 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTreatment Effects Estimation on Networked Observational Data using Disentangled Variational Graph Autoencoder
Dec 19, 2024



Estimating individual treatment effect (ITE) from observational data has gained increasing attention across various domains, with a key challenge being the identification of latent confounders affecting both treatment and outcome. Networked observational data offer new opportunities to address this issue by utilizing network information to infer latent confounders. However, most existing approaches assume observed variables and network information serve only as proxy variables for latent confounders, which often fails in practice, as some variables influence treatment but not outcomes, and vice versa. Recent advances in disentangled representation learning, which disentangle latent factors into instrumental, confounding, and adjustment factors, have shown promise for ITE estimation. Building on this, we propose a novel disentangled variational graph autoencoder that learns disentangled factors for treatment effect estimation on networked observational data. Our graph encoder further ensures factor independence using the Hilbert-Schmidt Independence Criterion. Extensive experiments on two semi-synthetic datasets derived from real-world social networks and one synthetic dataset demonstrate that our method achieves state-of-the-art performance.
Learning Network Representations with Disentangled Graph Auto-Encoder
Feb 02, 2024



The (variational) graph auto-encoder is extensively employed for learning representations of graph-structured data. However, the formation of real-world graphs is a complex and heterogeneous process influenced by latent factors. Existing encoders are fundamentally holistic, neglecting the entanglement of latent factors. This not only makes graph analysis tasks less effective but also makes it harder to understand and explain the representations. Learning disentangled graph representations with (variational) graph auto-encoder poses significant challenges, and remains largely unexplored in the existing literature. In this article, we introduce the Disentangled Graph Auto-Encoder (DGA) and Disentangled Variational Graph Auto-Encoder (DVGA), approaches that leverage generative models to learn disentangled representations. Specifically, we first design a disentangled graph convolutional network with multi-channel message-passing layers, as the encoder aggregating information related to each disentangled latent factor. Subsequently, a component-wise flow is applied to each channel to enhance the expressive capabilities of disentangled variational graph auto-encoder. Additionally, we design a factor-wise decoder, considering the characteristics of disentangled representations. In order to further enhance the independence among representations, we introduce independence constraints on mapping channels for different latent factors. Empirical experiments on both synthetic and real-world datasets show the superiority of our proposed method compared to several state-of-the-art baselines.
Automatic Implementation of Neural Networks through Reaction Networks -- Part I: Circuit Design and Convergence Analysis
Nov 30, 2023



Information processing relying on biochemical interactions in the cellular environment is essential for biological organisms. The implementation of molecular computational systems holds significant interest and potential in the fields of synthetic biology and molecular computation. This two-part article aims to introduce a programmable biochemical reaction network (BCRN) system endowed with mass action kinetics that realizes the fully connected neural network (FCNN) and has the potential to act automatically in vivo. In part I, the feedforward propagation computation, the backpropagation component, and all bridging processes of FCNN are ingeniously designed as specific BCRN modules based on their dynamics. This approach addresses a design gap in the biochemical assignment module and judgment termination module and provides a novel precise and robust realization of bi-molecular reactions for the learning process. Through equilibrium approaching, we demonstrate that the designed BCRN system achieves FCNN functionality with exponential convergence to target computational results, thereby enhancing the theoretical support for such work. Finally, the performance of this construction is further evaluated on two typical logic classification problems.
Causal Structure Learning by Using Intersection of Markov Blankets
Jul 01, 2023



In this paper, we introduce a novel causal structure learning algorithm called Endogenous and Exogenous Markov Blankets Intersection (EEMBI), which combines the properties of Bayesian networks and Structural Causal Models (SCM). Furthermore, we propose an extended version of EEMBI, namely EEMBI-PC, which integrates the last step of the PC algorithm into EEMBI.
CF-VAE: Causal Disentangled Representation Learning with VAE and Causal Flows
Apr 19, 2023Learning disentangled representations is important in representation learning, aiming to learn a low dimensional representation of data where each dimension corresponds to one underlying generative factor. Due to the possibility of causal relationships between generative factors, causal disentangled representation learning has received widespread attention. In this paper, we first propose new flows that can incorporate causal structure information into the model, called causal flows. Based on the variational autoencoders(VAE) commonly used in disentangled representation learning, we design a new model, CF-VAE, which enhances the disentanglement ability of the VAE encoder by utilizing the causal flows. By further introducing the supervision of ground-truth factors, we demonstrate the disentanglement identifiability of our model. Experimental results on both synthetic and real datasets show that CF-VAE can achieve causal disentanglement and perform intervention experiments. Moreover, CF-VAE exhibits outstanding performance on downstream tasks and has the potential to learn causal structure among factors.
Domain Knowledge integrated for Blast Furnace Classifier Design
Mar 31, 2023Blast furnace modeling and control is one of the important problems in the industrial field, and the black-box model is an effective mean to describe the complex blast furnace system. In practice, there are often different learning targets, such as safety and energy saving in industrial applications, depending on the application. For this reason, this paper proposes a framework to design a domain knowledge integrated classification model that yields a classifier for industrial application. Our knowledge incorporated learning scheme allows the users to create a classifier that identifies "important samples" (whose misclassifications can lead to severe consequences) more correctly, while keeping the proper precision of classifying the remaining samples. The effectiveness of the proposed method has been verified by two real blast furnace datasets, which guides the operators to utilize their prior experience for controlling the blast furnace systems better.
An adaptive dimension reduction algorithm for latent variables of variational autoencoder
Nov 23, 2021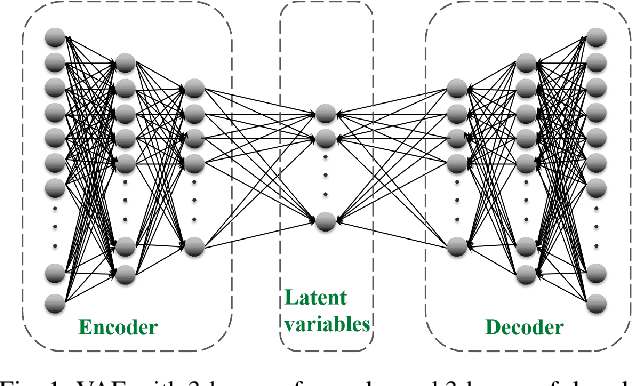
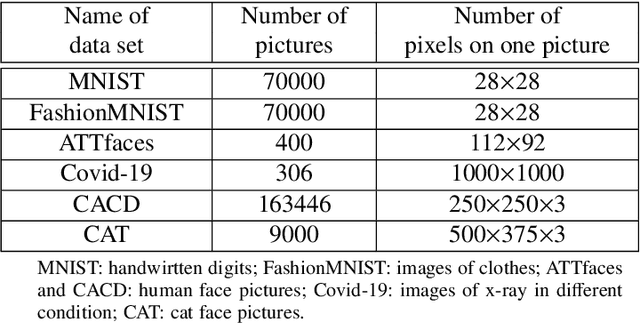

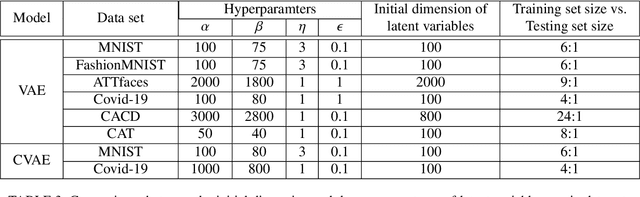
Constructed by the neural network, variational autoencoder has the overfitting problem caused by setting too many neural units, we develop an adaptive dimension reduction algorithm that can automatically learn the dimension of latent variable vector, moreover, the dimension of every hidden layer. This approach not only apply to the variational autoencoder but also other variants like Conditional VAE(CVAE), and we show the empirical results on six data sets which presents the universality and efficiency of this algorithm. The key advantages of this algorithm is that it can converge the dimension of latent variable vector which approximates the dimension reaches minimum loss of variational autoencoder(VAE), also speeds up the generating and computing speed by reducing the neural units.
Transfer Learning in Information Criteria-based Feature Selection
Jul 06, 2021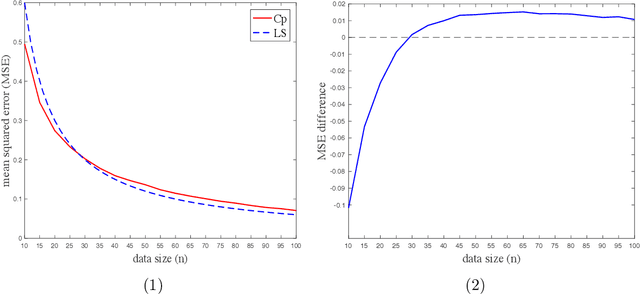
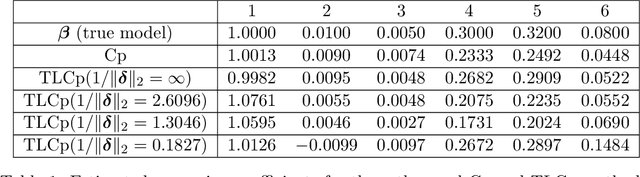
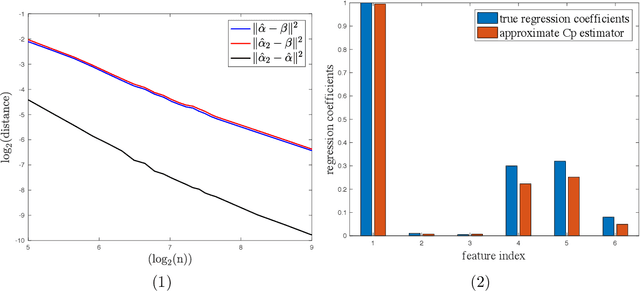
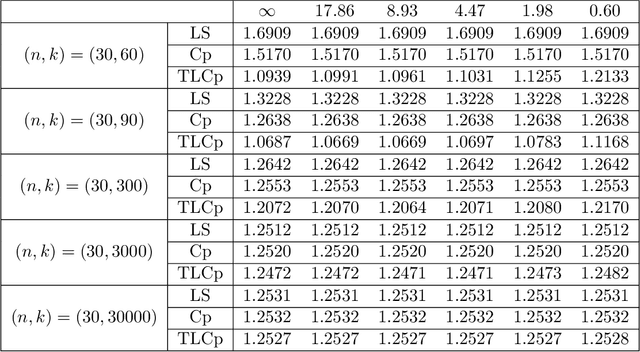
This paper investigates the effectiveness of transfer learning based on Mallows' Cp. We propose a procedure that combines transfer learning with Mallows' Cp (TLCp) and prove that it outperforms the conventional Mallows' Cp criterion in terms of accuracy and stability. Our theoretical results indicate that, for any sample size in the target domain, the proposed TLCp estimator performs better than the Cp estimator by the mean squared error (MSE) metric in the case of orthogonal predictors, provided that i) the dissimilarity between the tasks from source domain and target domain is small, and ii) the procedure parameters (complexity penalties) are tuned according to certain explicit rules. Moreover, we show that our transfer learning framework can be extended to other feature selection criteria, such as the Bayesian information criterion. By analyzing the solution of the orthogonalized Cp, we identify an estimator that asymptotically approximates the solution of the Cp criterion in the case of non-orthogonal predictors. Similar results are obtained for the non-orthogonal TLCp. Finally, simulation studies and applications with real data demonstrate the usefulness of the TLCp scheme.
Online Interaction Detection for Click-Through Rate Prediction
Jun 27, 2021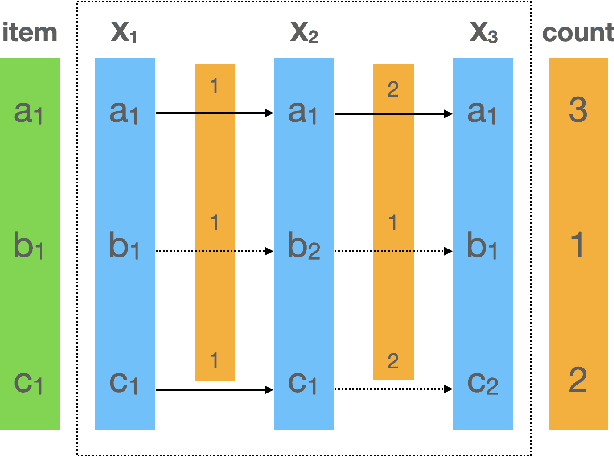
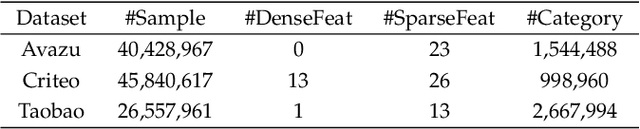
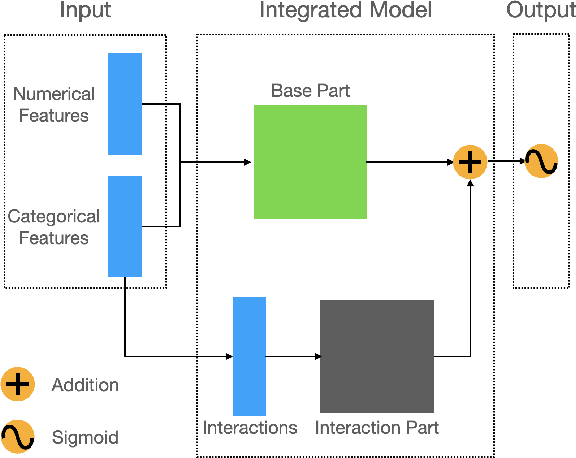
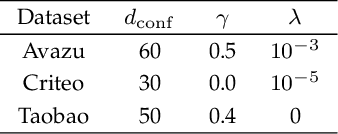
Click-Through Rate prediction aims to predict the ratio of clicks to impressions of a specific link. This is a challenging task since (1) there are usually categorical features, and the inputs will be extremely high-dimensional if one-hot encoding is applied, (2) not only the original features but also their interactions are important, (3) an effective prediction may rely on different features and interactions in different time periods. To overcome these difficulties, we propose a new interaction detection method, named Online Random Intersection Chains. The method, which is based on the idea of frequent itemset mining, detects informative interactions by observing the intersections of randomly chosen samples. The discovered interactions enjoy high interpretability as they can be comprehended as logical expressions. ORIC can be updated every time new data is collected, without being retrained on historical data. What's more, the importance of the historical and latest data can be controlled by a tuning parameter. A framework is designed to deal with the streaming interactions, so almost all existing models for CTR prediction can be applied after interaction detection. Empirical results demonstrate the efficiency and effectiveness of ORIC on three benchmark datasets.
Discovering Categorical Main and Interaction Effects Based on Association Rule Mining
Apr 10, 2021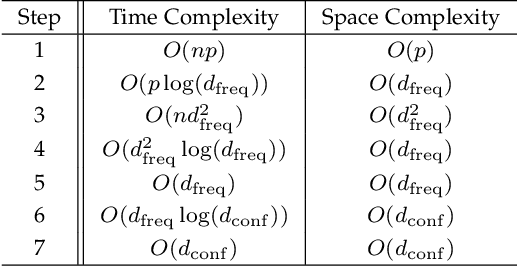
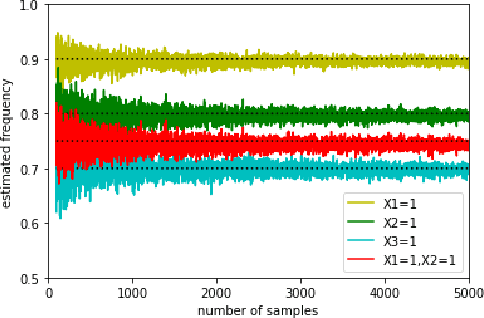
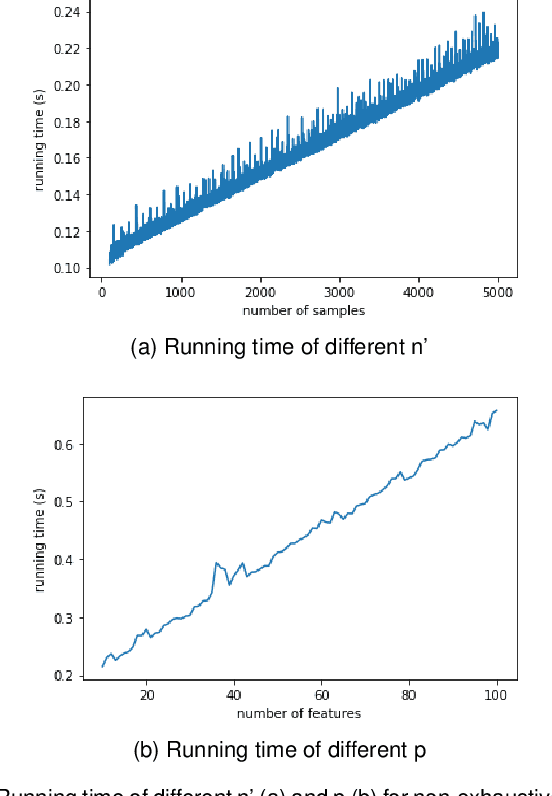

With the growing size of data sets, feature selection becomes increasingly important. Taking interactions of original features into consideration will lead to extremely high dimension, especially when the features are categorical and one-hot encoding is applied. This makes it more worthwhile mining useful features as well as their interactions. Association rule mining aims to extract interesting correlations between items, but it is difficult to use rules as a qualified classifier themselves. Drawing inspiration from association rule mining, we come up with a method that uses association rules to select features and their interactions, then modify the algorithm for several practical concerns. We analyze the computational complexity of the proposed algorithm to show its efficiency. And the results of a series of experiments verify the effectiveness of the algorithm.