 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLook at the Text: Instruction-Tuned Language Models are More Robust Multiple Choice Selectors than You Think
Paper and Code
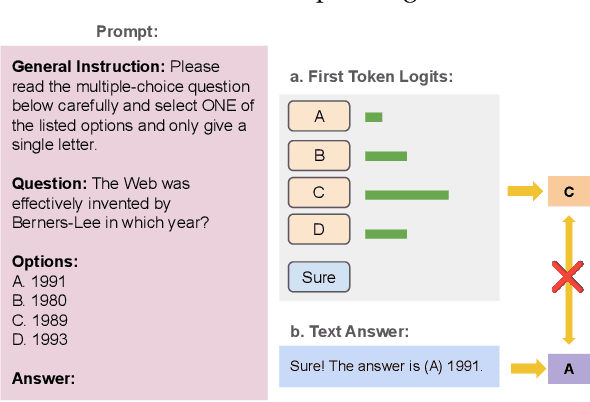

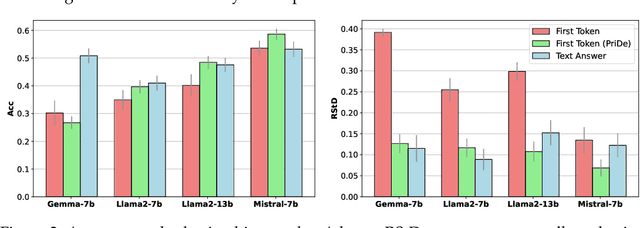
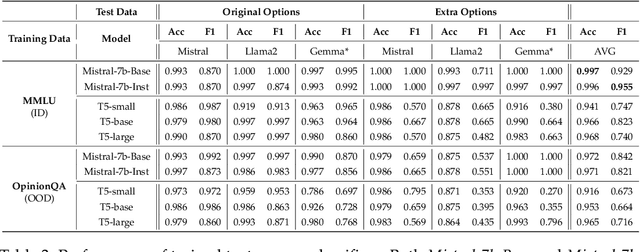
Multiple choice questions (MCQs) are commonly used to evaluate the capabilities of large language models (LLMs). One common way to evaluate the model response is to rank the candidate answers based on the log probability of the first token prediction. An alternative way is to examine the text output. Prior work has shown that first token probabilities lack robustness to changes in MCQ phrasing, and that first token probabilities do not match text answers for instruction-tuned models. Therefore, in this paper, we investigate the robustness of text answers. We show that the text answers are more robust to question perturbations than the first token probabilities, when the first token answers mismatch the text answers. The difference in robustness increases as the mismatch rate becomes greater. As the mismatch reaches over 50\%, the text answer is more robust to option order changes than the debiased first token probabilities using state-of-the-art debiasing methods such as PriDe. Our findings provide further evidence for the benefits of text answer evaluation over first token probability evaluation.