 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeepTag: A General Framework for Fiducial Marker Design and Detection
May 28, 2021

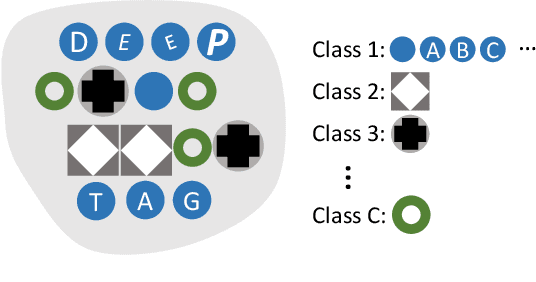
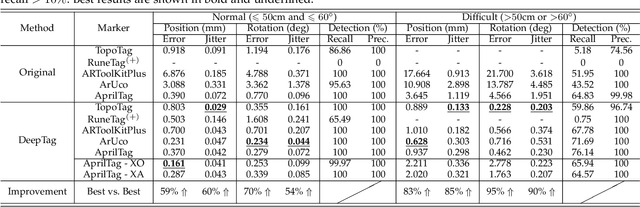
A fiducial marker system usually consists of markers, a detection algorithm, and a coding system. The appearance of markers and the detection robustness are generally limited by the existing detection algorithms, which are hand-crafted with traditional low-level image processing techniques. Furthermore, a sophisticatedly designed coding system is required to overcome the shortcomings of both markers and detection algorithms. To improve the flexibility and robustness in various applications, we propose a general deep learning based framework, DeepTag, for fiducial marker design and detection. DeepTag not only supports detection of a wide variety of existing marker families, but also makes it possible to design new marker families with customized local patterns. Moreover, we propose an effective procedure to synthesize training data on the fly without manual annotations. Thus, DeepTag can easily adapt to existing and newly-designed marker families. To validate DeepTag and existing methods, beside existing datasets, we further collect a new large and challenging dataset where markers are placed in different view distances and angles. Experiments show that DeepTag well supports different marker families and greatly outperforms the existing methods in terms of both detection robustness and pose accuracy. Both code and dataset are available at \url{https://herohuyongtao.github.io/research/publications/deep-tag/}.
TopoTag: A Robust and Scalable Topological Fiducial Marker System
Aug 05, 2019
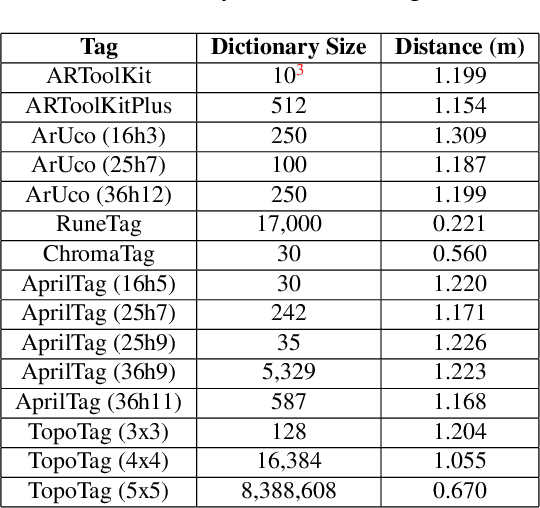

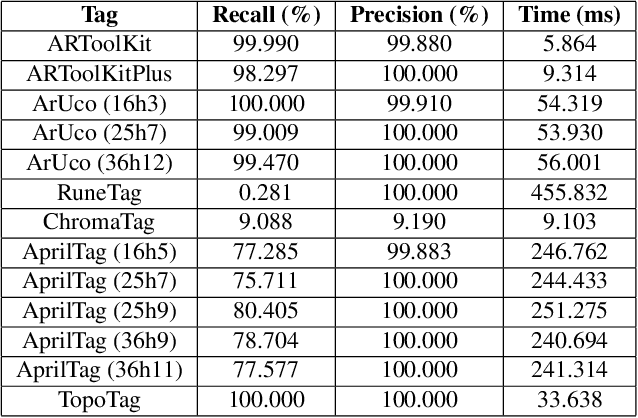
Fiducial markers have been playing an important role in augmented reality (AR), robot navigation, and general applications where the relative pose between a camera and an object is required. We introduce TopoTag, a robust and scalable topological fiducial marker system, which supports reliable and accurate pose estimation from a single image. TopoTag uses topological and geometrical information in marker detection to achieve higher robustness. Without sacrificing bits for higher recall and precision like previous systems, TopoTag can use full bits for ID encoding and supports tens of thousands unique IDs and easily extends to millions and more by adding more bits, thus achieves perfect scalability. We collect a large dataset including in total 169,713 images for evaluation, involving in-plane and out-of-plane rotation, image blur, different distances and various backgrounds, etc. Experiments show that TopoTag significantly outperforms previous fiducial marker systems in terms of various metrics, including detection accuracy, vertex jitter, pose jitter and accuracy, etc. In addition, TopoTag supports occlusion as long as main tag topological structure is maintained and flexible shape design where users can customize inter and outer marker shapes. Our dataset, marker design and detection algorithm are public to the community.
Look, Listen and Learn - A Multimodal LSTM for Speaker Identification
Feb 13, 2016



Speaker identification refers to the task of localizing the face of a person who has the same identity as the ongoing voice in a video. This task not only requires collective perception over both visual and auditory signals, the robustness to handle severe quality degradations and unconstrained content variations are also indispensable. In this paper, we describe a novel multimodal Long Short-Term Memory (LSTM) architecture which seamlessly unifies both visual and auditory modalities from the beginning of each sequence input. The key idea is to extend the conventional LSTM by not only sharing weights across time steps, but also sharing weights across modalities. We show that modeling the temporal dependency across face and voice can significantly improve the robustness to content quality degradations and variations. We also found that our multimodal LSTM is robustness to distractors, namely the non-speaking identities. We applied our multimodal LSTM to The Big Bang Theory dataset and showed that our system outperforms the state-of-the-art systems in speaker identification with lower false alarm rate and higher recognition accuracy.
Deep Multimodal Speaker Naming
Jul 17, 2015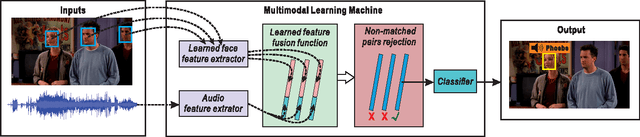
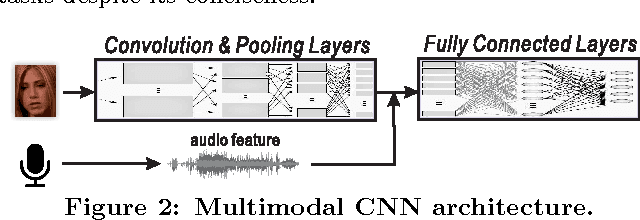
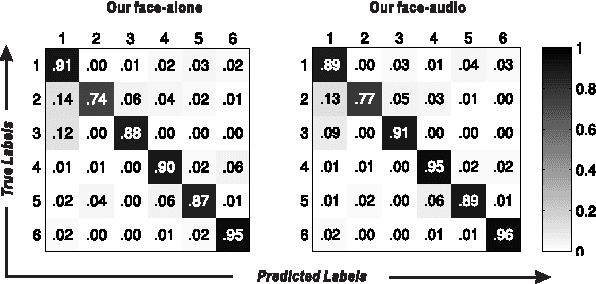
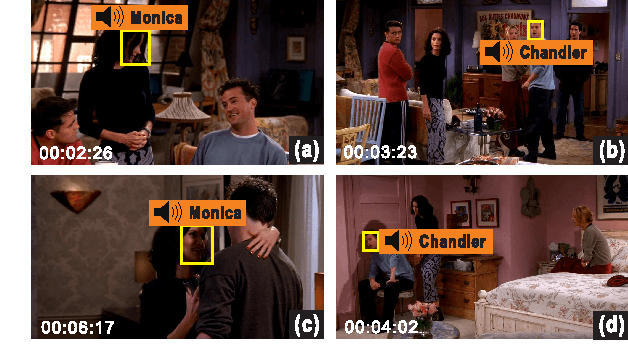
Automatic speaker naming is the problem of localizing as well as identifying each speaking character in a TV/movie/live show video. This is a challenging problem mainly attributes to its multimodal nature, namely face cue alone is insufficient to achieve good performance. Previous multimodal approaches to this problem usually process the data of different modalities individually and merge them using handcrafted heuristics. Such approaches work well for simple scenes, but fail to achieve high performance for speakers with large appearance variations. In this paper, we propose a novel convolutional neural networks (CNN) based learning framework to automatically learn the fusion function of both face and audio cues. We show that without using face tracking, facial landmark localization or subtitle/transcript, our system with robust multimodal feature extraction is able to achieve state-of-the-art speaker naming performance evaluated on two diverse TV series. The dataset and implementation of our algorithm are publicly available online.