 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEventSTR: A Benchmark Dataset and Baselines for Event Stream based Scene Text Recognition
Feb 13, 2025Mainstream Scene Text Recognition (STR) algorithms are developed based on RGB cameras which are sensitive to challenging factors such as low illumination, motion blur, and cluttered backgrounds. In this paper, we propose to recognize the scene text using bio-inspired event cameras by collecting and annotating a large-scale benchmark dataset, termed EventSTR. It contains 9,928 high-definition (1280 * 720) event samples and involves both Chinese and English characters. We also benchmark multiple STR algorithms as the baselines for future works to compare. In addition, we propose a new event-based scene text recognition framework, termed SimC-ESTR. It first extracts the event features using a visual encoder and projects them into tokens using a Q-former module. More importantly, we propose to augment the vision tokens based on a memory mechanism before feeding into the large language models. A similarity-based error correction mechanism is embedded within the large language model to correct potential minor errors fundamentally based on contextual information. Extensive experiments on the newly proposed EventSTR dataset and two simulation STR datasets fully demonstrate the effectiveness of our proposed model. We believe that the dataset and algorithmic model can innovatively propose an event-based STR task and are expected to accelerate the application of event cameras in various industries. The source code and pre-trained models will be released on https://github.com/Event-AHU/EventSTR
Spatio-temporal Graph Learning on Adaptive Mined Key Frames for High-performance Multi-Object Tracking
Jan 17, 2025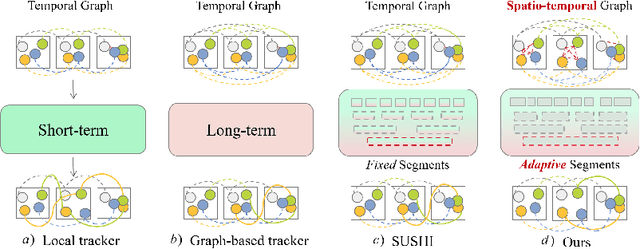
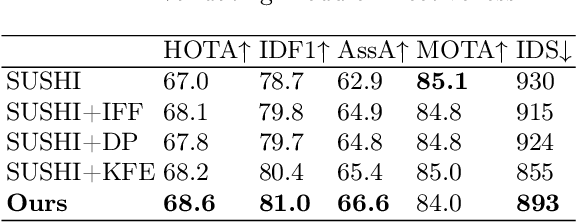

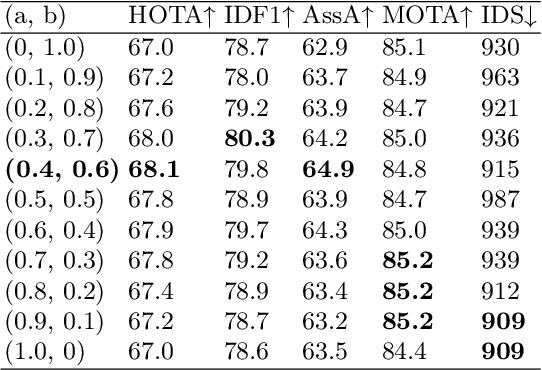
In the realm of multi-object tracking, the challenge of accurately capturing the spatial and temporal relationships between objects in video sequences remains a significant hurdle. This is further complicated by frequent occurrences of mutual occlusions among objects, which can lead to tracking errors and reduced performance in existing methods. Motivated by these challenges, we propose a novel adaptive key frame mining strategy that addresses the limitations of current tracking approaches. Specifically, we introduce a Key Frame Extraction (KFE) module that leverages reinforcement learning to adaptively segment videos, thereby guiding the tracker to exploit the intrinsic logic of the video content. This approach allows us to capture structured spatial relationships between different objects as well as the temporal relationships of objects across frames. To tackle the issue of object occlusions, we have developed an Intra-Frame Feature Fusion (IFF) module. Unlike traditional graph-based methods that primarily focus on inter-frame feature fusion, our IFF module uses a Graph Convolutional Network (GCN) to facilitate information exchange between the target and surrounding objects within a frame. This innovation significantly enhances target distinguishability and mitigates tracking loss and appearance similarity due to occlusions. By combining the strengths of both long and short trajectories and considering the spatial relationships between objects, our proposed tracker achieves impressive results on the MOT17 dataset, i.e., 68.6 HOTA, 81.0 IDF1, 66.6 AssA, and 893 IDS, proving its effectiveness and accuracy.
Spatio-Temporal Side Tuning Pre-trained Foundation Models for Video-based Pedestrian Attribute Recognition
Apr 27, 2024



Existing pedestrian attribute recognition (PAR) algorithms are mainly developed based on a static image, however, the performance is unreliable in challenging scenarios, such as heavy occlusion, motion blur, etc. In this work, we propose to understand human attributes using video frames that can fully use temporal information by fine-tuning a pre-trained multi-modal foundation model efficiently. Specifically, we formulate the video-based PAR as a vision-language fusion problem and adopt a pre-trained foundation model CLIP to extract the visual features. More importantly, we propose a novel spatiotemporal side-tuning strategy to achieve parameter-efficient optimization of the pre-trained vision foundation model. To better utilize the semantic information, we take the full attribute list that needs to be recognized as another input and transform the attribute words/phrases into the corresponding sentence via split, expand, and prompt operations. Then, the text encoder of CLIP is utilized for embedding processed attribute descriptions. The averaged visual tokens and text tokens are concatenated and fed into a fusion Transformer for multi-modal interactive learning. The enhanced tokens will be fed into a classification head for pedestrian attribute prediction. Extensive experiments on two large-scale video-based PAR datasets fully validated the effectiveness of our proposed framework. The source code of this paper is available at https://github.com/Event-AHU/OpenPAR.
Prototype-based Cross-Modal Object Tracking
Dec 22, 2023Cross-modal object tracking is an important research topic in the field of information fusion, and it aims to address imaging limitations in challenging scenarios by integrating switchable visible and near-infrared modalities. However, existing tracking methods face some difficulties in adapting to significant target appearance variations in the presence of modality switch. For instance, model update based tracking methods struggle to maintain stable tracking results during modality switching, leading to error accumulation and model drift. Template based tracking methods solely rely on the template information from first frame and/or last frame, which lacks sufficient representation ability and poses challenges in handling significant target appearance changes. To address this problem, we propose a prototype-based cross-modal object tracker called ProtoTrack, which introduces a novel prototype learning scheme to adapt to significant target appearance variations, for cross-modal object tracking. In particular, we design a multi-modal prototype to represent target information by multi-kind samples, including a fixed sample from the first frame and two representative samples from different modalities. Moreover, we develop a prototype generation algorithm based on two new modules to ensure the prototype representative in different challenges......