 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSceneFormer: Indoor Scene Generation with Transformers
Paper and Code
Dec 17, 2020


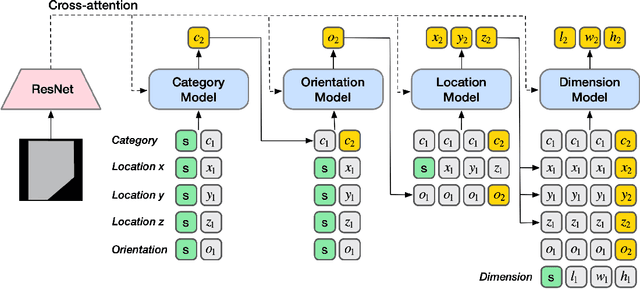
The task of indoor scene generation is to generate a sequence of objects, their locations and orientations conditioned on the shape and size of a room. Large scale indoor scene datasets allow us to extract patterns from user-designed indoor scenes and then generate new scenes based on these patterns. Existing methods rely on the 2D or 3D appearance of these scenes in addition to object positions, and make assumptions about the possible relations between objects. In contrast, we do not use any appearance information, and learn relations between objects using the self attention mechanism of transformers. We show that this leads to faster scene generation compared to existing methods with the same or better levels of realism. We build simple and effective generative models conditioned on the room shape, and on text descriptions of the room using only the cross-attention mechanism of transformers. We carried out a user study showing that our generated scenes are preferred over DeepSynth scenes 57.7% of the time for bedroom scenes, and 63.3% for living room scenes. In addition, we generate a scene in 1.48 seconds on average, 20% faster than the state of the art method Fast & Flexible, allowing interactive scene generation.