 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMGD-GAN: Text-to-Pedestrian generation through Multi-Grained Discrimination
Paper and Code


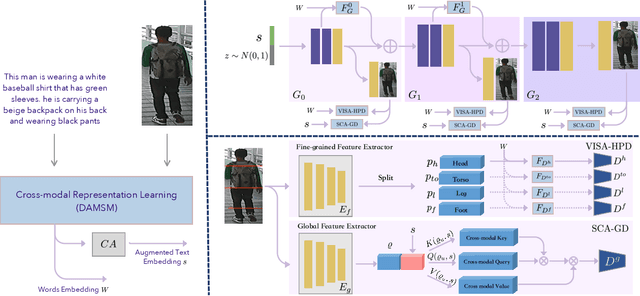

In this paper, we investigate the problem of text-to-pedestrian synthesis, which has many potential applications in art, design, and video surveillance. Existing methods for text-to-bird/flower synthesis are still far from solving this fine-grained image generation problem, due to the complex structure and heterogeneous appearance that the pedestrians naturally take on. To this end, we propose the Multi-Grained Discrimination enhanced Generative Adversarial Network, that capitalizes a human-part-based Discriminator (HPD) and a self-cross-attended (SCA) global Discriminator in order to capture the coherence of the complex body structure. A fined-grained word-level attention mechanism is employed in the HPD module to enforce diversified appearance and vivid details. In addition, two pedestrian generation metrics, named Pose Score and Pose Variance, are devised to evaluate the generation quality and diversity, respectively. We conduct extensive experiments and ablation studies on the caption-annotated pedestrian dataset, CUHK Person Description Dataset. The substantial improvement over the various metrics demonstrates the efficacy of MGD-GAN on the text-to-pedestrian synthesis scenario.