 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOmni-Video 2: Scaling MLLM-Conditioned Diffusion for Unified Video Generation and Editing
Feb 09, 2026We present Omni-Video 2, a scalable and computationally efficient model that connects pretrained multimodal large-language models (MLLMs) with video diffusion models for unified video generation and editing. Our key idea is to exploit the understanding and reasoning capabilities of MLLMs to produce explicit target captions to interpret user instructions. In this way, the rich contextual representations from the understanding model are directly used to guide the generative process, thereby improving performance on complex and compositional editing. Moreover, a lightweight adapter is developed to inject multimodal conditional tokens into pretrained text-to-video diffusion models, allowing maximum reuse of their powerful generative priors in a parameter-efficient manner. Benefiting from these designs, we scale up Omni-Video 2 to a 14B video diffusion model on meticulously curated training data with quality, supporting high quality text-to-video generation and various video editing tasks such as object removal, addition, background change, complex motion editing, \emph{etc.} We evaluate the performance of Omni-Video 2 on the FiVE benchmark for fine-grained video editing and the VBench benchmark for text-to-video generation. The results demonstrate its superior ability to follow complex compositional instructions in video editing, while also achieving competitive or superior quality in video generation tasks.
MVAR: MultiVariate AutoRegressive Air Pollutants Forecasting Model
Jul 16, 2025Air pollutants pose a significant threat to the environment and human health, thus forecasting accurate pollutant concentrations is essential for pollution warnings and policy-making. Existing studies predominantly focus on single-pollutant forecasting, neglecting the interactions among different pollutants and their diverse spatial responses. To address the practical needs of forecasting multivariate air pollutants, we propose MultiVariate AutoRegressive air pollutants forecasting model (MVAR), which reduces the dependency on long-time-window inputs and boosts the data utilization efficiency. We also design the Multivariate Autoregressive Training Paradigm, enabling MVAR to achieve 120-hour long-term sequential forecasting. Additionally, MVAR develops Meteorological Coupled Spatial Transformer block, enabling the flexible coupling of AI-based meteorological forecasts while learning the interactions among pollutants and their diverse spatial responses. As for the lack of standardized datasets in air pollutants forecasting, we construct a comprehensive dataset covering 6 major pollutants across 75 cities in North China from 2018 to 2023, including ERA5 reanalysis data and FuXi-2.0 forecast data. Experimental results demonstrate that the proposed model outperforms state-of-the-art methods and validate the effectiveness of the proposed architecture.
Zero-Shot Recognition using Dual Visual-Semantic Mapping Paths
Mar 20, 2017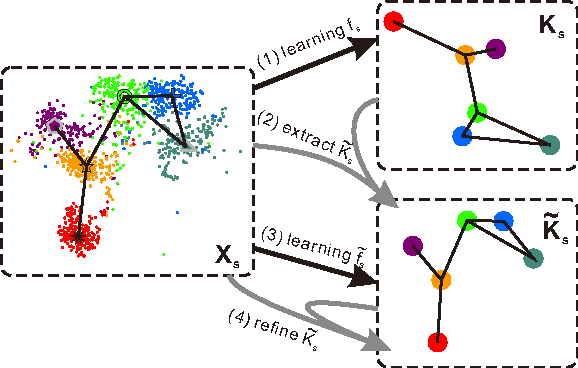
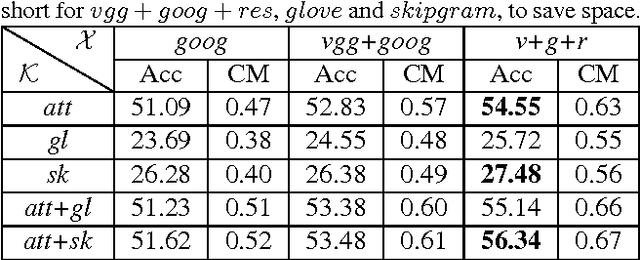
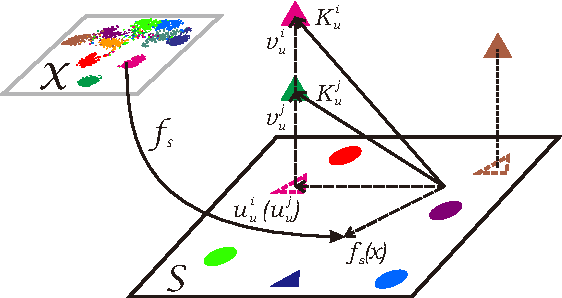
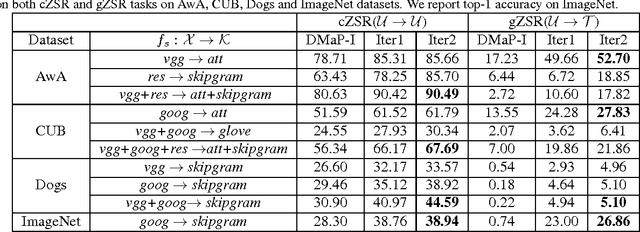
Zero-shot recognition aims to accurately recognize objects of unseen classes by using a shared visual-semantic mapping between the image feature space and the semantic embedding space. This mapping is learned on training data of seen classes and is expected to have transfer ability to unseen classes. In this paper, we tackle this problem by exploiting the intrinsic relationship between the semantic space manifold and the transfer ability of visual-semantic mapping. We formalize their connection and cast zero-shot recognition as a joint optimization problem. Motivated by this, we propose a novel framework for zero-shot recognition, which contains dual visual-semantic mapping paths. Our analysis shows this framework can not only apply prior semantic knowledge to infer underlying semantic manifold in the image feature space, but also generate optimized semantic embedding space, which can enhance the transfer ability of the visual-semantic mapping to unseen classes. The proposed method is evaluated for zero-shot recognition on four benchmark datasets, achieving outstanding results.
Task-driven Visual Saliency and Attention-based Visual Question Answering
Feb 22, 2017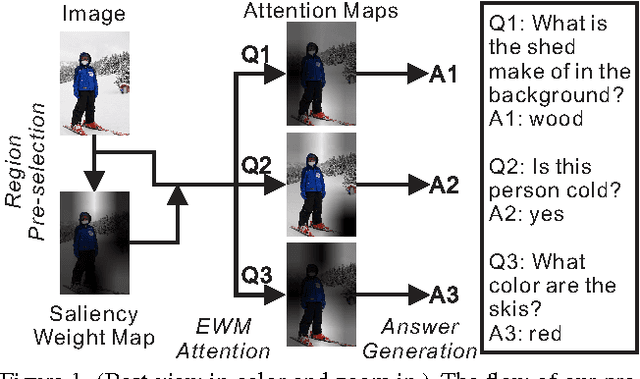
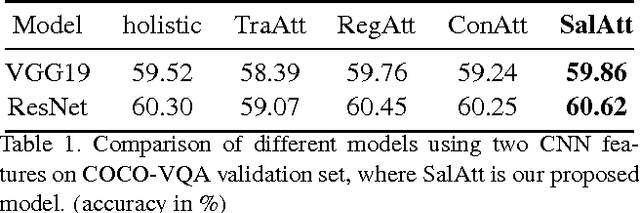
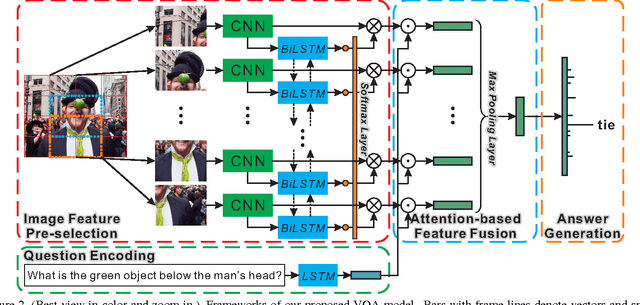
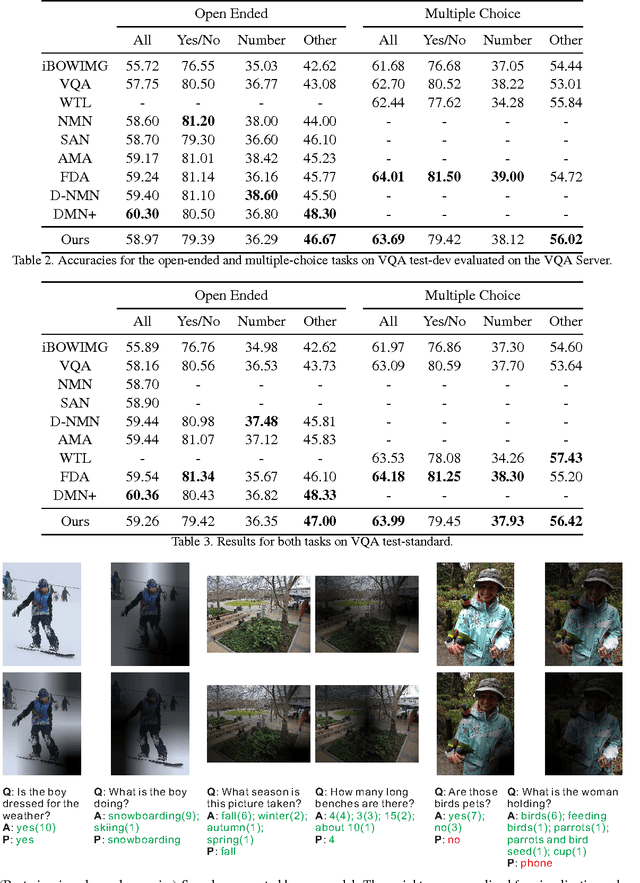
Visual question answering (VQA) has witnessed great progress since May, 2015 as a classic problem unifying visual and textual data into a system. Many enlightening VQA works explore deep into the image and question encodings and fusing methods, of which attention is the most effective and infusive mechanism. Current attention based methods focus on adequate fusion of visual and textual features, but lack the attention to where people focus to ask questions about the image. Traditional attention based methods attach a single value to the feature at each spatial location, which losses many useful information. To remedy these problems, we propose a general method to perform saliency-like pre-selection on overlapped region features by the interrelation of bidirectional LSTM (BiLSTM), and use a novel element-wise multiplication based attention method to capture more competent correlation information between visual and textual features. We conduct experiments on the large-scale COCO-VQA dataset and analyze the effectiveness of our model demonstrated by strong empirical results.