 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSAGE: Structured Attribute Value Generation for Billion-Scale Product Catalogs
Sep 12, 2023We introduce SAGE; a Generative LLM for inferring attribute values for products across world-wide e-Commerce catalogs. We introduce a novel formulation of the attribute-value prediction problem as a Seq2Seq summarization task, across languages, product types and target attributes. Our novel modeling approach lifts the restriction of predicting attribute values within a pre-specified set of choices, as well as, the requirement that the sought attribute values need to be explicitly mentioned in the text. SAGE can infer attribute values even when such values are mentioned implicitly using periphrastic language, or not-at-all-as is the case for common-sense defaults. Additionally, SAGE is capable of predicting whether an attribute is inapplicable for the product at hand, or non-obtainable from the available information. SAGE is the first method able to tackle all aspects of the attribute-value-prediction task as they arise in practical settings in e-Commerce catalogs. A comprehensive set of experiments demonstrates the effectiveness of the proposed approach, as well as, its superiority against state-of-the-art competing alternatives. Moreover, our experiments highlight SAGE's ability to tackle the task of predicting attribute values in zero-shot setting; thereby, opening up opportunities for significantly reducing the overall number of labeled examples required for training.
Trust your neighbors: A comprehensive survey of neighborhood-based methods for recommender systems
Sep 09, 2021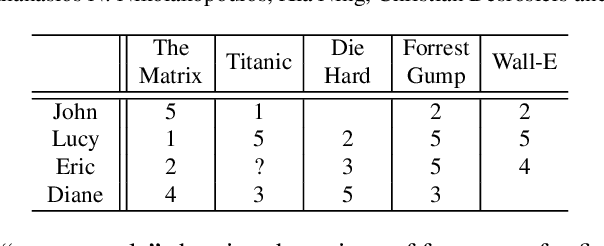
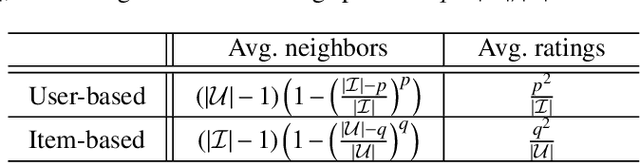
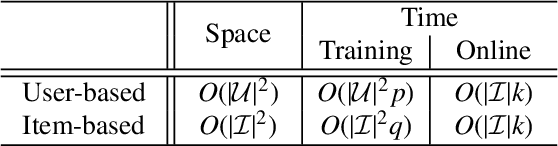
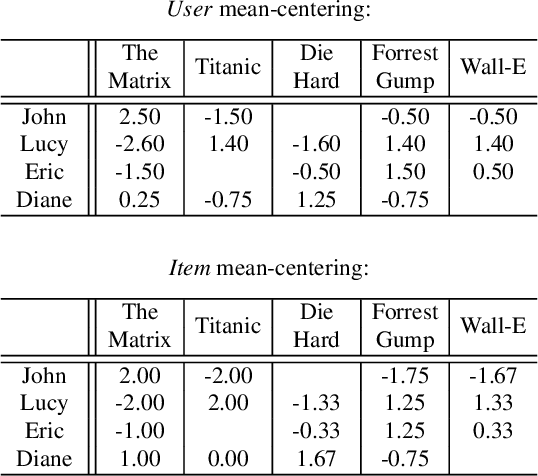
Collaborative recommendation approaches based on nearest-neighbors are still highly popular today due to their simplicity, their efficiency, and their ability to produce accurate and personalized recommendations. This chapter offers a comprehensive survey of neighborhood-based methods for the item recommendation problem. It presents the main characteristics and benefits of such methods, describes key design choices for implementing a neighborhood-based recommender system, and gives practical information on how to make these choices. A broad range of methods is covered in the chapter, including traditional algorithms like k-nearest neighbors as well as advanced approaches based on matrix factorization, sparse coding and random walks.
Projection techniques to update the truncated SVD of evolving matrices
Oct 13, 2020
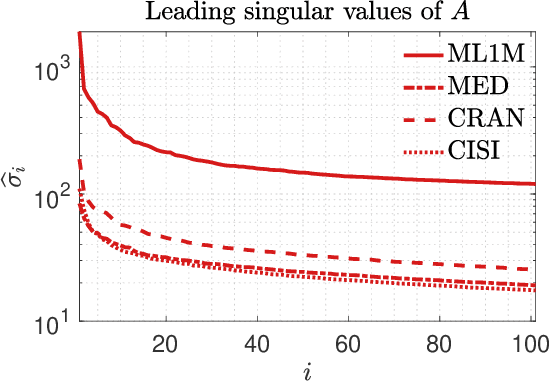
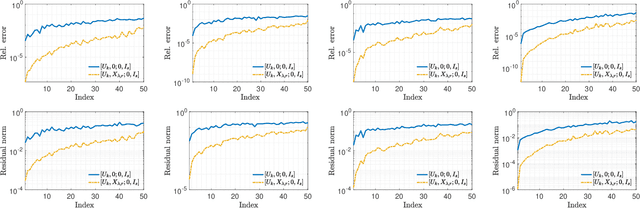
This paper considers the problem of updating the rank-k truncated Singular Value Decomposition (SVD) of matrices subject to the addition of new rows and/or columns over time. Such matrix problems represent an important computational kernel in applications such as Latent Semantic Indexing and Recommender Systems. Nonetheless, the proposed framework is purely algebraic and targets general updating problems. The algorithm presented in this paper undertakes a projection view-point and focuses on building a pair of subspaces which approximate the linear span of the sought singular vectors of the updated matrix. We discuss and analyze two different choices to form the projection subspaces. Results on matrices from real applications suggest that the proposed algorithm can lead to higher accuracy, especially for the singular triplets associated with the largest modulus singular values. Several practical details and key differences with other approaches are also discussed.
Random Surfing Revisited: Generalizing PageRank's Teleportation Model
Sep 01, 2020



We revisit the Random Surfer model, focusing on its--often overlooked--Teleportation component, and we introduce NCDawareRank; a novel ranking framework designed to exploit network meta-information as well as aspects of its higher-order structural organization in a way that preserves the mathematical structure and the attractive computational characteristics of PageRank. A rigorous theoretical exploration of the proposed model reveals a wealth of mathematical properties that entail tangible benefits in terms of robustness, computability, as well as modeling flexibility and expressiveness. A set of experiments on real-work networks verify the theoretically predicted properties of NCDawareRank, and showcase its effectiveness as a network centrality measure.
Adaptive Diffusions for Scalable Learning over Graphs
Sep 05, 2018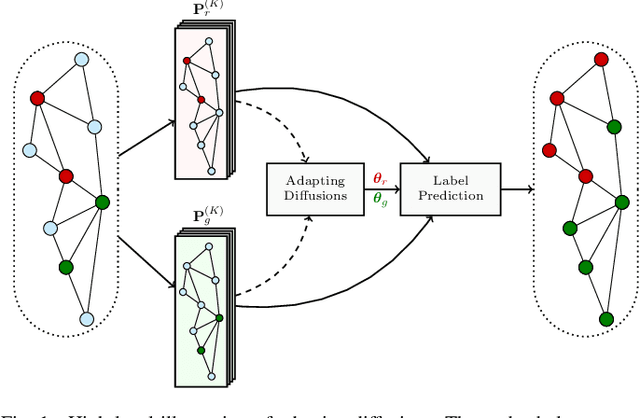
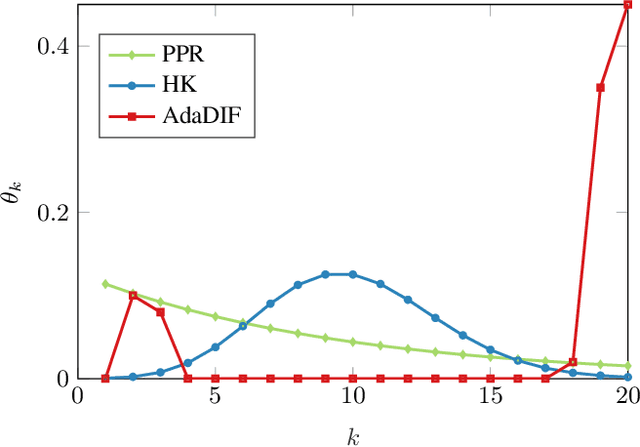
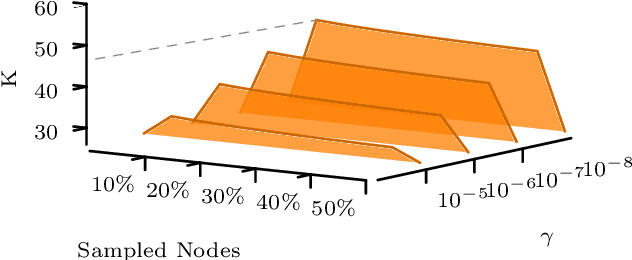
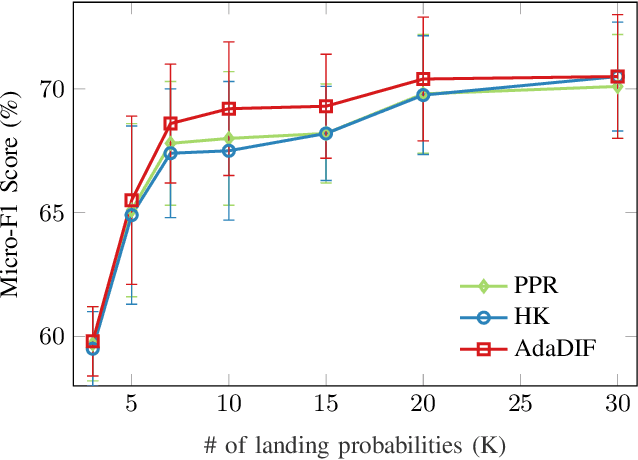
Diffusion-based classifiers such as those relying on the Personalized PageRank and the Heat kernel, enjoy remarkable classification accuracy at modest computational requirements. Their performance however is affected by the extent to which the chosen diffusion captures a typically unknown label propagation mechanism, that can be specific to the underlying graph, and potentially different for each class. The present work introduces a disciplined, data-efficient approach to learning class-specific diffusion functions adapted to the underlying network topology. The novel learning approach leverages the notion of "landing probabilities" of class-specific random walks, which can be computed efficiently, thereby ensuring scalability to large graphs. This is supported by rigorous analysis of the properties of the model as well as the proposed algorithms. Furthermore, a robust version of the classifier facilitates learning even in noisy environments. Classification tests on real networks demonstrate that adapting the diffusion function to the given graph and observed labels, significantly improves the performance over fixed diffusions; reaching -- and many times surpassing -- the classification accuracy of computationally heavier state-of-the-art competing methods, that rely on node embeddings and deep neural networks.
Kernel-based Inference of Functions over Graphs
Apr 10, 2018
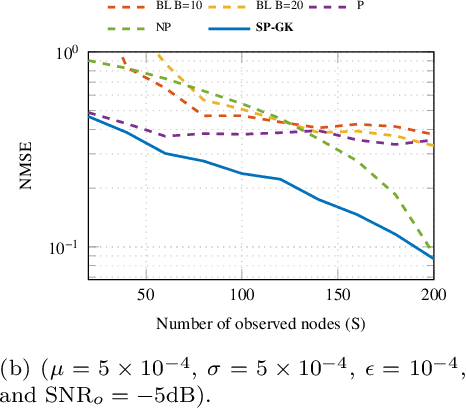
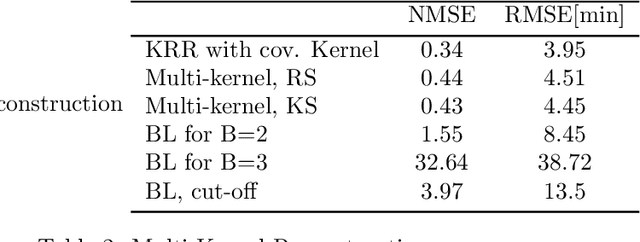
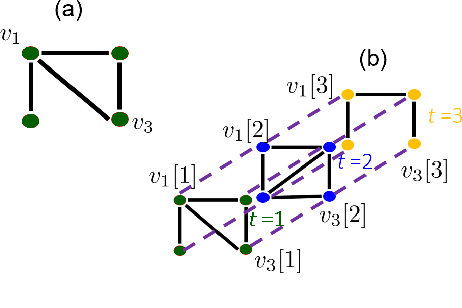
The study of networks has witnessed an explosive growth over the past decades with several ground-breaking methods introduced. A particularly interesting -- and prevalent in several fields of study -- problem is that of inferring a function defined over the nodes of a network. This work presents a versatile kernel-based framework for tackling this inference problem that naturally subsumes and generalizes the reconstruction approaches put forth recently by the signal processing on graphs community. Both the static and the dynamic settings are considered along with effective modeling approaches for addressing real-world problems. The herein analytical discussion is complemented by a set of numerical examples, which showcase the effectiveness of the presented techniques, as well as their merits related to state-of-the-art methods.
Top-N recommendations in the presence of sparsity: An NCD-based approach
Jul 07, 2015



Making recommendations in the presence of sparsity is known to present one of the most challenging problems faced by collaborative filtering methods. In this work we tackle this problem by exploiting the innately hierarchical structure of the item space following an approach inspired by the theory of Decomposability. We view the itemspace as a Nearly Decomposable system and we define blocks of closely related elements and corresponding indirect proximity components. We study the theoretical properties of the decomposition and we derive sufficient conditions that guarantee full item space coverage even in cold-start recommendation scenarios. A comprehensive set of experiments on the MovieLens and the Yahoo!R2Music datasets, using several widely applied performance metrics, support our model's theoretically predicted properties and verify that NCDREC outperforms several state-of-the-art algorithms, in terms of recommendation accuracy, diversity and sparseness insensitivity.