 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTask-driven Visual Saliency and Attention-based Visual Question Answering
Feb 22, 2017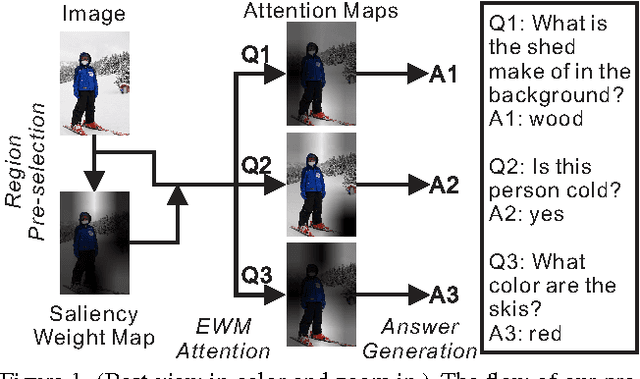
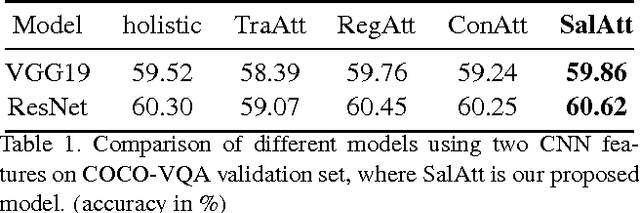
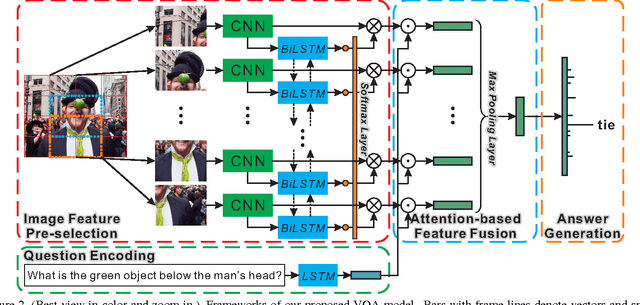
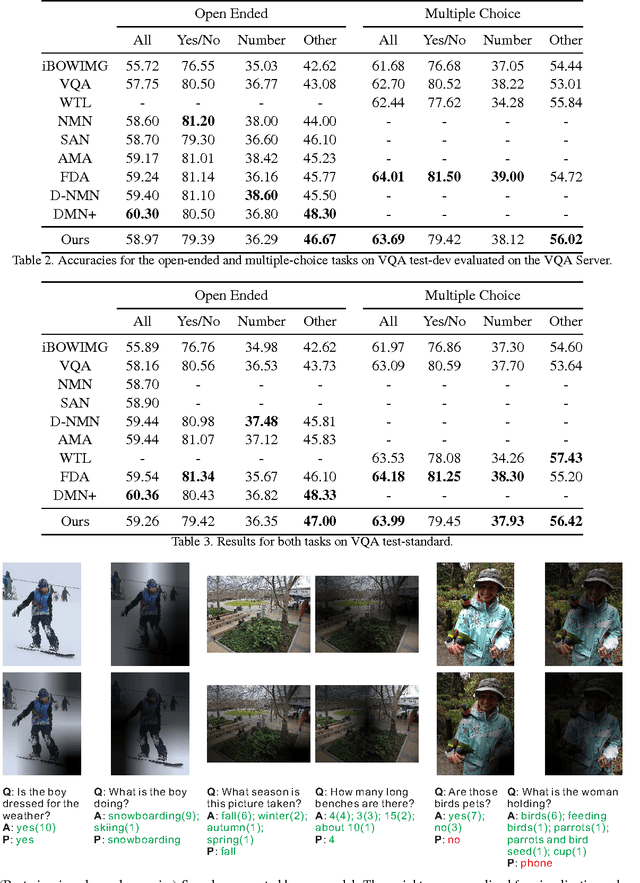
Visual question answering (VQA) has witnessed great progress since May, 2015 as a classic problem unifying visual and textual data into a system. Many enlightening VQA works explore deep into the image and question encodings and fusing methods, of which attention is the most effective and infusive mechanism. Current attention based methods focus on adequate fusion of visual and textual features, but lack the attention to where people focus to ask questions about the image. Traditional attention based methods attach a single value to the feature at each spatial location, which losses many useful information. To remedy these problems, we propose a general method to perform saliency-like pre-selection on overlapped region features by the interrelation of bidirectional LSTM (BiLSTM), and use a novel element-wise multiplication based attention method to capture more competent correlation information between visual and textual features. We conduct experiments on the large-scale COCO-VQA dataset and analyze the effectiveness of our model demonstrated by strong empirical results.