 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDual Path Structural Contrastive Embeddings for Learning Novel Objects
Jan 04, 2022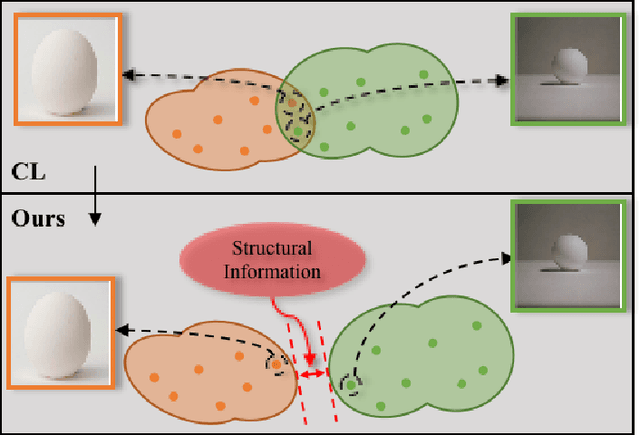
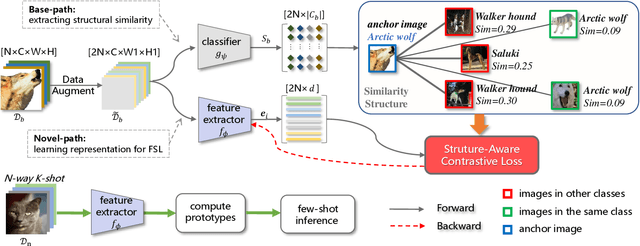
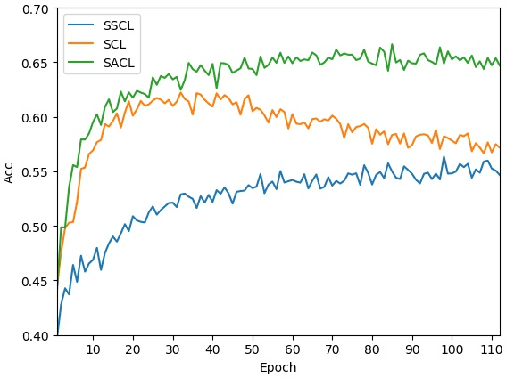

Learning novel classes from a very few labeled samples has attracted increasing attention in machine learning areas. Recent research on either meta-learning based or transfer-learning based paradigm demonstrates that gaining information on a good feature space can be an effective solution to achieve favorable performance on few-shot tasks. In this paper, we propose a simple but effective paradigm that decouples the tasks of learning feature representations and classifiers and only learns the feature embedding architecture from base classes via the typical transfer-learning training strategy. To maintain both the generalization ability across base and novel classes and discrimination ability within each class, we propose a dual path feature learning scheme that effectively combines structural similarity with contrastive feature construction. In this way, both inner-class alignment and inter-class uniformity can be well balanced, and result in improved performance. Experiments on three popular benchmarks show that when incorporated with a simple prototype based classifier, our method can still achieve promising results for both standard and generalized few-shot problems in either an inductive or transductive inference setting.
Class-Incremental Few-Shot Object Detection
May 17, 2021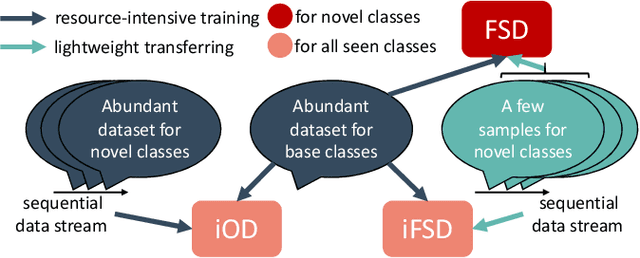
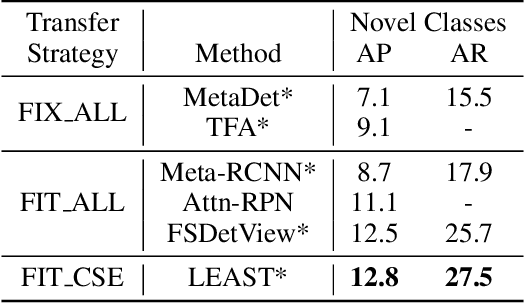
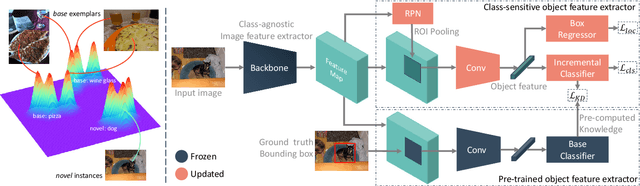
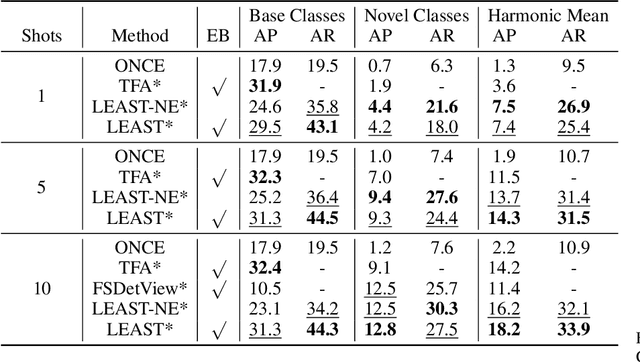
Conventional detection networks usually need abundant labeled training samples, while humans can learn new concepts incrementally with just a few examples. This paper focuses on a more challenging but realistic class-incremental few-shot object detection problem (iFSD). It aims to incrementally transfer the model for novel objects from only a few annotated samples without catastrophically forgetting the previously learned ones. To tackle this problem, we propose a novel method LEAST, which can transfer with Less forgetting, fEwer training resources, And Stronger Transfer capability. Specifically, we first present the transfer strategy to reduce unnecessary weight adaptation and improve the transfer capability for iFSD. On this basis, we then integrate the knowledge distillation technique using a less resource-consuming approach to alleviate forgetting and propose a novel clustering-based exemplar selection process to preserve more discriminative features previously learned. Being a generic and effective method, LEAST can largely improve the iFSD performance on various benchmarks.
Fine-grained Semantic Constraint in Image Synthesis
Jan 12, 2021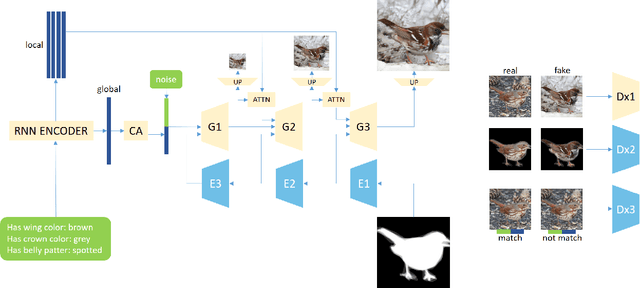
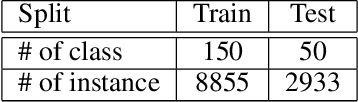
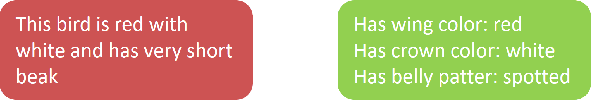

In this paper, we propose a multi-stage and high-resolution model for image synthesis that uses fine-grained attributes and masks as input. With a fine-grained attribute, the proposed model can detailedly constrain the features of the generated image through rich and fine-grained semantic information in the attribute. With mask as prior, the model in this paper is constrained so that the generated images conform to visual senses, which will reduce the unexpected diversity of samples generated from the generative adversarial network. This paper also proposes a scheme to improve the discriminator of the generative adversarial network by simultaneously discriminating the total image and sub-regions of the image. In addition, we propose a method for optimizing the labeled attribute in datasets, which reduces the manual labeling noise. Extensive quantitative results show that our image synthesis model generates more realistic images.
MGD-GAN: Text-to-Pedestrian generation through Multi-Grained Discrimination
Oct 02, 2020

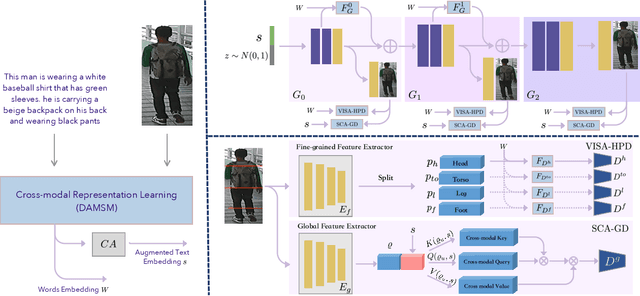

In this paper, we investigate the problem of text-to-pedestrian synthesis, which has many potential applications in art, design, and video surveillance. Existing methods for text-to-bird/flower synthesis are still far from solving this fine-grained image generation problem, due to the complex structure and heterogeneous appearance that the pedestrians naturally take on. To this end, we propose the Multi-Grained Discrimination enhanced Generative Adversarial Network, that capitalizes a human-part-based Discriminator (HPD) and a self-cross-attended (SCA) global Discriminator in order to capture the coherence of the complex body structure. A fined-grained word-level attention mechanism is employed in the HPD module to enforce diversified appearance and vivid details. In addition, two pedestrian generation metrics, named Pose Score and Pose Variance, are devised to evaluate the generation quality and diversity, respectively. We conduct extensive experiments and ablation studies on the caption-annotated pedestrian dataset, CUHK Person Description Dataset. The substantial improvement over the various metrics demonstrates the efficacy of MGD-GAN on the text-to-pedestrian synthesis scenario.
Learning Robust Features with Incremental Auto-Encoders
May 26, 2017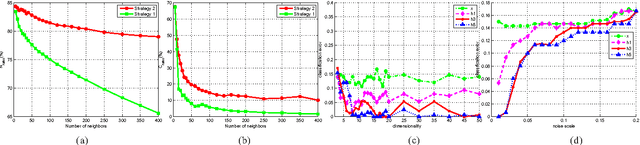
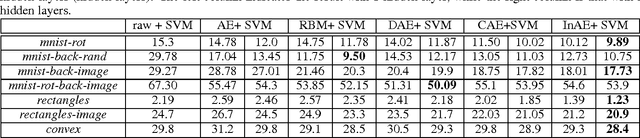
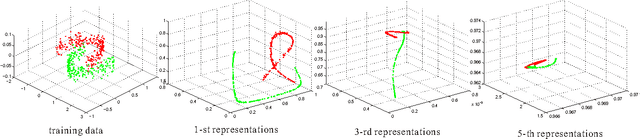
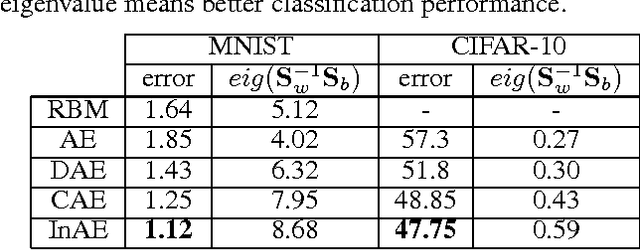
Automatically learning features, especially robust features, has attracted much attention in the machine learning community. In this paper, we propose a new method to learn non-linear robust features by taking advantage of the data manifold structure. We first follow the commonly used trick of the trade, that is learning robust features with artificially corrupted data, which are training samples with manually injected noise. Following the idea of the auto-encoder, we first assume features should contain much information to well reconstruct the input from its corrupted copies. However, merely reconstructing clean input from its noisy copies could make data manifold in the feature space noisy. To address this problem, we propose a new method, called Incremental Auto-Encoders, to iteratively denoise the extracted features. We assume the noisy manifold structure is caused by a diffusion process. Consequently, we reverse this specific diffusion process to further contract this noisy manifold, which results in an incremental optimization of model parameters . Furthermore, we show these learned non-linear features can be stacked into a hierarchy of features. Experimental results on real-world datasets demonstrate the proposed method can achieve better classification performances.
Zero-Shot Learning with Generative Latent Prototype Model
May 26, 2017



Zero-shot learning, which studies the problem of object classification for categories for which we have no training examples, is gaining increasing attention from community. Most existing ZSL methods exploit deterministic transfer learning via an in-between semantic embedding space. In this paper, we try to attack this problem from a generative probabilistic modelling perspective. We assume for any category, the observed representation, e.g. images or texts, is developed from a unique prototype in a latent space, in which the semantic relationship among prototypes is encoded via linear reconstruction. Taking advantage of this assumption, virtual instances of unseen classes can be generated from the corresponding prototype, giving rise to a novel ZSL model which can alleviate the domain shift problem existing in the way of direct transfer learning. Extensive experiments on three benchmark datasets show our proposed model can achieve state-of-the-art results.
Zero-Shot Recognition using Dual Visual-Semantic Mapping Paths
Mar 20, 2017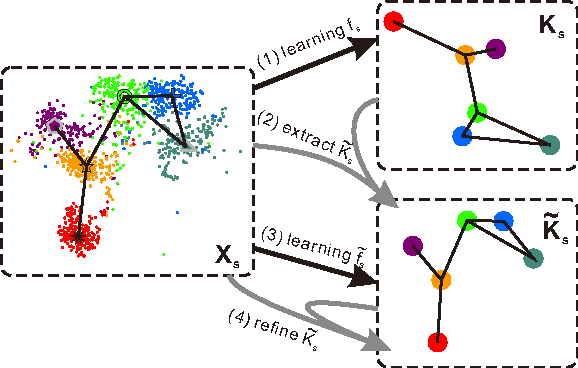
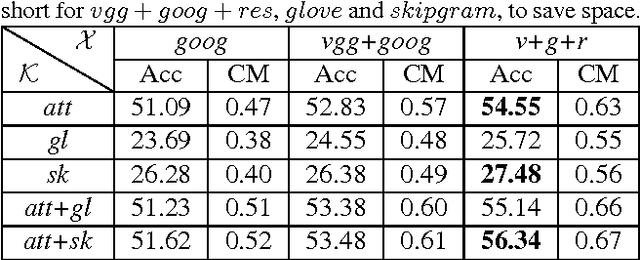
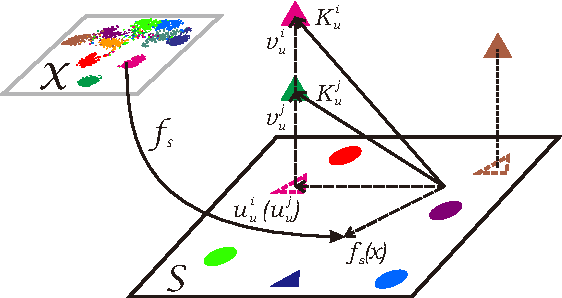
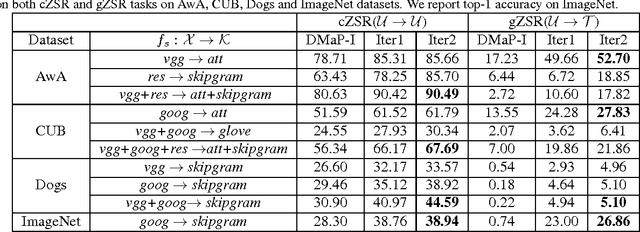
Zero-shot recognition aims to accurately recognize objects of unseen classes by using a shared visual-semantic mapping between the image feature space and the semantic embedding space. This mapping is learned on training data of seen classes and is expected to have transfer ability to unseen classes. In this paper, we tackle this problem by exploiting the intrinsic relationship between the semantic space manifold and the transfer ability of visual-semantic mapping. We formalize their connection and cast zero-shot recognition as a joint optimization problem. Motivated by this, we propose a novel framework for zero-shot recognition, which contains dual visual-semantic mapping paths. Our analysis shows this framework can not only apply prior semantic knowledge to infer underlying semantic manifold in the image feature space, but also generate optimized semantic embedding space, which can enhance the transfer ability of the visual-semantic mapping to unseen classes. The proposed method is evaluated for zero-shot recognition on four benchmark datasets, achieving outstanding results.
Task-driven Visual Saliency and Attention-based Visual Question Answering
Feb 22, 2017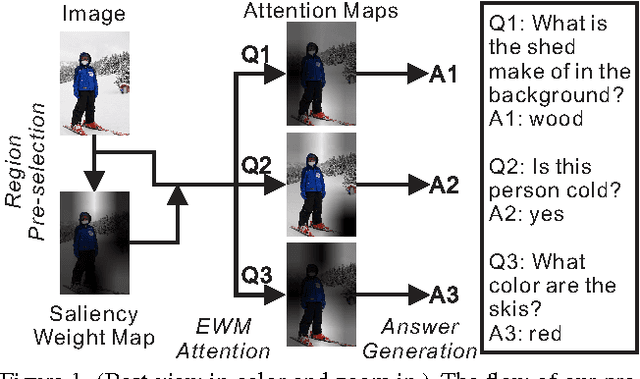
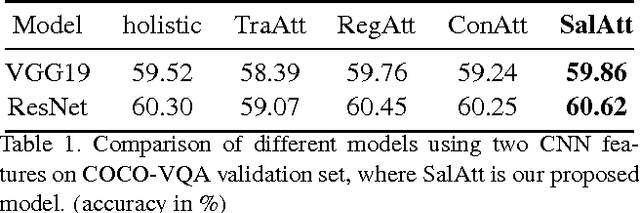
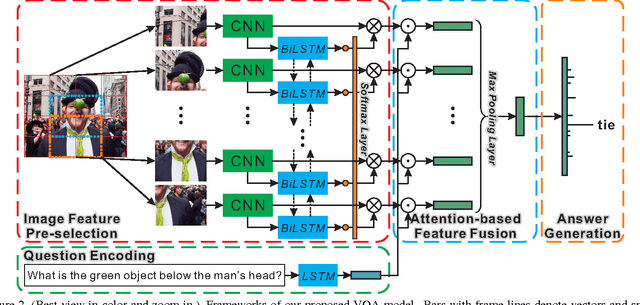
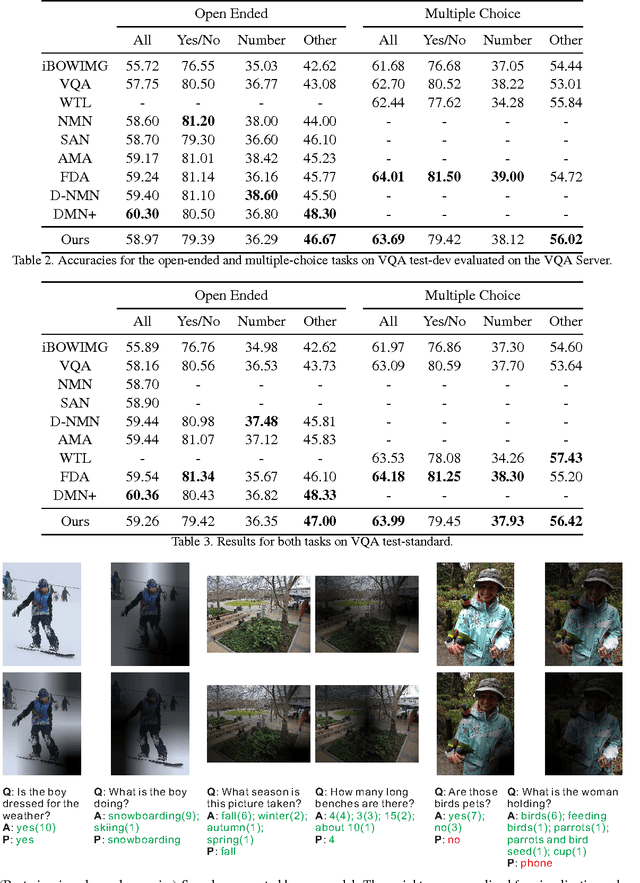
Visual question answering (VQA) has witnessed great progress since May, 2015 as a classic problem unifying visual and textual data into a system. Many enlightening VQA works explore deep into the image and question encodings and fusing methods, of which attention is the most effective and infusive mechanism. Current attention based methods focus on adequate fusion of visual and textual features, but lack the attention to where people focus to ask questions about the image. Traditional attention based methods attach a single value to the feature at each spatial location, which losses many useful information. To remedy these problems, we propose a general method to perform saliency-like pre-selection on overlapped region features by the interrelation of bidirectional LSTM (BiLSTM), and use a novel element-wise multiplication based attention method to capture more competent correlation information between visual and textual features. We conduct experiments on the large-scale COCO-VQA dataset and analyze the effectiveness of our model demonstrated by strong empirical results.
A Brief Summary of Dictionary Learning Based Approach for Classification
May 30, 2012
This note presents some representative methods which are based on dictionary learning (DL) for classification. We do not review the sophisticated methods or frameworks that involve DL for classification, such as online DL and spatial pyramid matching (SPM), but rather, we concentrate on the direct DL-based classification methods. Here, the "so-called direct DL-based method" is the approach directly deals with DL framework by adding some meaningful penalty terms. By listing some representative methods, we can roughly divide them into two categories, i.e. (1) directly making the dictionary discriminative and (2) forcing the sparse coefficients discriminative to push the discrimination power of the dictionary. From this taxonomy, we can expect some extensions of them as future researches.
Online Discriminative Dictionary Learning for Image Classification Based on Block-Coordinate Descent Method
Mar 05, 2012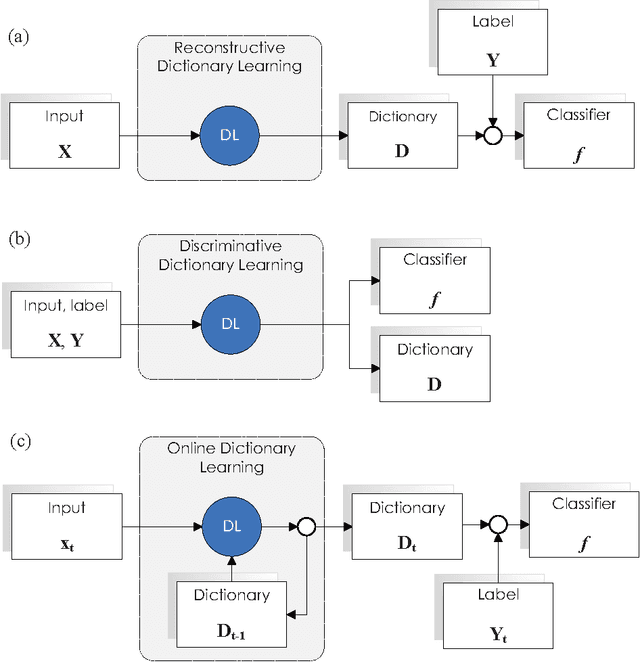
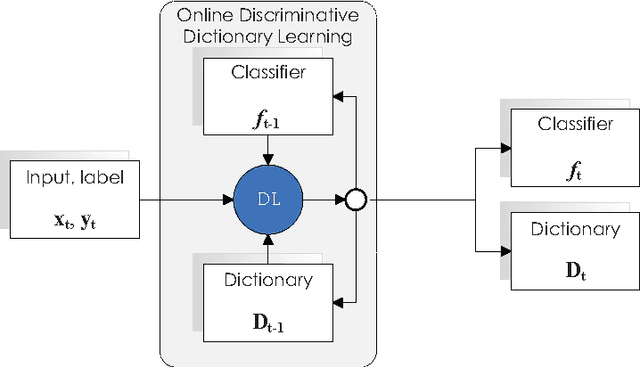
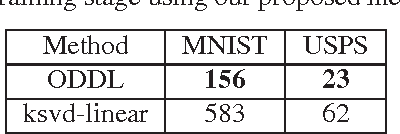

Previous researches have demonstrated that the framework of dictionary learning with sparse coding, in which signals are decomposed as linear combinations of a few atoms of a learned dictionary, is well adept to reconstruction issues. This framework has also been used for discrimination tasks such as image classification. To achieve better performances of classification, experts develop several methods to learn a discriminative dictionary in a supervised manner. However, another issue is that when the data become extremely large in scale, these methods will be no longer effective as they are all batch-oriented approaches. For this reason, we propose a novel online algorithm for discriminative dictionary learning, dubbed \textbf{ODDL} in this paper. First, we introduce a linear classifier into the conventional dictionary learning formulation and derive a discriminative dictionary learning problem. Then, we exploit an online algorithm to solve the derived problem. Unlike the most existing approaches which update dictionary and classifier alternately via iteratively solving sub-problems, our approach directly explores them jointly. Meanwhile, it can largely shorten the runtime for training and is also particularly suitable for large-scale classification issues. To evaluate the performance of the proposed ODDL approach in image recognition, we conduct some experiments on three well-known benchmarks, and the experimental results demonstrate ODDL is fairly promising for image classification tasks.