 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJointly Optimizing Debiased CTR and Uplift for Coupons Marketing: A Unified Causal Framework
Feb 13, 2026In online advertising, marketing interventions such as coupons introduce significant confounding bias into Click-Through Rate (CTR) prediction. Observed clicks reflect a mixture of users' intrinsic preferences and the uplift induced by these interventions. This causes conventional models to miscalibrate base CTRs, which distorts downstream ranking and billing decisions. Furthermore, marketing interventions often operate as multi-valued treatments with varying magnitudes, introducing additional complexity to CTR prediction. To address these issues, we propose the \textbf{Uni}fied \textbf{M}ulti-\textbf{V}alued \textbf{T}reatment Network (UniMVT). Specifically, UniMVT disentangles confounding factors from treatment-sensitive representations, enabling a full-space counterfactual inference module to jointly reconstruct the debiased base CTR and intensity-response curves. To handle the complexity of multi-valued treatments, UniMVT employs an auxiliary intensity estimation task to capture treatment propensities and devise a unit uplift objective that normalizes the intervention effect. This ensures comparable estimation across the continuous coupon-value spectrum. UniMVT simultaneously achieves debiased CTR prediction for accurate system calibration and precise uplift estimation for incentive allocation. Extensive experiments on synthetic and industrial datasets demonstrate UniMVT's superiority in both predictive accuracy and calibration. Furthermore, real-world A/B tests confirm that UniMVT significantly improves business metrics through more effective coupon distribution.
Treatment Effects Estimation on Networked Observational Data using Disentangled Variational Graph Autoencoder
Dec 19, 2024



Estimating individual treatment effect (ITE) from observational data has gained increasing attention across various domains, with a key challenge being the identification of latent confounders affecting both treatment and outcome. Networked observational data offer new opportunities to address this issue by utilizing network information to infer latent confounders. However, most existing approaches assume observed variables and network information serve only as proxy variables for latent confounders, which often fails in practice, as some variables influence treatment but not outcomes, and vice versa. Recent advances in disentangled representation learning, which disentangle latent factors into instrumental, confounding, and adjustment factors, have shown promise for ITE estimation. Building on this, we propose a novel disentangled variational graph autoencoder that learns disentangled factors for treatment effect estimation on networked observational data. Our graph encoder further ensures factor independence using the Hilbert-Schmidt Independence Criterion. Extensive experiments on two semi-synthetic datasets derived from real-world social networks and one synthetic dataset demonstrate that our method achieves state-of-the-art performance.
Explainable AI Integrated Feature Engineering for Wildfire Prediction
Apr 01, 2024Wildfires present intricate challenges for prediction, necessitating the use of sophisticated machine learning techniques for effective modeling\cite{jain2020review}. In our research, we conducted a thorough assessment of various machine learning algorithms for both classification and regression tasks relevant to predicting wildfires. We found that for classifying different types or stages of wildfires, the XGBoost model outperformed others in terms of accuracy and robustness. Meanwhile, the Random Forest regression model showed superior results in predicting the extent of wildfire-affected areas, excelling in both prediction error and explained variance. Additionally, we developed a hybrid neural network model that integrates numerical data and image information for simultaneous classification and regression. To gain deeper insights into the decision-making processes of these models and identify key contributing features, we utilized eXplainable Artificial Intelligence (XAI) techniques, including TreeSHAP, LIME, Partial Dependence Plots (PDP), and Gradient-weighted Class Activation Mapping (Grad-CAM). These interpretability tools shed light on the significance and interplay of various features, highlighting the complex factors influencing wildfire predictions. Our study not only demonstrates the effectiveness of specific machine learning models in wildfire-related tasks but also underscores the critical role of model transparency and interpretability in environmental science applications.
Learning Network Representations with Disentangled Graph Auto-Encoder
Feb 02, 2024



The (variational) graph auto-encoder is extensively employed for learning representations of graph-structured data. However, the formation of real-world graphs is a complex and heterogeneous process influenced by latent factors. Existing encoders are fundamentally holistic, neglecting the entanglement of latent factors. This not only makes graph analysis tasks less effective but also makes it harder to understand and explain the representations. Learning disentangled graph representations with (variational) graph auto-encoder poses significant challenges, and remains largely unexplored in the existing literature. In this article, we introduce the Disentangled Graph Auto-Encoder (DGA) and Disentangled Variational Graph Auto-Encoder (DVGA), approaches that leverage generative models to learn disentangled representations. Specifically, we first design a disentangled graph convolutional network with multi-channel message-passing layers, as the encoder aggregating information related to each disentangled latent factor. Subsequently, a component-wise flow is applied to each channel to enhance the expressive capabilities of disentangled variational graph auto-encoder. Additionally, we design a factor-wise decoder, considering the characteristics of disentangled representations. In order to further enhance the independence among representations, we introduce independence constraints on mapping channels for different latent factors. Empirical experiments on both synthetic and real-world datasets show the superiority of our proposed method compared to several state-of-the-art baselines.
Human Emotion Recognition Based On Galvanic Skin Response signal Feature Selection and SVM
Jul 04, 2023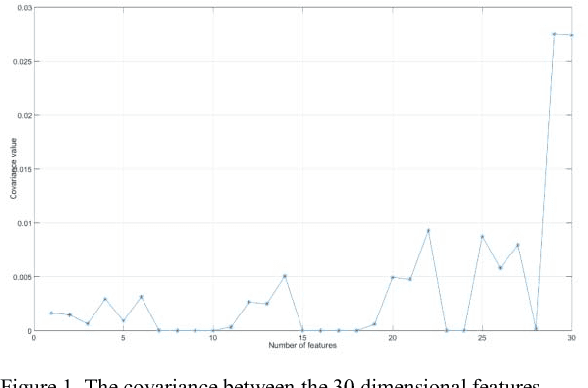
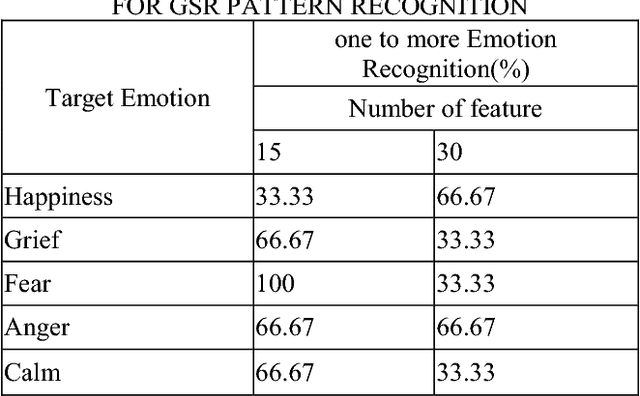
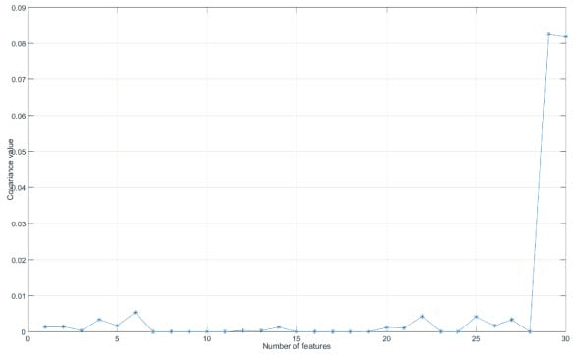
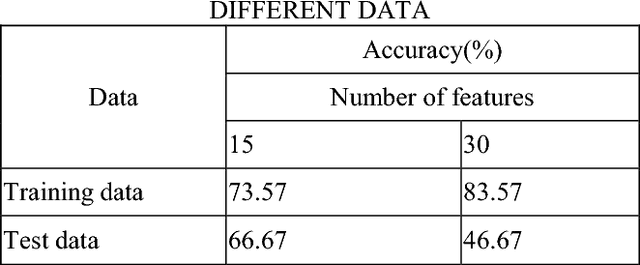
A novel human emotion recognition method based on automatically selected Galvanic Skin Response (GSR) signal features and SVM is proposed in this paper. GSR signals were acquired by e-Health Sensor Platform V2.0. Then, the data is de-noised by wavelet function and normalized to get rid of the individual difference. 30 features are extracted from the normalized data, however, directly using of these features will lead to a low recognition rate. In order to gain the optimized features, a covariance based feature selection is employed in our method. Finally, a SVM with input of the optimized features is utilized to achieve the human emotion recognition. The experimental results indicate that the proposed method leads to good human emotion recognition, and the recognition accuracy is more than 66.67%.
CF-VAE: Causal Disentangled Representation Learning with VAE and Causal Flows
Apr 19, 2023Learning disentangled representations is important in representation learning, aiming to learn a low dimensional representation of data where each dimension corresponds to one underlying generative factor. Due to the possibility of causal relationships between generative factors, causal disentangled representation learning has received widespread attention. In this paper, we first propose new flows that can incorporate causal structure information into the model, called causal flows. Based on the variational autoencoders(VAE) commonly used in disentangled representation learning, we design a new model, CF-VAE, which enhances the disentanglement ability of the VAE encoder by utilizing the causal flows. By further introducing the supervision of ground-truth factors, we demonstrate the disentanglement identifiability of our model. Experimental results on both synthetic and real datasets show that CF-VAE can achieve causal disentanglement and perform intervention experiments. Moreover, CF-VAE exhibits outstanding performance on downstream tasks and has the potential to learn causal structure among factors.
Domain Knowledge integrated for Blast Furnace Classifier Design
Mar 31, 2023Blast furnace modeling and control is one of the important problems in the industrial field, and the black-box model is an effective mean to describe the complex blast furnace system. In practice, there are often different learning targets, such as safety and energy saving in industrial applications, depending on the application. For this reason, this paper proposes a framework to design a domain knowledge integrated classification model that yields a classifier for industrial application. Our knowledge incorporated learning scheme allows the users to create a classifier that identifies "important samples" (whose misclassifications can lead to severe consequences) more correctly, while keeping the proper precision of classifying the remaining samples. The effectiveness of the proposed method has been verified by two real blast furnace datasets, which guides the operators to utilize their prior experience for controlling the blast furnace systems better.
Biomedical image analysis competitions: The state of current participation practice
Dec 16, 2022The number of international benchmarking competitions is steadily increasing in various fields of machine learning (ML) research and practice. So far, however, little is known about the common practice as well as bottlenecks faced by the community in tackling the research questions posed. To shed light on the status quo of algorithm development in the specific field of biomedical imaging analysis, we designed an international survey that was issued to all participants of challenges conducted in conjunction with the IEEE ISBI 2021 and MICCAI 2021 conferences (80 competitions in total). The survey covered participants' expertise and working environments, their chosen strategies, as well as algorithm characteristics. A median of 72% challenge participants took part in the survey. According to our results, knowledge exchange was the primary incentive (70%) for participation, while the reception of prize money played only a minor role (16%). While a median of 80 working hours was spent on method development, a large portion of participants stated that they did not have enough time for method development (32%). 25% perceived the infrastructure to be a bottleneck. Overall, 94% of all solutions were deep learning-based. Of these, 84% were based on standard architectures. 43% of the respondents reported that the data samples (e.g., images) were too large to be processed at once. This was most commonly addressed by patch-based training (69%), downsampling (37%), and solving 3D analysis tasks as a series of 2D tasks. K-fold cross-validation on the training set was performed by only 37% of the participants and only 50% of the participants performed ensembling based on multiple identical models (61%) or heterogeneous models (39%). 48% of the respondents applied postprocessing steps.
GPU-Net: Lightweight U-Net with more diverse features
Jan 07, 2022



Image segmentation is an important task in the medical image field and many convolutional neural networks (CNNs) based methods have been proposed, among which U-Net and its variants show promising performance. In this paper, we propose GP-module and GPU-Net based on U-Net, which can learn more diverse features by introducing Ghost module and atrous spatial pyramid pooling (ASPP). Our method achieves better performance with more than 4 times fewer parameters and 2 times fewer FLOPs, which provides a new potential direction for future research. Our plug-and-play module can also be applied to existing segmentation methods to further improve their performance.
On the Fairness of Swarm Learning in Skin Lesion Classification
Sep 24, 2021



in healthcare. However, the existing AI model may be biased in its decision marking. The bias induced by data itself, such as collecting data in subgroups only, can be mitigated by including more diversified data. Distributed and collaborative learning is an approach to involve training models in massive, heterogeneous, and distributed data sources, also known as nodes. In this work, we target on examining the fairness issue in Swarm Learning (SL), a recent edge-computing based decentralized machine learning approach, which is designed for heterogeneous illnesses detection in precision medicine. SL has achieved high performance in clinical applications, but no attempt has been made to evaluate if SL can improve fairness. To address the problem, we present an empirical study by comparing the fairness among single (node) training, SL, centralized training. Specifically, we evaluate on large public available skin lesion dataset, which contains samples from various subgroups. The experiments demonstrate that SL does not exacerbate the fairness problem compared to centralized training and improves both performance and fairness compared to single training. However, there still exists biases in SL model and the implementation of SL is more complex than the alternative two strategies.