 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePost-training Quantization with Progressive Calibration and Activation Relaxing for Text-to-Image Diffusion Models
Nov 18, 2023



Diffusion models have achieved great success due to their remarkable generation ability. However, their high computational overhead is still a troublesome problem. Recent studies have leveraged post-training quantization (PTQ) to compress diffusion models. However, most of them only focus on unconditional models, leaving the quantization of widely used large pretrained text-to-image models, e.g., Stable Diffusion, largely unexplored. In this paper, we propose a novel post-training quantization method PCR (Progressive Calibration and Relaxing) for text-to-image diffusion models, which consists of a progressive calibration strategy that considers the accumulated quantization error across timesteps, and an activation relaxing strategy that improves the performance with negligible cost. Additionally, we demonstrate the previous metrics for text-to-image diffusion model quantization are not accurate due to the distribution gap. To tackle the problem, we propose a novel QDiffBench benchmark, which utilizes data in the same domain for more accurate evaluation. Besides, QDiffBench also considers the generalization performance of the quantized model outside the calibration dataset. Extensive experiments on Stable Diffusion and Stable Diffusion XL demonstrate the superiority of our method and benchmark. Moreover, we are the first to achieve quantization for Stable Diffusion XL while maintaining the performance.
Lightweight Diffusion Models with Distillation-Based Block Neural Architecture Search
Nov 15, 2023Diffusion models have recently shown remarkable generation ability, achieving state-of-the-art performance in many tasks. However, the high computational cost is still a troubling problem for diffusion models. To tackle this problem, we propose to automatically remove the structural redundancy in diffusion models with our proposed Diffusion Distillation-based Block-wise Neural Architecture Search (DiffNAS). Specifically, given a larger pretrained teacher, we leverage DiffNAS to search for the smallest architecture which can achieve on-par or even better performance than the teacher. Considering current diffusion models are based on UNet which naturally has a block-wise structure, we perform neural architecture search independently in each block, which largely reduces the search space. Different from previous block-wise NAS methods, DiffNAS contains a block-wise local search strategy and a retraining strategy with a joint dynamic loss. Concretely, during the search process, we block-wisely select the best subnet to avoid the unfairness brought by the global search strategy used in previous works. When retraining the searched architecture, we adopt a dynamic joint loss to maintain the consistency between supernet training and subnet retraining, which also provides informative objectives for each block and shortens the paths of gradient propagation. We demonstrate this joint loss can effectively improve model performance. We also prove the necessity of the dynamic adjustment of this loss. The experiments show that our method can achieve significant computational reduction, especially on latent diffusion models with about 50\% MACs and Parameter reduction.
NeurIPS'22 Cross-Domain MetaDL competition: Design and baseline results
Aug 31, 2022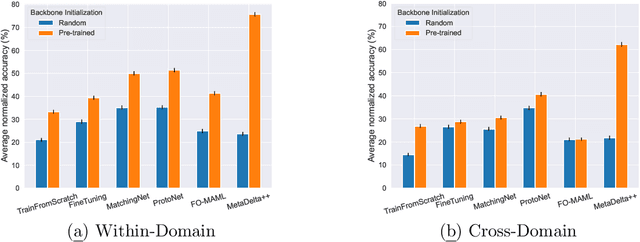

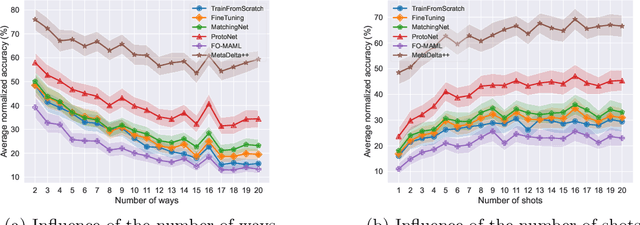

We present the design and baseline results for a new challenge in the ChaLearn meta-learning series, accepted at NeurIPS'22, focusing on "cross-domain" meta-learning. Meta-learning aims to leverage experience gained from previous tasks to solve new tasks efficiently (i.e., with better performance, little training data, and/or modest computational resources). While previous challenges in the series focused on within-domain few-shot learning problems, with the aim of learning efficiently N-way k-shot tasks (i.e., N class classification problems with k training examples), this competition challenges the participants to solve "any-way" and "any-shot" problems drawn from various domains (healthcare, ecology, biology, manufacturing, and others), chosen for their humanitarian and societal impact. To that end, we created Meta-Album, a meta-dataset of 40 image classification datasets from 10 domains, from which we carve out tasks with any number of "ways" (within the range 2-20) and any number of "shots" (within the range 1-20). The competition is with code submission, fully blind-tested on the CodaLab challenge platform. The code of the winners will be open-sourced, enabling the deployment of automated machine learning solutions for few-shot image classification across several domains.
AutoGL: A Library for Automated Graph Learning
May 04, 2021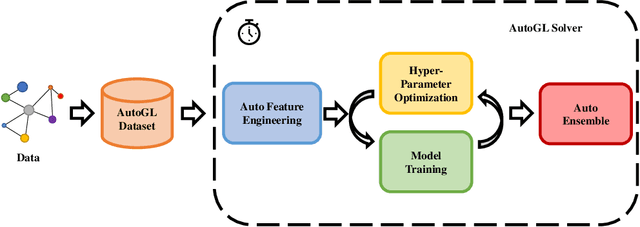
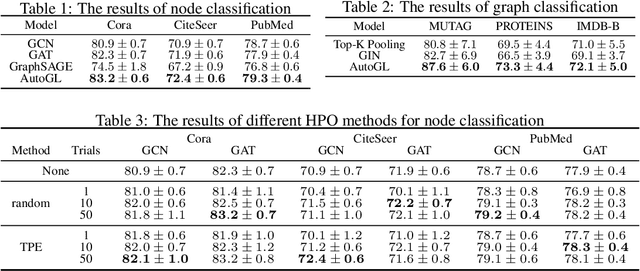

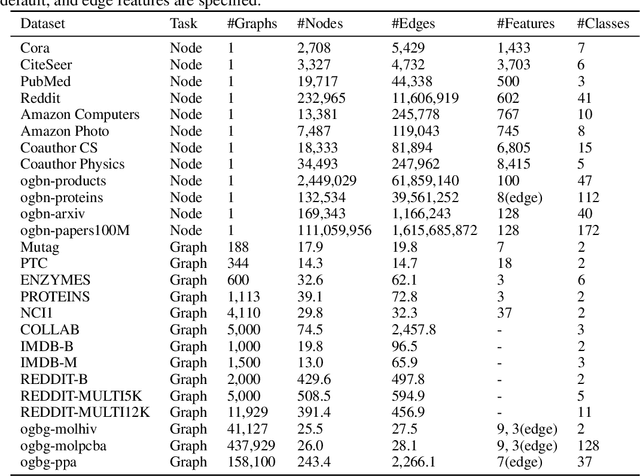
Recent years have witnessed an upsurge of research interests and applications of machine learning on graphs. Automated machine learning (AutoML) on graphs is on the horizon to automatically design the optimal machine learning algorithm for a given graph task. However, none of the existing libraries can fully support AutoML on graphs. To fill this gap, we present Automated Graph Learning (AutoGL), the first library for automated machine learning on graphs. AutoGL is open-source, easy to use, and flexible to be extended. Specifically, we propose an automated machine learning pipeline for graph data containing four modules: auto feature engineering, model training, hyper-parameter optimization, and auto ensemble. For each module, we provide numerous state-of-the-art methods and flexible base classes and APIs, which allow easy customization. We further provide experimental results to showcase the usage of our AutoGL library.
MetaDelta: A Meta-Learning System for Few-shot Image Classification
Feb 22, 2021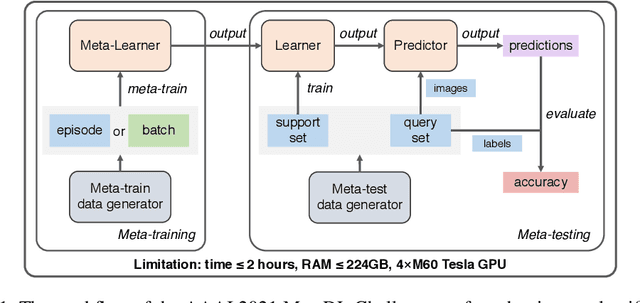

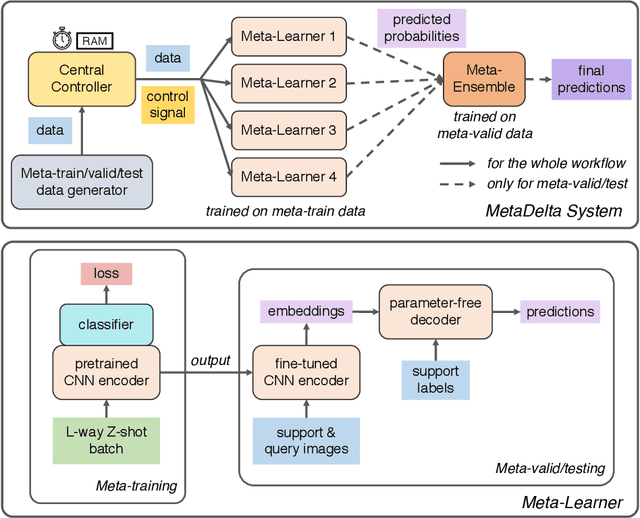
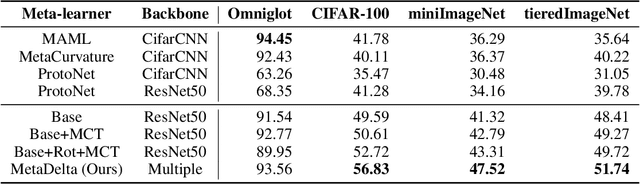
Meta-learning aims at learning quickly on novel tasks with limited data by transferring generic experience learned from previous tasks. Naturally, few-shot learning has been one of the most popular applications for meta-learning. However, existing meta-learning algorithms rarely consider the time and resource efficiency or the generalization capacity for unknown datasets, which limits their applicability in real-world scenarios. In this paper, we propose MetaDelta, a novel practical meta-learning system for the few-shot image classification. MetaDelta consists of two core components: i) multiple meta-learners supervised by a central controller to ensure efficiency, and ii) a meta-ensemble module in charge of integrated inference and better generalization. In particular, each meta-learner in MetaDelta is composed of a unique pretrained encoder fine-tuned by batch training and parameter-free decoder used for prediction. MetaDelta ranks first in the final phase in the AAAI 2021 MetaDL Challenge\footnote{https://competitions.codalab.org/competitions/26638}, demonstrating the advantages of our proposed system. The codes are publicly available at https://github.com/Frozenmad/MetaDelta.
Semantic Role Labeling with Associated Memory Network
Aug 05, 2019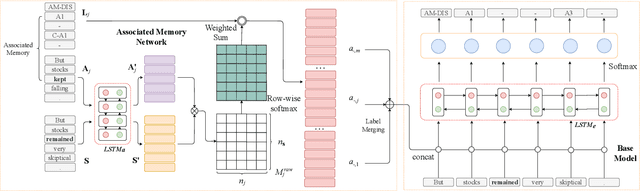
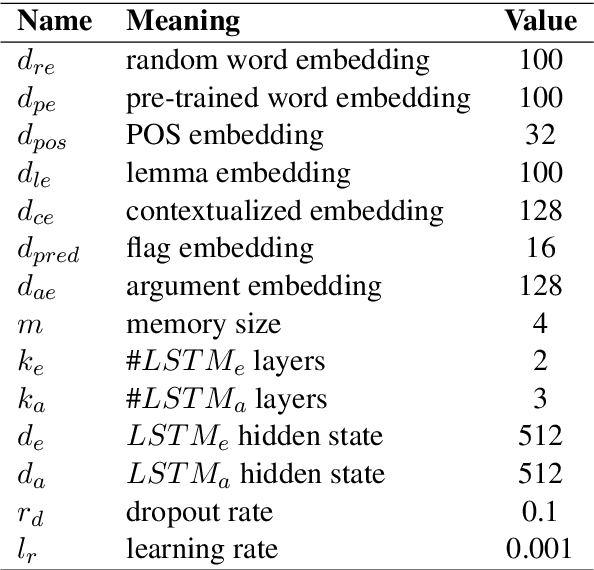
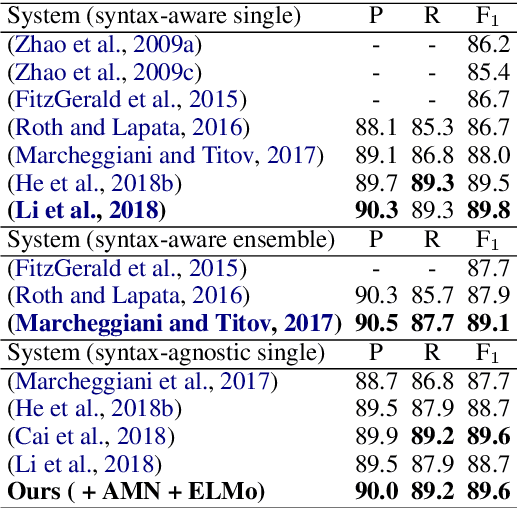
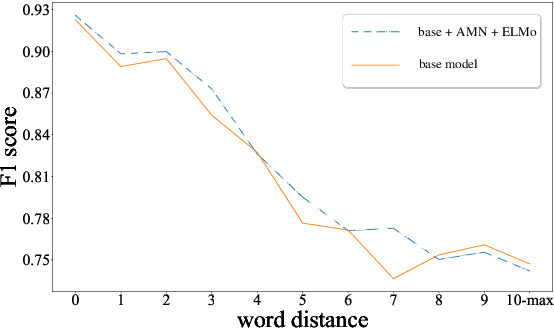
Semantic role labeling (SRL) is a task to recognize all the predicate-argument pairs of a sentence, which has been in a performance improvement bottleneck after a series of latest works were presented. This paper proposes a novel syntax-agnostic SRL model enhanced by the proposed associated memory network (AMN), which makes use of inter-sentence attention of label-known associated sentences as a kind of memory to further enhance dependency-based SRL. In detail, we use sentences and their labels from train dataset as an associated memory cue to help label the target sentence. Furthermore, we compare several associated sentences selecting strategies and label merging methods in AMN to find and utilize the label of associated sentences while attending them. By leveraging the attentive memory from known training data, Our full model reaches state-of-the-art on CoNLL-2009 benchmark datasets for syntax-agnostic setting, showing a new effective research line of SRL enhancement other than exploiting external resources such as well pre-trained language models.