 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLookalike3D: Seeing Double in 3D
Mar 25, 20263D object understanding and generation methods produce impressive results, yet they often overlook a pervasive source of information in real-world scenes: repeated objects. We introduce the task of lookalike object detection in indoor scenes, which leverages repeated and complementary cues from identical and near-identical object pairs. Given an input scene, the task is to classify pairs of objects as identical, similar or different using multiview images as input. To address this, we present Lookalike3D, a multiview image transformer that effectively distinguishes such object pairs by harnessing strong semantic priors from large image foundation models. To support this task, we collected the 3DTwins dataset, containing 76k manually annotated identical, similar and different pairs of objects based on ScanNet++, and show an improvement of 104% IoU over baselines. We demonstrate how our method improves downstream tasks such as enabling joint 3D object reconstruction and part co-segmentation, turning repeated and lookalike objects into a powerful cue for consistent, high-quality 3D perception. Our code, dataset and models will be made publicly available.
TUM2TWIN: Introducing the Large-Scale Multimodal Urban Digital Twin Benchmark Dataset
May 13, 2025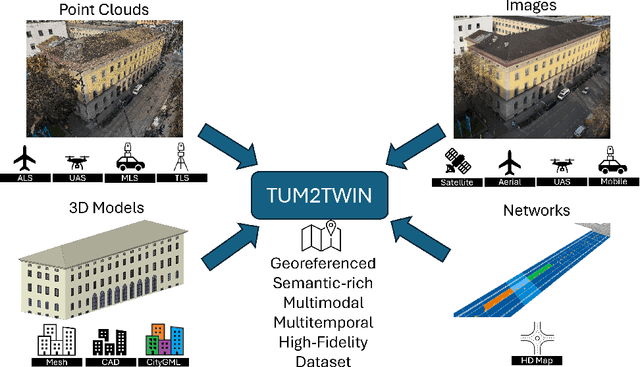
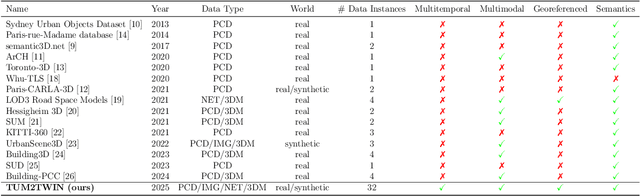

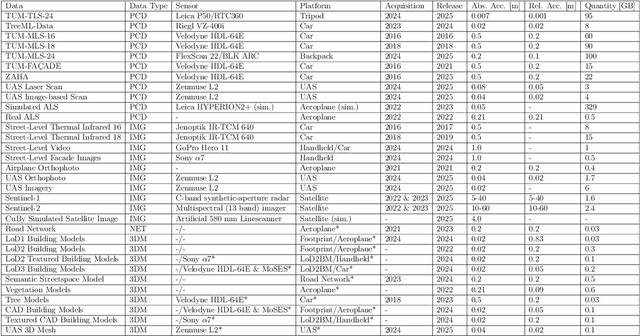
Urban Digital Twins (UDTs) have become essential for managing cities and integrating complex, heterogeneous data from diverse sources. Creating UDTs involves challenges at multiple process stages, including acquiring accurate 3D source data, reconstructing high-fidelity 3D models, maintaining models' updates, and ensuring seamless interoperability to downstream tasks. Current datasets are usually limited to one part of the processing chain, hampering comprehensive UDTs validation. To address these challenges, we introduce the first comprehensive multimodal Urban Digital Twin benchmark dataset: TUM2TWIN. This dataset includes georeferenced, semantically aligned 3D models and networks along with various terrestrial, mobile, aerial, and satellite observations boasting 32 data subsets over roughly 100,000 $m^2$ and currently 767 GB of data. By ensuring georeferenced indoor-outdoor acquisition, high accuracy, and multimodal data integration, the benchmark supports robust analysis of sensors and the development of advanced reconstruction methods. Additionally, we explore downstream tasks demonstrating the potential of TUM2TWIN, including novel view synthesis of NeRF and Gaussian Splatting, solar potential analysis, point cloud semantic segmentation, and LoD3 building reconstruction. We are convinced this contribution lays a foundation for overcoming current limitations in UDT creation, fostering new research directions and practical solutions for smarter, data-driven urban environments. The project is available under: https://tum2t.win
ScanNet++: A High-Fidelity Dataset of 3D Indoor Scenes
Aug 22, 2023We present ScanNet++, a large-scale dataset that couples together capture of high-quality and commodity-level geometry and color of indoor scenes. Each scene is captured with a high-end laser scanner at sub-millimeter resolution, along with registered 33-megapixel images from a DSLR camera, and RGB-D streams from an iPhone. Scene reconstructions are further annotated with an open vocabulary of semantics, with label-ambiguous scenarios explicitly annotated for comprehensive semantic understanding. ScanNet++ enables a new real-world benchmark for novel view synthesis, both from high-quality RGB capture, and importantly also from commodity-level images, in addition to a new benchmark for 3D semantic scene understanding that comprehensively encapsulates diverse and ambiguous semantic labeling scenarios. Currently, ScanNet++ contains 460 scenes, 280,000 captured DSLR images, and over 3.7M iPhone RGBD frames.
Directional Message Passing on Molecular Graphs via Synthetic Coordinates
Nov 08, 2021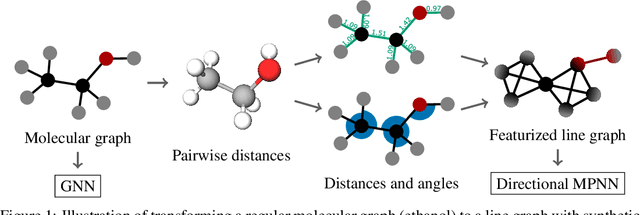


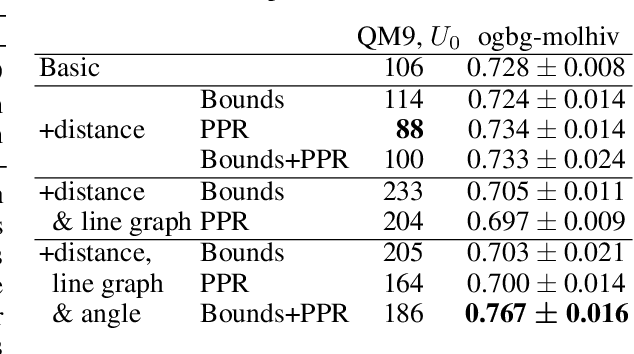
Graph neural networks that leverage coordinates via directional message passing have recently set the state of the art on multiple molecular property prediction tasks. However, they rely on atom position information that is often unavailable, and obtaining it is usually prohibitively expensive or even impossible. In this paper we propose synthetic coordinates that enable the use of advanced GNNs without requiring the true molecular configuration. We propose two distances as synthetic coordinates: Distance bounds that specify the rough range of molecular configurations, and graph-based distances using a symmetric variant of personalized PageRank. To leverage both distance and angular information we propose a method of transforming normal graph neural networks into directional MPNNs. We show that with this transformation we can reduce the error of a normal graph neural network by 55% on the ZINC benchmark. We furthermore set the state of the art on ZINC and coordinate-free QM9 by incorporating synthetic coordinates in the SMP and DimeNet++ models. Our implementation is available online.
SceneFormer: Indoor Scene Generation with Transformers
Dec 17, 2020


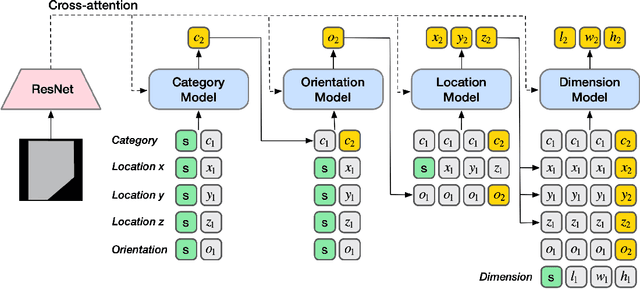
The task of indoor scene generation is to generate a sequence of objects, their locations and orientations conditioned on the shape and size of a room. Large scale indoor scene datasets allow us to extract patterns from user-designed indoor scenes and then generate new scenes based on these patterns. Existing methods rely on the 2D or 3D appearance of these scenes in addition to object positions, and make assumptions about the possible relations between objects. In contrast, we do not use any appearance information, and learn relations between objects using the self attention mechanism of transformers. We show that this leads to faster scene generation compared to existing methods with the same or better levels of realism. We build simple and effective generative models conditioned on the room shape, and on text descriptions of the room using only the cross-attention mechanism of transformers. We carried out a user study showing that our generated scenes are preferred over DeepSynth scenes 57.7% of the time for bedroom scenes, and 63.3% for living room scenes. In addition, we generate a scene in 1.48 seconds on average, 20% faster than the state of the art method Fast & Flexible, allowing interactive scene generation.