 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOnline Interaction Detection for Click-Through Rate Prediction
Jun 27, 2021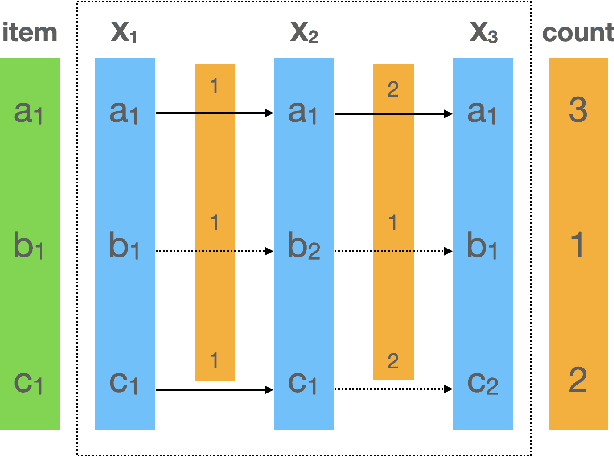
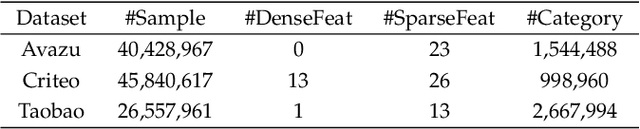
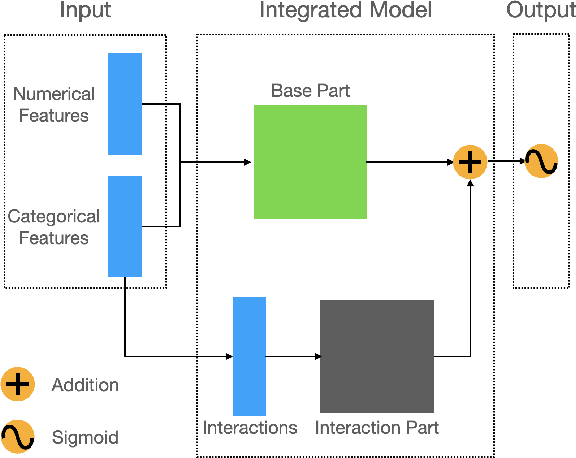
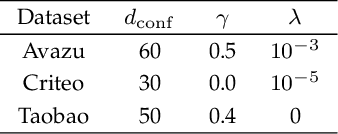
Click-Through Rate prediction aims to predict the ratio of clicks to impressions of a specific link. This is a challenging task since (1) there are usually categorical features, and the inputs will be extremely high-dimensional if one-hot encoding is applied, (2) not only the original features but also their interactions are important, (3) an effective prediction may rely on different features and interactions in different time periods. To overcome these difficulties, we propose a new interaction detection method, named Online Random Intersection Chains. The method, which is based on the idea of frequent itemset mining, detects informative interactions by observing the intersections of randomly chosen samples. The discovered interactions enjoy high interpretability as they can be comprehended as logical expressions. ORIC can be updated every time new data is collected, without being retrained on historical data. What's more, the importance of the historical and latest data can be controlled by a tuning parameter. A framework is designed to deal with the streaming interactions, so almost all existing models for CTR prediction can be applied after interaction detection. Empirical results demonstrate the efficiency and effectiveness of ORIC on three benchmark datasets.
Discovering Categorical Main and Interaction Effects Based on Association Rule Mining
Apr 10, 2021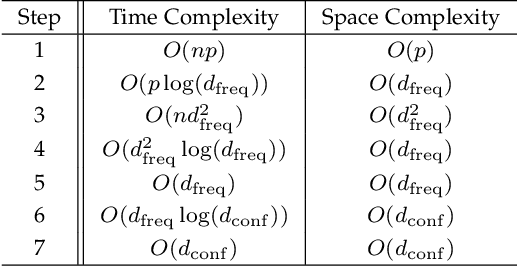

With the growing size of data sets, feature selection becomes increasingly important. Taking interactions of original features into consideration will lead to extremely high dimension, especially when the features are categorical and one-hot encoding is applied. This makes it more worthwhile mining useful features as well as their interactions. Association rule mining aims to extract interesting correlations between items, but it is difficult to use rules as a qualified classifier themselves. Drawing inspiration from association rule mining, we come up with a method that uses association rules to select features and their interactions, then modify the algorithm for several practical concerns. We analyze the computational complexity of the proposed algorithm to show its efficiency. And the results of a series of experiments verify the effectiveness of the algorithm.
Random Intersection Chains
Apr 10, 2021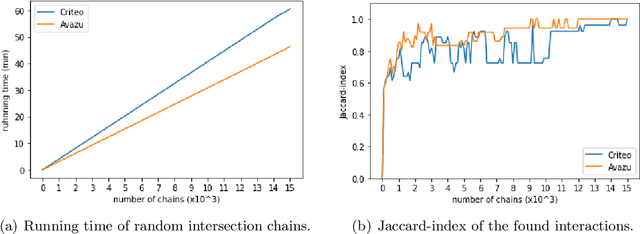
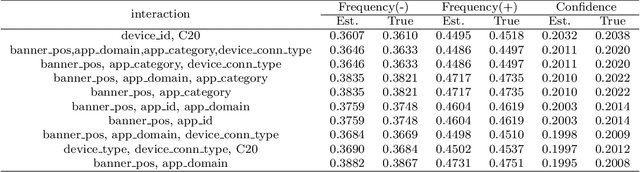
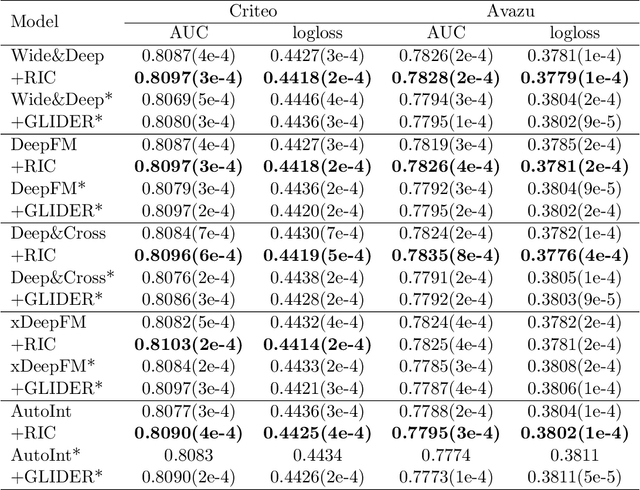
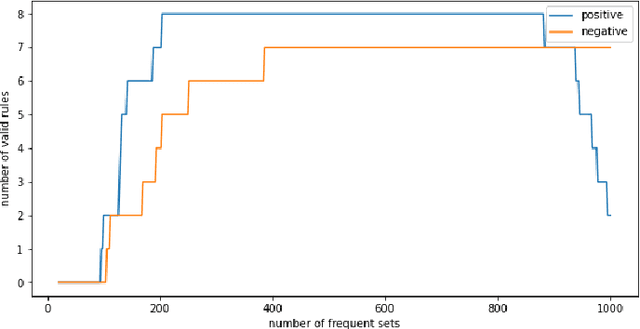
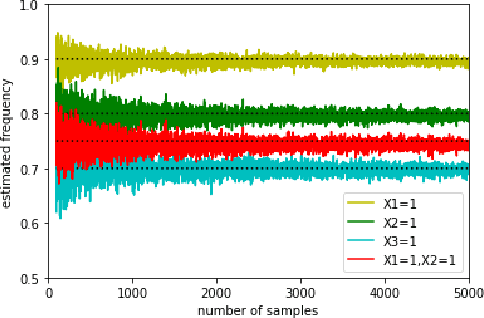
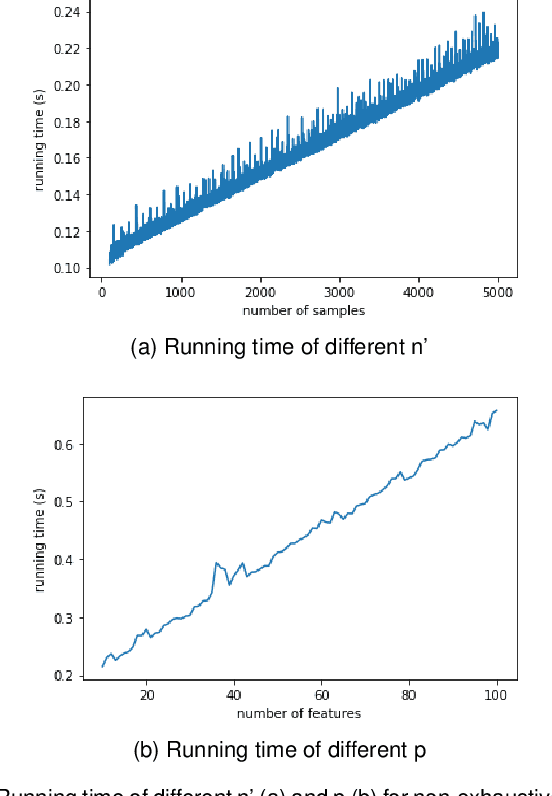
Interactions between several features sometimes play an important role in prediction tasks. But taking all the interactions into consideration will lead to an extremely heavy computational burden. For categorical features, the situation is more complicated since the input will be extremely high-dimensional and sparse if one-hot encoding is applied. Inspired by association rule mining, we propose a method that selects interactions of categorical features, called Random Intersection Chains. It uses random intersections to detect frequent patterns, then selects the most meaningful ones among them. At first a number of chains are generated, in which each node is the intersection of the previous node and a random chosen observation. The frequency of patterns in the tail nodes is estimated by maximum likelihood estimation, then the patterns with largest estimated frequency are selected. After that, their confidence is calculated by Bayes' theorem. The most confident patterns are finally returned by Random Intersection Chains. We show that if the number and length of chains are appropriately chosen, the patterns in the tail nodes are indeed the most frequent ones in the data set. We analyze the computation complexity of the proposed algorithm and prove the convergence of the estimators. The results of a series of experiments verify the efficiency and effectiveness of the algorithm.