 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSplicing Up Your Predictions with RNA Contrastive Learning
Paper and Code
Oct 17, 2023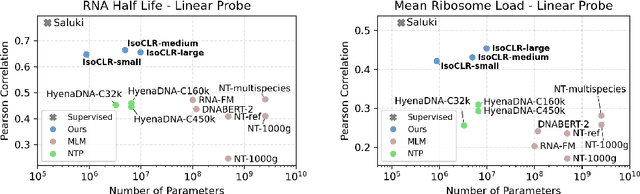

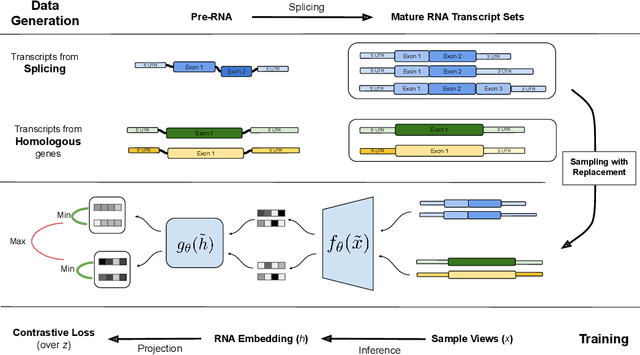
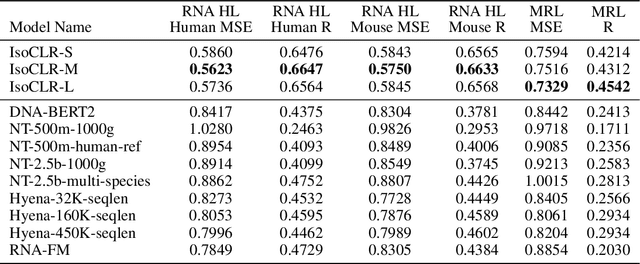
In the face of rapidly accumulating genomic data, our understanding of the RNA regulatory code remains incomplete. Recent self-supervised methods in other domains have demonstrated the ability to learn rules underlying the data-generating process such as sentence structure in language. Inspired by this, we extend contrastive learning techniques to genomic data by utilizing functional similarities between sequences generated through alternative splicing and gene duplication. Our novel dataset and contrastive objective enable the learning of generalized RNA isoform representations. We validate their utility on downstream tasks such as RNA half-life and mean ribosome load prediction. Our pre-training strategy yields competitive results using linear probing on both tasks, along with up to a two-fold increase in Pearson correlation in low-data conditions. Importantly, our exploration of the learned latent space reveals that our contrastive objective yields semantically meaningful representations, underscoring its potential as a valuable initialization technique for RNA property prediction.