 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransfer Learning in Information Criteria-based Feature Selection
Jul 06, 2021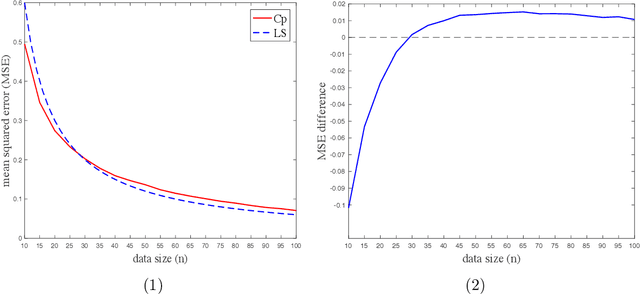
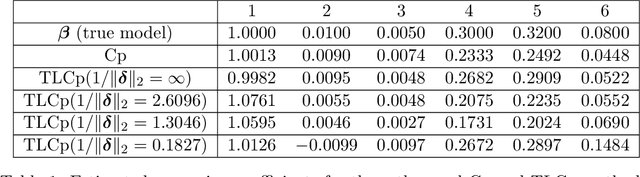
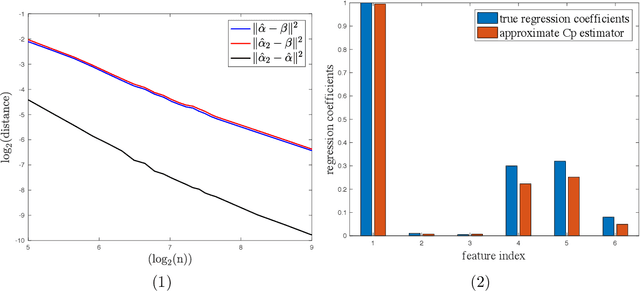
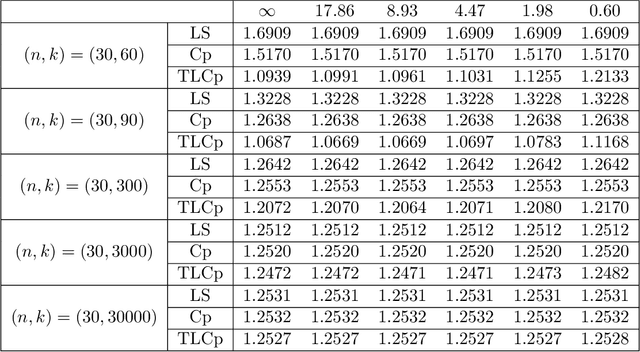
This paper investigates the effectiveness of transfer learning based on Mallows' Cp. We propose a procedure that combines transfer learning with Mallows' Cp (TLCp) and prove that it outperforms the conventional Mallows' Cp criterion in terms of accuracy and stability. Our theoretical results indicate that, for any sample size in the target domain, the proposed TLCp estimator performs better than the Cp estimator by the mean squared error (MSE) metric in the case of orthogonal predictors, provided that i) the dissimilarity between the tasks from source domain and target domain is small, and ii) the procedure parameters (complexity penalties) are tuned according to certain explicit rules. Moreover, we show that our transfer learning framework can be extended to other feature selection criteria, such as the Bayesian information criterion. By analyzing the solution of the orthogonalized Cp, we identify an estimator that asymptotically approximates the solution of the Cp criterion in the case of non-orthogonal predictors. Similar results are obtained for the non-orthogonal TLCp. Finally, simulation studies and applications with real data demonstrate the usefulness of the TLCp scheme.
A Discussion on Practical Considerations with Sparse Regression Methodologies
Nov 18, 2020



Sparse linear regression is a vast field and there are many different algorithms available to build models. Two new papers published in Statistical Science study the comparative performance of several sparse regression methodologies, including the lasso and subset selection. Comprehensive empirical analyses allow the researchers to demonstrate the relative merits of each estimator and provide guidance to practitioners. In this discussion, we summarize and compare the two studies and we examine points of agreement and divergence, aiming to provide clarity and value to users. The authors have started a highly constructive dialogue, our goal is to continue it.
* 12 pages
OR-Gym: A Reinforcement Learning Library for Operations Research Problem
Aug 14, 2020
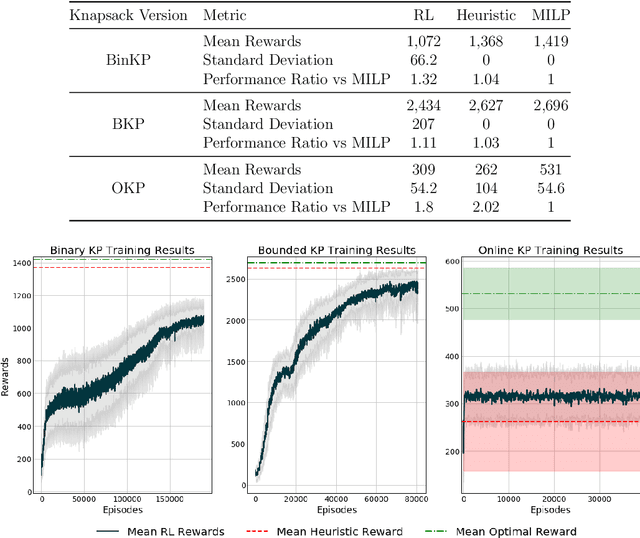


Reinforcement learning (RL) has been widely applied to game-playing and surpassed the best human-level performance in many domains, yet there are few use-cases in industrial or commercial settings. We introduce OR-Gym, an open-source library for developing reinforcement learning algorithms to address operations research problems. In this paper, we apply reinforcement learning to the knapsack, multi-dimensional bin packing, multi-echelon supply chain, and multi-period asset allocation model problems, as well as benchmark the RL solutions against MILP and heuristic models. These problems are used in logistics, finance, engineering, and are common in many business operation settings. We develop environments based on prototypical models in the literature and implement various optimization and heuristic models in order to benchmark the RL results. By re-framing a series of classic optimization problems as RL tasks, we seek to provide a new tool for the operations research community, while also opening those in the RL community to many of the problems and challenges in the OR field.
The ALAMO approach to machine learning
May 31, 2017

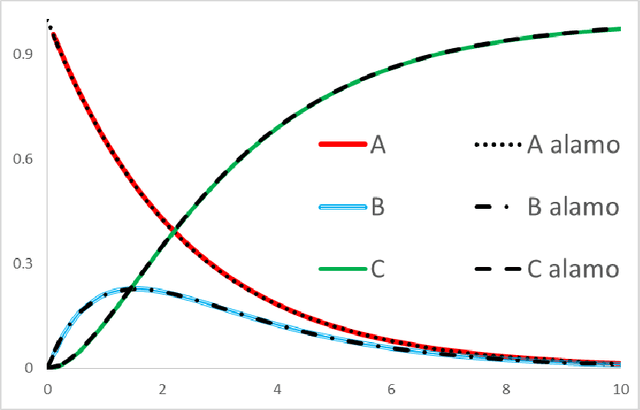

ALAMO is a computational methodology for leaning algebraic functions from data. Given a data set, the approach begins by building a low-complexity, linear model composed of explicit non-linear transformations of the independent variables. Linear combinations of these non-linear transformations allow a linear model to better approximate complex behavior observed in real processes. The model is refined, as additional data are obtained in an adaptive fashion through error maximization sampling using derivative-free optimization. Models built using ALAMO can enforce constraints on the response variables to incorporate first-principles knowledge. The ability of ALAMO to generate simple and accurate models for a number of reaction problems is demonstrated. The error maximization sampling is compared with Latin hypercube designs to demonstrate its sampling efficiency. ALAMO's constrained regression methodology is used to further refine concentration models, resulting in models that perform better on validation data and satisfy upper and lower bounds placed on model outputs.