 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePaper2Rebuttal: A Multi-Agent Framework for Transparent Author Response Assistance
Jan 20, 2026Writing effective rebuttals is a high-stakes task that demands more than linguistic fluency, as it requires precise alignment between reviewer intent and manuscript details. Current solutions typically treat this as a direct-to-text generation problem, suffering from hallucination, overlooked critiques, and a lack of verifiable grounding. To address these limitations, we introduce $\textbf{RebuttalAgent}$, the first multi-agents framework that reframes rebuttal generation as an evidence-centric planning task. Our system decomposes complex feedback into atomic concerns and dynamically constructs hybrid contexts by synthesizing compressed summaries with high-fidelity text while integrating an autonomous and on-demand external search module to resolve concerns requiring outside literature. By generating an inspectable response plan before drafting, $\textbf{RebuttalAgent}$ ensures that every argument is explicitly anchored in internal or external evidence. We validate our approach on the proposed $\textbf{RebuttalBench}$ and demonstrate that our pipeline outperforms strong baselines in coverage, faithfulness, and strategic coherence, offering a transparent and controllable assistant for the peer review process. Code will be released.
StructVRM: Aligning Multimodal Reasoning with Structured and Verifiable Reward Models
Aug 07, 2025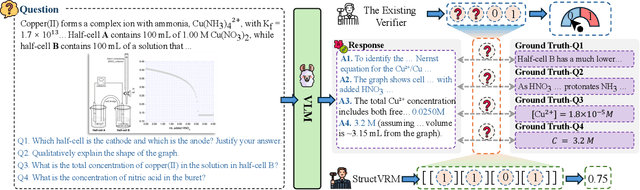

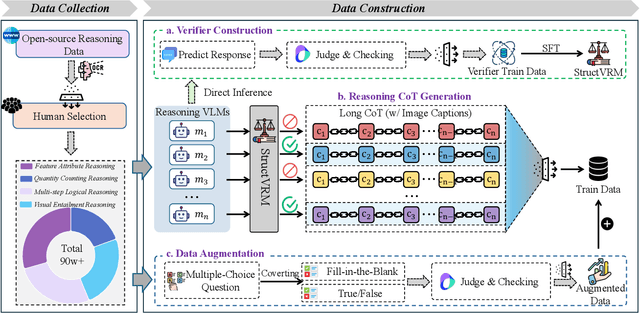
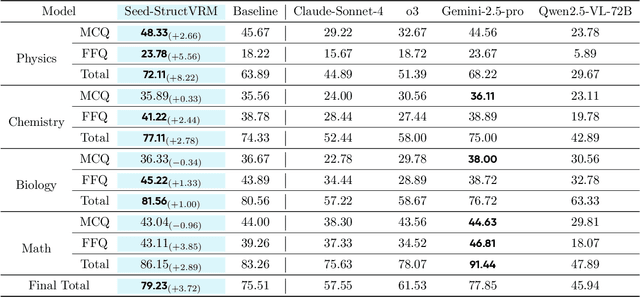
Existing Vision-Language Models often struggle with complex, multi-question reasoning tasks where partial correctness is crucial for effective learning. Traditional reward mechanisms, which provide a single binary score for an entire response, are too coarse to guide models through intricate problems with multiple sub-parts. To address this, we introduce StructVRM, a method that aligns multimodal reasoning with Structured and Verifiable Reward Models. At its core is a model-based verifier trained to provide fine-grained, sub-question-level feedback, assessing semantic and mathematical equivalence rather than relying on rigid string matching. This allows for nuanced, partial credit scoring in previously intractable problem formats. Extensive experiments demonstrate the effectiveness of StructVRM. Our trained model, Seed-StructVRM, achieves state-of-the-art performance on six out of twelve public multimodal benchmarks and our newly curated, high-difficulty STEM-Bench. The success of StructVRM validates that training with structured, verifiable rewards is a highly effective approach for advancing the capabilities of multimodal models in complex, real-world reasoning domains.
Harnessing Your DRAM and SSD for Sustainable and Accessible LLM Inference with Mixed-Precision and Multi-level Caching
Oct 23, 2024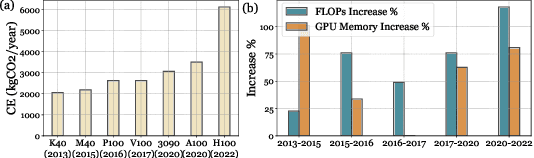
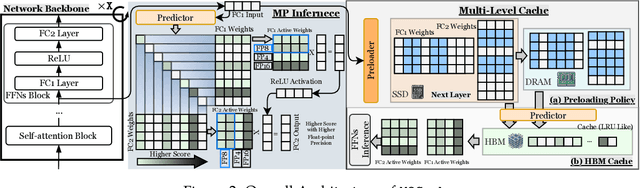
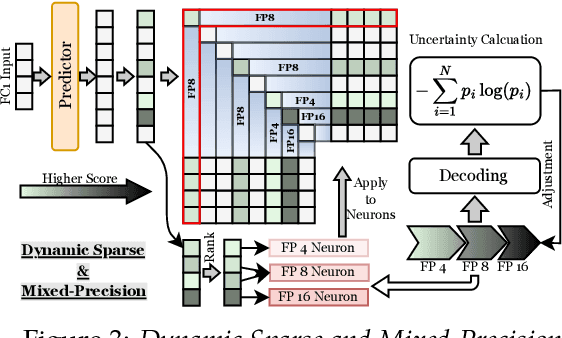
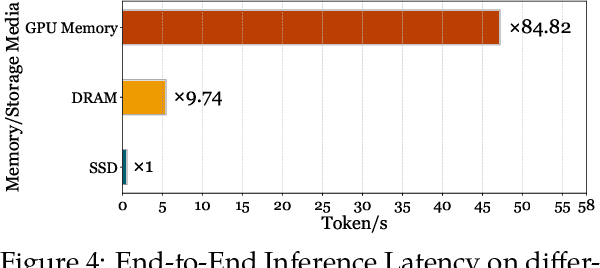
Although Large Language Models (LLMs) have demonstrated remarkable capabilities, their massive parameter counts and associated extensive computing make LLMs' deployment the main part of carbon emission from nowadays AI applications. Compared to modern GPUs like H$100$, it would be significantly carbon-sustainable if we could leverage old-fashioned GPUs such as M$40$ (as shown in Figure 1, M$40$ only has one third carbon emission of H$100$'s) for LLM servings. However, the limited High Bandwidth Memory (HBM) available on such GPU often cannot support the loading of LLMs due to the gigantic model size and intermediate activation data, making their serving challenging. For instance, a LLaMA2 model with $70$B parameters typically requires $128$GB for inference, which substantially surpasses $24$GB HBM in a $3090$ GPU and remains infeasible even considering the additional $64$GB DRAM. To address this challenge, this paper proposes a mixed-precision with a model modularization algorithm to enable LLM inference on outdated hardware with resource constraints. (The precision denotes the numerical precision like FP16, INT8, INT4) and multi-level caching (M2Cache).) Specifically, our M2Cache first modulizes neurons in LLM and creates their importance ranking. Then, it adopts a dynamic sparse mixed-precision quantization mechanism in weight space to reduce computational demands and communication overhead at each decoding step. It collectively lowers the operational carbon emissions associated with LLM inference. Moreover, M2Cache introduces a three-level cache management system with HBM, DRAM, and SSDs that complements the dynamic sparse mixed-precision inference. To enhance communication efficiency, M2Cache maintains a neuron-level mixed-precision LRU cache in HBM, a larger layer-aware cache in DRAM, and a full model in SSD.