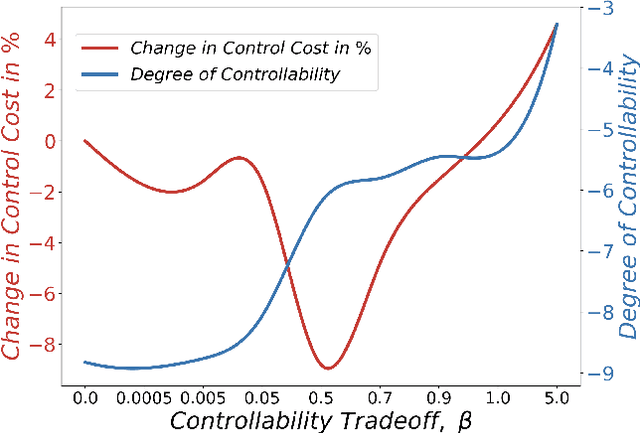
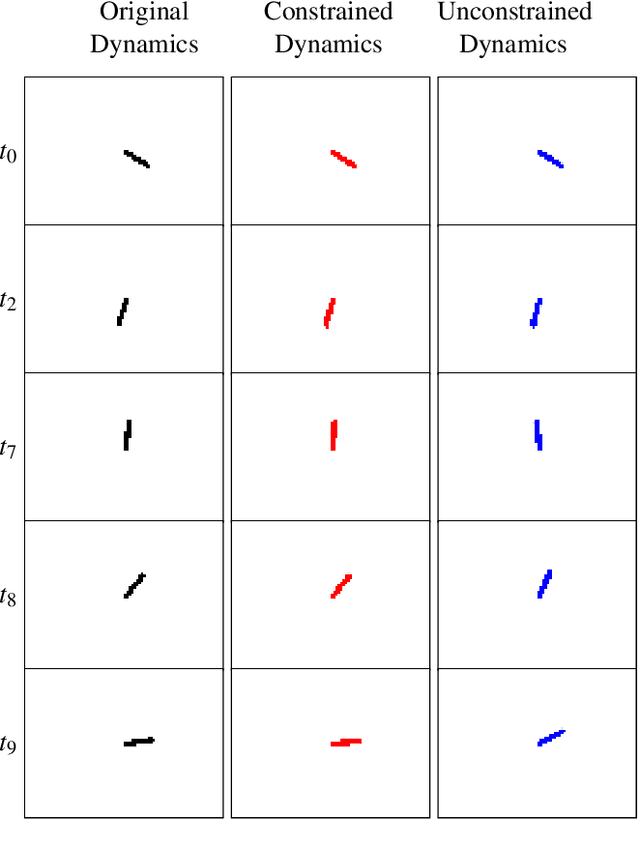
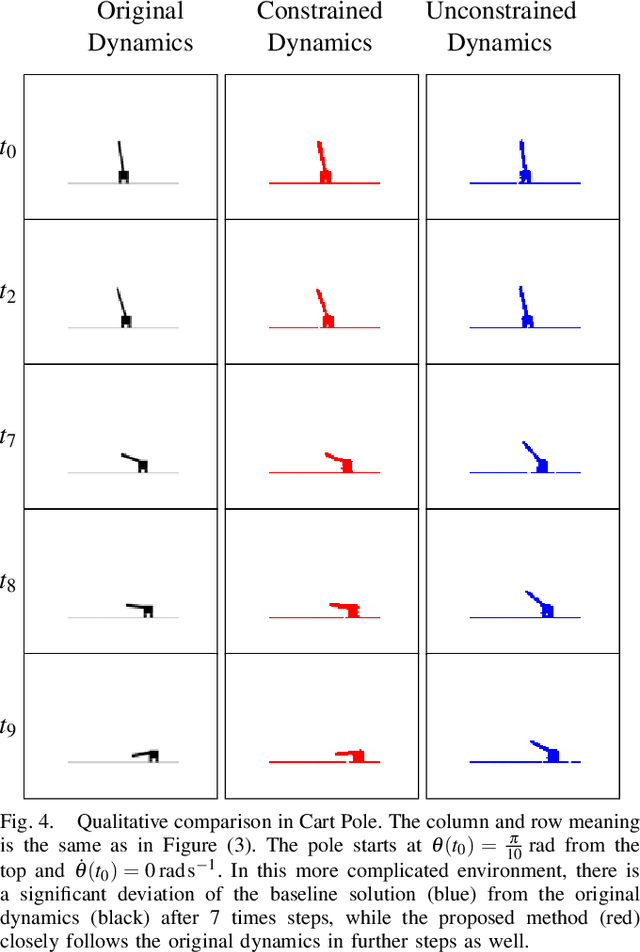
Control of a dynamical system without the knowledge of dynamics is an important and challenging task. Modern machine learning approaches, such as deep neural networks (DNNs), allow for the estimation of a dynamics model from control inputs and corresponding state observation outputs. Such data-driven models are often utilized for the derivation of model-based controllers. However, in general, there are no guarantees that a model represented by DNNs will be controllable according to the formal control-theoretical meaning of controllability, which is crucial for the design of effective controllers. This often precludes the use of DNN-estimated models in applications, where formal controllability guarantees are required. In this proof-of-the-concept work, we propose a control-theoretical method that explicitly enhances models estimated from data with controllability. That is achieved by augmenting the model estimation objective with a controllability constraint, which penalizes models with a low degree of controllability. As a result, the models estimated with the proposed controllability constraint allow for the derivation of more efficient controllers, they are interpretable by the control-theoretical quantities and have a lower long-term prediction error. The proposed method provides new insights on the connection between the DNN-based estimation of unknown dynamics and the control-theoretical guarantees of the solution properties. We demonstrate the superiority of the proposed method in two standard classical control systems with state observation given by low resolution high-dimensional images.
Bounding the Optimal Value Function in Compositional Reinforcement Learning
Mar 05, 2023



In the field of reinforcement learning (RL), agents are often tasked with solving a variety of problems differing only in their reward functions. In order to quickly obtain solutions to unseen problems with new reward functions, a popular approach involves functional composition of previously solved tasks. However, previous work using such functional composition has primarily focused on specific instances of composition functions whose limiting assumptions allow for exact zero-shot composition. Our work unifies these examples and provides a more general framework for compositionality in both standard and entropy-regularized RL. We find that, for a broad class of functions, the optimal solution for the composite task of interest can be related to the known primitive task solutions. Specifically, we present double-sided inequalities relating the optimal composite value function to the value functions for the primitive tasks. We also show that the regret of using a zero-shot policy can be bounded for this class of functions. The derived bounds can be used to develop clipping approaches for reducing uncertainty during training, allowing agents to quickly adapt to new tasks.