 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClosing the Distribution Gap in Adversarial Training for LLMs
Feb 16, 2026Adversarial training for LLMs is one of the most promising methods to reliably improve robustness against adversaries. However, despite significant progress, models remain vulnerable to simple in-distribution exploits, such as rewriting prompts in the past tense or translating them into other languages. We argue that this persistent fragility stems from a fundamental limitation in current adversarial training algorithms: they minimize adversarial loss on their training set but inadequately cover the data distribution, resulting in vulnerability to seemingly simple attacks. To bridge this gap, we propose Distributional Adversarial Training, DAT. We leverage Diffusion LLMs to approximate the true joint distribution of prompts and responses, enabling generation of diverse, high-likelihood samples that address generalization failures. By combining optimization over the data distribution provided by the diffusion model with continuous adversarial training, DAT achieves substantially higher adversarial robustness than previous methods.
Flow-Aware Navigation of Magnetic Micro-Robots in Complex Fluids via PINN-Based Prediction
Mar 14, 2025While magnetic micro-robots have demonstrated significant potential across various applications, including drug delivery and microsurgery, the open issue of precise navigation and control in complex fluid environments is crucial for in vivo implementation. This paper introduces a novel flow-aware navigation and control strategy for magnetic micro-robots that explicitly accounts for the impact of fluid flow on their movement. First, the proposed method employs a Physics-Informed U-Net (PI-UNet) to refine the numerically predicted fluid velocity using local observations. Then, the predicted velocity is incorporated in a flow-aware A* path planning algorithm, ensuring efficient navigation while mitigating flow-induced disturbances. Finally, a control scheme is developed to compensate for the predicted fluid velocity, thereby optimizing the micro-robot's performance. A series of simulation studies and real-world experiments are conducted to validate the efficacy of the proposed approach. This method enhances both planning accuracy and control precision, expanding the potential applications of magnetic micro-robots in fluid-affected environments typical of many medical scenarios.
Surgical, Cheap, and Flexible: Mitigating False Refusal in Language Models via Single Vector Ablation
Oct 04, 2024Training a language model to be both helpful and harmless requires careful calibration of refusal behaviours: Models should refuse to follow malicious instructions or give harmful advice (e.g. "how do I kill someone?"), but they should not refuse safe requests, even if they superficially resemble unsafe ones (e.g. "how do I kill a Python process?"). Avoiding such false refusal, as prior work has shown, is challenging even for highly-capable language models. In this paper, we propose a simple and surgical method for mitigating false refusal in language models via single vector ablation. For a given model, we extract a false refusal vector and show that ablating this vector reduces false refusal rate without negatively impacting model safety and general model capabilities. We also show that our approach can be used for fine-grained calibration of model safety. Our approach is training-free and model-agnostic, making it useful for mitigating the problem of false refusal in current and future language models.
Look at the Text: Instruction-Tuned Language Models are More Robust Multiple Choice Selectors than You Think
Apr 12, 2024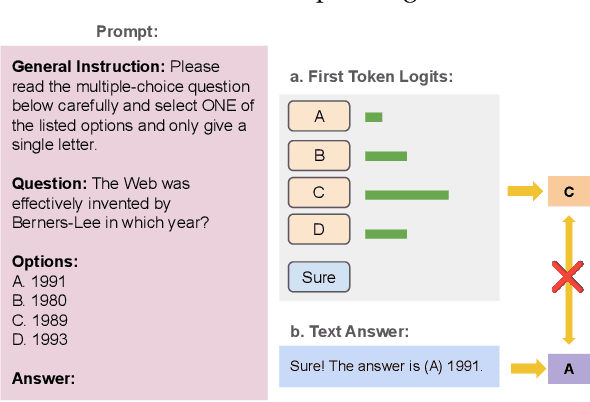

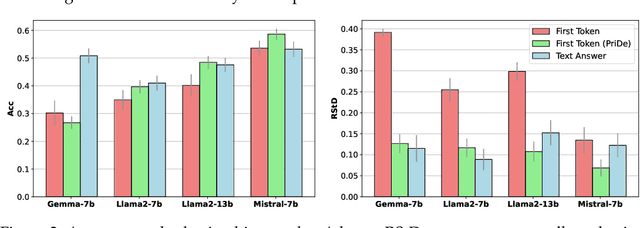
Multiple choice questions (MCQs) are commonly used to evaluate the capabilities of large language models (LLMs). One common way to evaluate the model response is to rank the candidate answers based on the log probability of the first token prediction. An alternative way is to examine the text output. Prior work has shown that first token probabilities lack robustness to changes in MCQ phrasing, and that first token probabilities do not match text answers for instruction-tuned models. Therefore, in this paper, we investigate the robustness of text answers. We show that the text answers are more robust to question perturbations than the first token probabilities, when the first token answers mismatch the text answers. The difference in robustness increases as the mismatch rate becomes greater. As the mismatch reaches over 50\%, the text answer is more robust to option order changes than the debiased first token probabilities using state-of-the-art debiasing methods such as PriDe. Our findings provide further evidence for the benefits of text answer evaluation over first token probability evaluation.
"My Answer is C": First-Token Probabilities Do Not Match Text Answers in Instruction-Tuned Language Models
Feb 22, 2024



The open-ended nature of language generation makes the evaluation of autoregressive large language models (LLMs) challenging. One common evaluation approach uses multiple-choice questions (MCQ) to limit the response space. The model is then evaluated by ranking the candidate answers by the log probability of the first token prediction. However, first-tokens may not consistently reflect the final response output, due to model's diverse response styles such as starting with "Sure" or refusing to answer. Consequently, MCQ evaluation is not indicative of model behaviour when interacting with users. But by how much? We evaluate how aligned first-token evaluation is with the text output along several dimensions, namely final option choice, refusal rate, choice distribution and robustness under prompt perturbation. Our results show that the two approaches are severely misaligned on all dimensions, reaching mismatch rates over 60%. Models heavily fine-tuned on conversational or safety data are especially impacted. Crucially, models remain misaligned even when we increasingly constrain prompts, i.e., force them to start with an option letter or example template. Our findings i) underscore the importance of inspecting the text output, too and ii) caution against relying solely on first-token evaluation.
mPLM-Sim: Unveiling Better Cross-Lingual Similarity and Transfer in Multilingual Pretrained Language Models
May 23, 2023



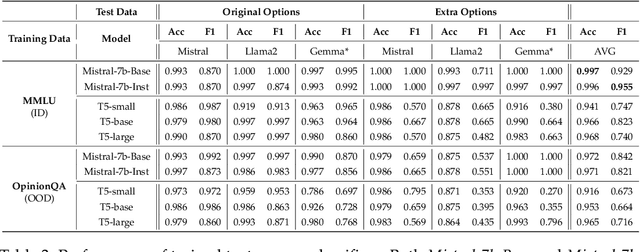
Recent multilingual pretrained language models (mPLMs) have been shown to encode strong language-specific signals, which are not explicitly provided during pretraining. It remains an open question whether it is feasible to employ mPLMs to measure language similarity, and subsequently use the similarity results to select source languages for boosting cross-lingual transfer. To investigate this, we propose mPLM-Sim, a new language similarity measure that induces the similarities across languages from mPLMs using multi-parallel corpora. Our study shows that mPLM-Sim exhibits moderately high correlations with linguistic similarity measures, such as lexicostatistics, genealogical language family, and geographical sprachbund. We also conduct a case study on languages with low correlation and observe that mPLM-Sim yields more accurate similarity results. Additionally, we find that similarity results vary across different mPLMs and different layers within an mPLM. We further investigate whether mPLM-Sim is effective for zero-shot cross-lingual transfer by conducting experiments on both low-level syntactic tasks and high-level semantic tasks. The experimental results demonstrate that mPLM-Sim is capable of selecting better source languages than linguistic measures, resulting in a 1%-2% improvement in zero-shot cross-lingual transfer performance.