 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimising Spatial and Tonal Data for PDE-based Inpainting
Jun 15, 2015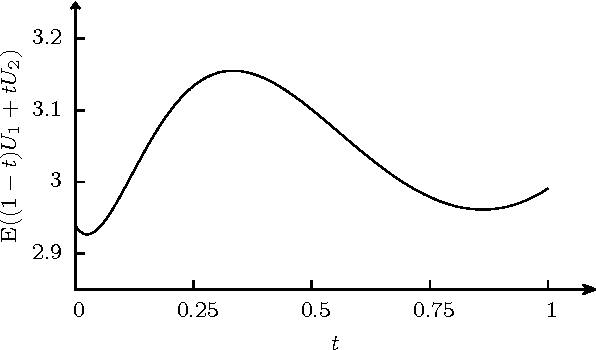

Some recent methods for lossy signal and image compression store only a few selected pixels and fill in the missing structures by inpainting with a partial differential equation (PDE). Suitable operators include the Laplacian, the biharmonic operator, and edge-enhancing anisotropic diffusion (EED). The quality of such approaches depends substantially on the selection of the data that is kept. Optimising this data in the domain and codomain gives rise to challenging mathematical problems that shall be addressed in our work. In the 1D case, we prove results that provide insights into the difficulty of this problem, and we give evidence that a splitting into spatial and tonal (i.e. function value) optimisation does hardly deteriorate the results. In the 2D setting, we present generic algorithms that achieve a high reconstruction quality even if the specified data is very sparse. To optimise the spatial data, we use a probabilistic sparsification, followed by a nonlocal pixel exchange that avoids getting trapped in bad local optima. After this spatial optimisation we perform a tonal optimisation that modifies the function values in order to reduce the global reconstruction error. For homogeneous diffusion inpainting, this comes down to a least squares problem for which we prove that it has a unique solution. We demonstrate that it can be found efficiently with a gradient descent approach that is accelerated with fast explicit diffusion (FED) cycles. Our framework allows to specify the desired density of the inpainting mask a priori. Moreover, is more generic than other data optimisation approaches for the sparse inpainting problem, since it can also be extended to nonlinear inpainting operators such as EED. This is exploited to achieve reconstructions with state-of-the-art quality. We also give an extensive literature survey on PDE-based image compression methods.
More Effective Crossover Operators for the All-Pairs Shortest Path Problem
Jul 02, 2012


The all-pairs shortest path problem is the first non-artificial problem for which it was shown that adding crossover can significantly speed up a mutation-only evolutionary algorithm. Recently, the analysis of this algorithm was refined and it was shown to have an expected optimization time (w.r.t. the number of fitness evaluations) of $\Theta(n^{3.25}(\log n)^{0.25})$. In contrast to this simple algorithm, evolutionary algorithms used in practice usually employ refined recombination strategies in order to avoid the creation of infeasible offspring. We study extensions of the basic algorithm by two such concepts which are central in recombination, namely \emph{repair mechanisms} and \emph{parent selection}. We show that repairing infeasible offspring leads to an improved expected optimization time of $\mathord{O}(n^{3.2}(\log n)^{0.2})$. As a second part of our study we prove that choosing parents that guarantee feasible offspring results in an even better optimization time of $\mathord{O}(n^{3}\log n)$. Both results show that already simple adjustments of the recombination operator can asymptotically improve the runtime of evolutionary algorithms.
Multiplicative Drift Analysis
Jan 04, 2011In this work, we introduce multiplicative drift analysis as a suitable way to analyze the runtime of randomized search heuristics such as evolutionary algorithms. We give a multiplicative version of the classical drift theorem. This allows easier analyses in those settings where the optimization progress is roughly proportional to the current distance to the optimum. To display the strength of this tool, we regard the classical problem how the (1+1) Evolutionary Algorithm optimizes an arbitrary linear pseudo-Boolean function. Here, we first give a relatively simple proof for the fact that any linear function is optimized in expected time $O(n \log n)$, where $n$ is the length of the bit string. Afterwards, we show that in fact any such function is optimized in expected time at most ${(1+o(1)) 1.39 \euler n\ln (n)}$, again using multiplicative drift analysis. We also prove a corresponding lower bound of ${(1-o(1))e n\ln(n)}$ which actually holds for all functions with a unique global optimum. We further demonstrate how our drift theorem immediately gives natural proofs (with better constants) for the best known runtime bounds for the (1+1) Evolutionary Algorithm on combinatorial problems like finding minimum spanning trees, shortest paths, or Euler tours.
* Contains results from our GECCO 2010 and CEC 2010 conference paper
Faster Black-Box Algorithms Through Higher Arity Operators
Dec 04, 2010
We extend the work of Lehre and Witt (GECCO 2010) on the unbiased black-box model by considering higher arity variation operators. In particular, we show that already for binary operators the black-box complexity of \leadingones drops from $\Theta(n^2)$ for unary operators to $O(n \log n)$. For \onemax, the $\Omega(n \log n)$ unary black-box complexity drops to O(n) in the binary case. For $k$-ary operators, $k \leq n$, the \onemax-complexity further decreases to $O(n/\log k)$.
Non-Existence of Linear Universal Drift Functions
Nov 15, 2010Drift analysis has become a powerful tool to prove bounds on the runtime of randomized search heuristics. It allows, for example, fairly simple proofs for the classical problem how the (1+1) Evolutionary Algorithm (EA) optimizes an arbitrary pseudo-Boolean linear function. The key idea of drift analysis is to measure the progress via another pseudo-Boolean function (called drift function) and use deeper results from probability theory to derive from this a good bound for the runtime of the EA. Surprisingly, all these results manage to use the same drift function for all linear objective functions. In this work, we show that such universal drift functions only exist if the mutation probability is close to the standard value of $1/n$.