 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Egocentric Vision-Language Model based Portable Real-time Smart Assistant
Mar 06, 2025We present Vinci, a vision-language system designed to provide real-time, comprehensive AI assistance on portable devices. At its core, Vinci leverages EgoVideo-VL, a novel model that integrates an egocentric vision foundation model with a large language model (LLM), enabling advanced functionalities such as scene understanding, temporal grounding, video summarization, and future planning. To enhance its utility, Vinci incorporates a memory module for processing long video streams in real time while retaining contextual history, a generation module for producing visual action demonstrations, and a retrieval module that bridges egocentric and third-person perspectives to provide relevant how-to videos for skill acquisition. Unlike existing systems that often depend on specialized hardware, Vinci is hardware-agnostic, supporting deployment across a wide range of devices, including smartphones and wearable cameras. In our experiments, we first demonstrate the superior performance of EgoVideo-VL on multiple public benchmarks, showcasing its vision-language reasoning and contextual understanding capabilities. We then conduct a series of user studies to evaluate the real-world effectiveness of Vinci, highlighting its adaptability and usability in diverse scenarios. We hope Vinci can establish a new framework for portable, real-time egocentric AI systems, empowering users with contextual and actionable insights. Including the frontend, backend, and models, all codes of Vinci are available at https://github.com/OpenGVLab/vinci.
Vinci: A Real-time Embodied Smart Assistant based on Egocentric Vision-Language Model
Dec 30, 2024



We introduce Vinci, a real-time embodied smart assistant built upon an egocentric vision-language model. Designed for deployment on portable devices such as smartphones and wearable cameras, Vinci operates in an "always on" mode, continuously observing the environment to deliver seamless interaction and assistance. Users can wake up the system and engage in natural conversations to ask questions or seek assistance, with responses delivered through audio for hands-free convenience. With its ability to process long video streams in real-time, Vinci can answer user queries about current observations and historical context while also providing task planning based on past interactions. To further enhance usability, Vinci integrates a video generation module that creates step-by-step visual demonstrations for tasks that require detailed guidance. We hope that Vinci can establish a robust framework for portable, real-time egocentric AI systems, empowering users with contextual and actionable insights. We release the complete implementation for the development of the device in conjunction with a demo web platform to test uploaded videos at https://github.com/OpenGVLab/vinci.
Deep Multimodal Speaker Naming
Jul 17, 2015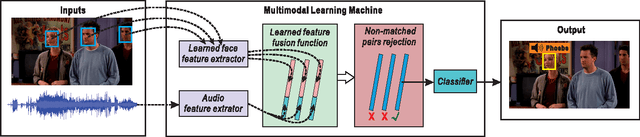
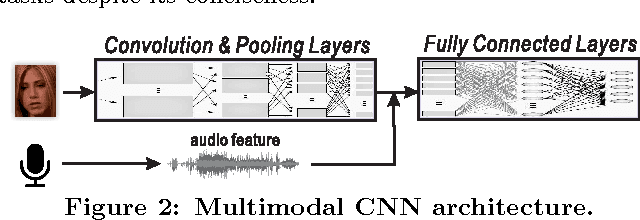
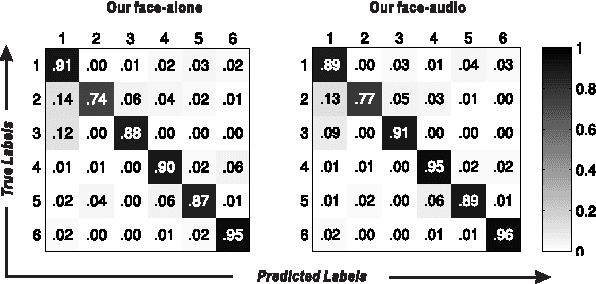
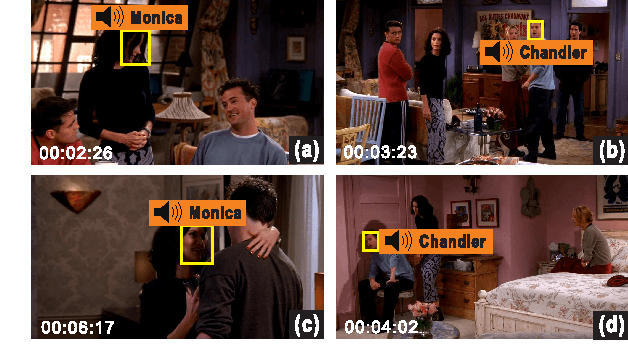
Automatic speaker naming is the problem of localizing as well as identifying each speaking character in a TV/movie/live show video. This is a challenging problem mainly attributes to its multimodal nature, namely face cue alone is insufficient to achieve good performance. Previous multimodal approaches to this problem usually process the data of different modalities individually and merge them using handcrafted heuristics. Such approaches work well for simple scenes, but fail to achieve high performance for speakers with large appearance variations. In this paper, we propose a novel convolutional neural networks (CNN) based learning framework to automatically learn the fusion function of both face and audio cues. We show that without using face tracking, facial landmark localization or subtitle/transcript, our system with robust multimodal feature extraction is able to achieve state-of-the-art speaker naming performance evaluated on two diverse TV series. The dataset and implementation of our algorithm are publicly available online.