 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMBDRes-U-Net: Multi-Scale Lightweight Brain Tumor Segmentation Network
Nov 04, 2024
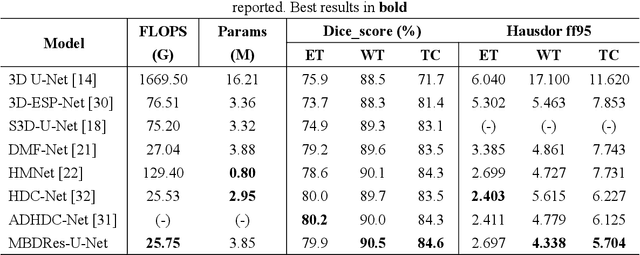
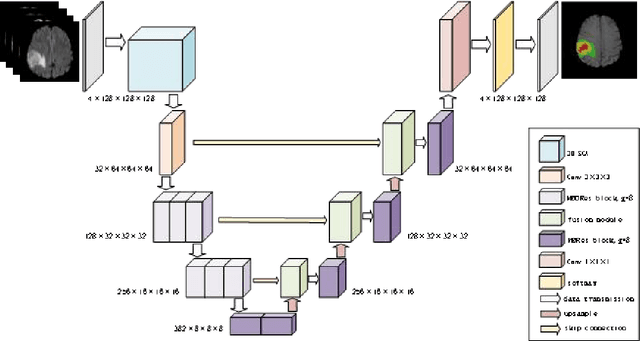
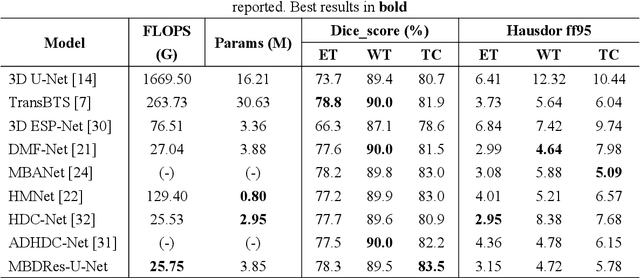
Accurate segmentation of brain tumors plays a key role in the diagnosis and treatment of brain tumor diseases. It serves as a critical technology for quantifying tumors and extracting their features. With the increasing application of deep learning methods, the computational burden has become progressively heavier. To achieve a lightweight model with good segmentation performance, this study proposes the MBDRes-U-Net model using the three-dimensional (3D) U-Net codec framework, which integrates multibranch residual blocks and fused attention into the model. The computational burden of the model is reduced by the branch strategy, which effectively uses the rich local features in multimodal images and enhances the segmentation performance of subtumor regions. Additionally, during encoding, an adaptive weighted expansion convolution layer is introduced into the multi-branch residual block, which enriches the feature expression and improves the segmentation accuracy of the model. Experiments on the Brain Tumor Segmentation (BraTS) Challenge 2018 and 2019 datasets show that the architecture could maintain a high precision of brain tumor segmentation while considerably reducing the calculation overhead.Our code is released at https://github.com/Huaibei-normal-university-cv-laboratory/mbdresunet
Prototype-based Cross-Modal Object Tracking
Dec 22, 2023Cross-modal object tracking is an important research topic in the field of information fusion, and it aims to address imaging limitations in challenging scenarios by integrating switchable visible and near-infrared modalities. However, existing tracking methods face some difficulties in adapting to significant target appearance variations in the presence of modality switch. For instance, model update based tracking methods struggle to maintain stable tracking results during modality switching, leading to error accumulation and model drift. Template based tracking methods solely rely on the template information from first frame and/or last frame, which lacks sufficient representation ability and poses challenges in handling significant target appearance changes. To address this problem, we propose a prototype-based cross-modal object tracker called ProtoTrack, which introduces a novel prototype learning scheme to adapt to significant target appearance variations, for cross-modal object tracking. In particular, we design a multi-modal prototype to represent target information by multi-kind samples, including a fixed sample from the first frame and two representative samples from different modalities. Moreover, we develop a prototype generation algorithm based on two new modules to ensure the prototype representative in different challenges......