 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSplicing Up Your Predictions with RNA Contrastive Learning
Oct 17, 2023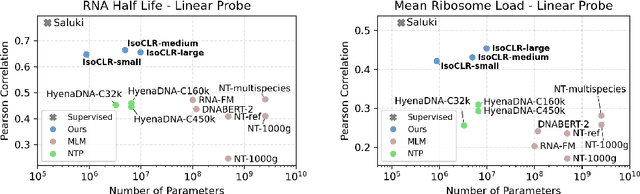

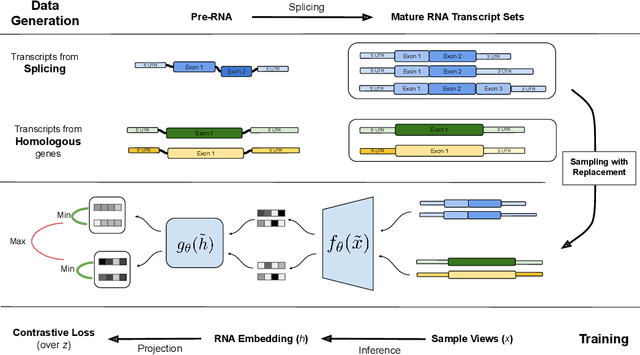
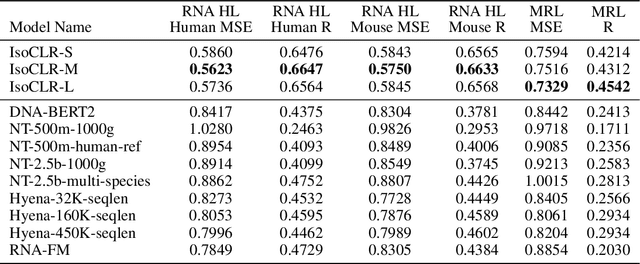
In the face of rapidly accumulating genomic data, our understanding of the RNA regulatory code remains incomplete. Recent self-supervised methods in other domains have demonstrated the ability to learn rules underlying the data-generating process such as sentence structure in language. Inspired by this, we extend contrastive learning techniques to genomic data by utilizing functional similarities between sequences generated through alternative splicing and gene duplication. Our novel dataset and contrastive objective enable the learning of generalized RNA isoform representations. We validate their utility on downstream tasks such as RNA half-life and mean ribosome load prediction. Our pre-training strategy yields competitive results using linear probing on both tasks, along with up to a two-fold increase in Pearson correlation in low-data conditions. Importantly, our exploration of the learned latent space reveals that our contrastive objective yields semantically meaningful representations, underscoring its potential as a valuable initialization technique for RNA property prediction.
PixelGAN Autoencoders
Jun 02, 2017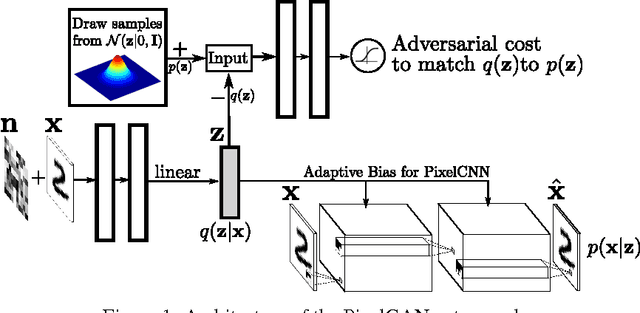
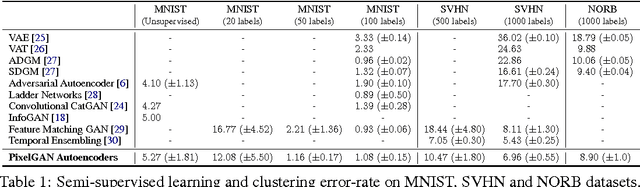

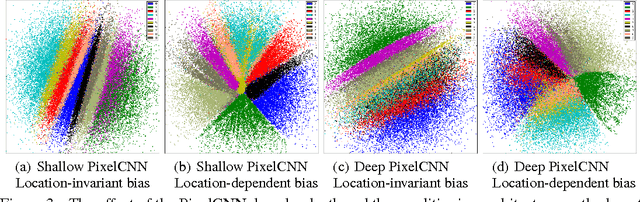
In this paper, we describe the "PixelGAN autoencoder", a generative autoencoder in which the generative path is a convolutional autoregressive neural network on pixels (PixelCNN) that is conditioned on a latent code, and the recognition path uses a generative adversarial network (GAN) to impose a prior distribution on the latent code. We show that different priors result in different decompositions of information between the latent code and the autoregressive decoder. For example, by imposing a Gaussian distribution as the prior, we can achieve a global vs. local decomposition, or by imposing a categorical distribution as the prior, we can disentangle the style and content information of images in an unsupervised fashion. We further show how the PixelGAN autoencoder with a categorical prior can be directly used in semi-supervised settings and achieve competitive semi-supervised classification results on the MNIST, SVHN and NORB datasets.
Adversarial Autoencoders
May 25, 2016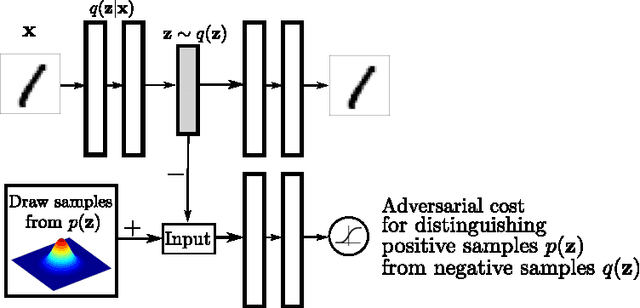
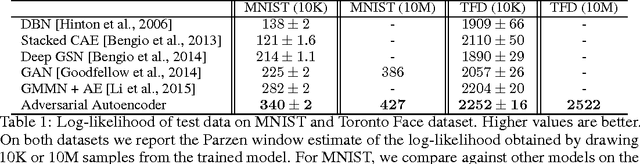
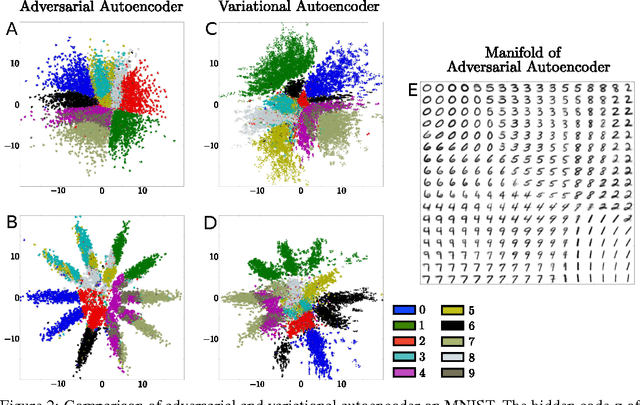
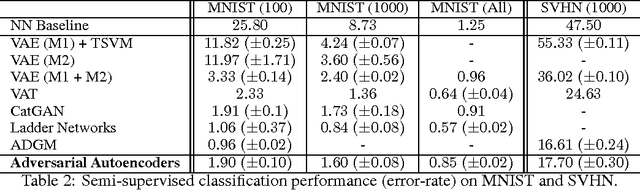
In this paper, we propose the "adversarial autoencoder" (AAE), which is a probabilistic autoencoder that uses the recently proposed generative adversarial networks (GAN) to perform variational inference by matching the aggregated posterior of the hidden code vector of the autoencoder with an arbitrary prior distribution. Matching the aggregated posterior to the prior ensures that generating from any part of prior space results in meaningful samples. As a result, the decoder of the adversarial autoencoder learns a deep generative model that maps the imposed prior to the data distribution. We show how the adversarial autoencoder can be used in applications such as semi-supervised classification, disentangling style and content of images, unsupervised clustering, dimensionality reduction and data visualization. We performed experiments on MNIST, Street View House Numbers and Toronto Face datasets and show that adversarial autoencoders achieve competitive results in generative modeling and semi-supervised classification tasks.
Classifying and Segmenting Microscopy Images Using Convolutional Multiple Instance Learning
Nov 17, 2015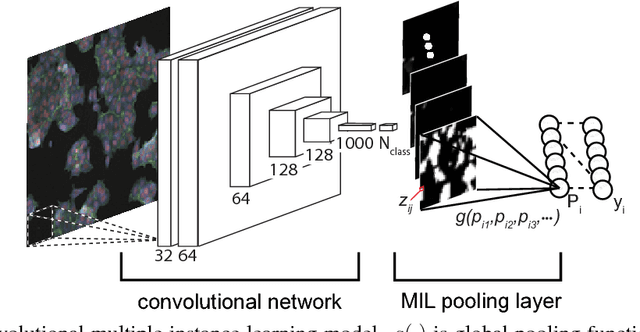
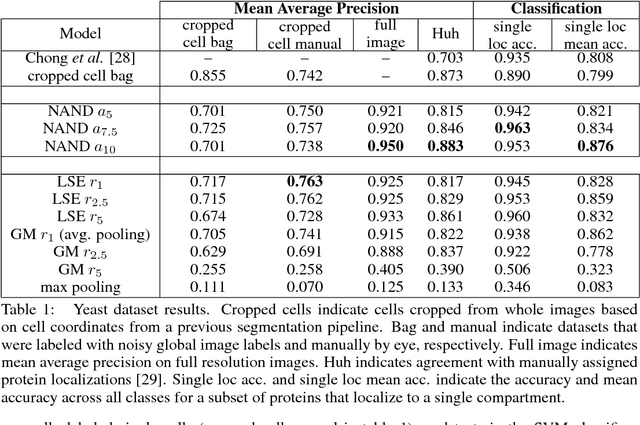
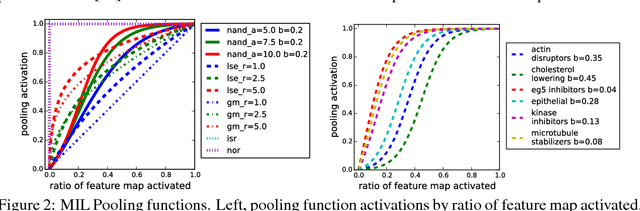
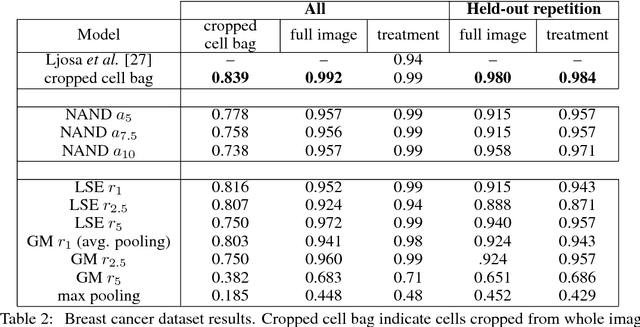
Convolutional neural networks (CNN) have achieved state of the art performance on both classification and segmentation tasks. Applying CNNs to microscopy images is challenging due to the lack of datasets labeled at the single cell level. We extend the application of CNNs to microscopy image classification and segmentation using multiple instance learning (MIL). We present the adaptive Noisy-AND MIL pooling function, a new MIL operator that is robust to outliers. Combining CNNs with MIL enables training CNNs using full resolution microscopy images with global labels. We base our approach on the similarity between the aggregation function used in MIL and pooling layers used in CNNs. We show that training MIL CNNs end-to-end outperforms several previous methods on both mammalian and yeast microscopy images without requiring any segmentation steps.
Learning Wake-Sleep Recurrent Attention Models
Sep 22, 2015

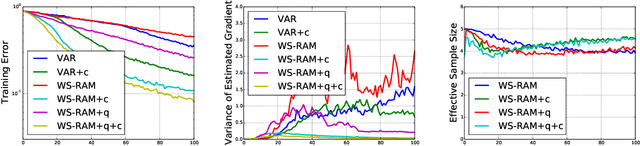

Despite their success, convolutional neural networks are computationally expensive because they must examine all image locations. Stochastic attention-based models have been shown to improve computational efficiency at test time, but they remain difficult to train because of intractable posterior inference and high variance in the stochastic gradient estimates. Borrowing techniques from the literature on training deep generative models, we present the Wake-Sleep Recurrent Attention Model, a method for training stochastic attention networks which improves posterior inference and which reduces the variability in the stochastic gradients. We show that our method can greatly speed up the training time for stochastic attention networks in the domains of image classification and caption generation.
Winner-Take-All Autoencoders
Jun 07, 2015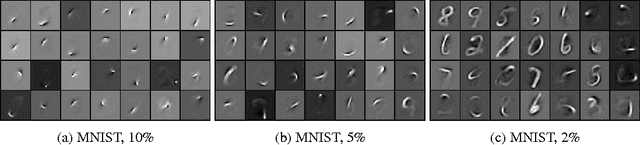


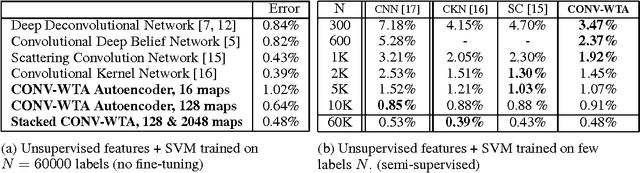
In this paper, we propose a winner-take-all method for learning hierarchical sparse representations in an unsupervised fashion. We first introduce fully-connected winner-take-all autoencoders which use mini-batch statistics to directly enforce a lifetime sparsity in the activations of the hidden units. We then propose the convolutional winner-take-all autoencoder which combines the benefits of convolutional architectures and autoencoders for learning shift-invariant sparse representations. We describe a way to train convolutional autoencoders layer by layer, where in addition to lifetime sparsity, a spatial sparsity within each feature map is achieved using winner-take-all activation functions. We will show that winner-take-all autoencoders can be used to to learn deep sparse representations from the MNIST, CIFAR-10, ImageNet, Street View House Numbers and Toronto Face datasets, and achieve competitive classification performance.
Training Restricted Boltzmann Machine by Perturbation
May 06, 2014A new approach to maximum likelihood learning of discrete graphical models and RBM in particular is introduced. Our method, Perturb and Descend (PD) is inspired by two ideas (I) perturb and MAP method for sampling (II) learning by Contrastive Divergence minimization. In contrast to perturb and MAP, PD leverages training data to learn the models that do not allow efficient MAP estimation. During the learning, to produce a sample from the current model, we start from a training data and descend in the energy landscape of the "perturbed model", for a fixed number of steps, or until a local optima is reached. For RBM, this involves linear calculations and thresholding which can be very fast. Furthermore we show that the amount of perturbation is closely related to the temperature parameter and it can regularize the model by producing robust features resulting in sparse hidden layer activation.
k-Sparse Autoencoders
Mar 22, 2014


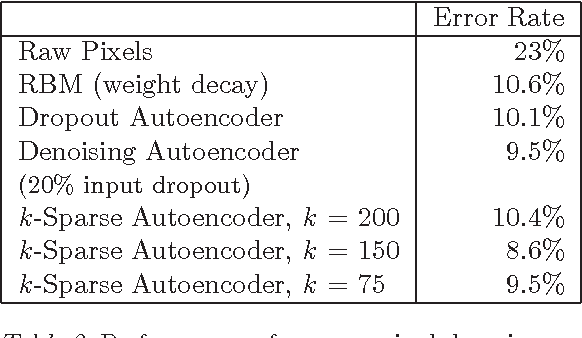
Recently, it has been observed that when representations are learnt in a way that encourages sparsity, improved performance is obtained on classification tasks. These methods involve combinations of activation functions, sampling steps and different kinds of penalties. To investigate the effectiveness of sparsity by itself, we propose the k-sparse autoencoder, which is an autoencoder with linear activation function, where in hidden layers only the k highest activities are kept. When applied to the MNIST and NORB datasets, we find that this method achieves better classification results than denoising autoencoders, networks trained with dropout, and RBMs. k-sparse autoencoders are simple to train and the encoding stage is very fast, making them well-suited to large problem sizes, where conventional sparse coding algorithms cannot be applied.