 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust and Fine-Grained Detection of AI Generated Texts
Apr 16, 2025An ideal detection system for machine generated content is supposed to work well on any generator as many more advanced LLMs come into existence day by day. Existing systems often struggle with accurately identifying AI-generated content over shorter texts. Further, not all texts might be entirely authored by a human or LLM, hence we focused more over partial cases i.e human-LLM co-authored texts. Our paper introduces a set of models built for the task of token classification which are trained on an extensive collection of human-machine co-authored texts, which performed well over texts of unseen domains, unseen generators, texts by non-native speakers and those with adversarial inputs. We also introduce a new dataset of over 2.4M such texts mostly co-authored by several popular proprietary LLMs over 23 languages. We also present findings of our models' performance over each texts of each domain and generator. Additional findings include comparison of performance against each adversarial method, length of input texts and characteristics of generated texts compared to the original human authored texts.
SeQwen at the Financial Misinformation Detection Challenge Task: Sequential Learning for Claim Verification and Explanation Generation in Financial Domains
Nov 30, 2024This paper presents the system description of our entry for the COLING 2025 FMD challenge, focusing on misinformation detection in financial domains. We experimented with a combination of large language models, including Qwen, Mistral, and Gemma-2, and leveraged pre-processing and sequential learning for not only identifying fraudulent financial content but also generating coherent, and concise explanations that clarify the rationale behind the classifications. Our approach achieved competitive results with an F1-score of 0.8283 for classification, and ROUGE-1 of 0.7253 for explanations. This work highlights the transformative potential of LLMs in financial applications, offering insights into their capabilities for combating misinformation and enhancing transparency while identifying areas for future improvement in robustness and domain adaptation.
All Languages Matter: Evaluating LMMs on Culturally Diverse 100 Languages
Nov 25, 2024



Existing Large Multimodal Models (LMMs) generally focus on only a few regions and languages. As LMMs continue to improve, it is increasingly important to ensure they understand cultural contexts, respect local sensitivities, and support low-resource languages, all while effectively integrating corresponding visual cues. In pursuit of culturally diverse global multimodal models, our proposed All Languages Matter Benchmark (ALM-bench) represents the largest and most comprehensive effort to date for evaluating LMMs across 100 languages. ALM-bench challenges existing models by testing their ability to understand and reason about culturally diverse images paired with text in various languages, including many low-resource languages traditionally underrepresented in LMM research. The benchmark offers a robust and nuanced evaluation framework featuring various question formats, including true/false, multiple choice, and open-ended questions, which are further divided into short and long-answer categories. ALM-bench design ensures a comprehensive assessment of a model's ability to handle varied levels of difficulty in visual and linguistic reasoning. To capture the rich tapestry of global cultures, ALM-bench carefully curates content from 13 distinct cultural aspects, ranging from traditions and rituals to famous personalities and celebrations. Through this, ALM-bench not only provides a rigorous testing ground for state-of-the-art open and closed-source LMMs but also highlights the importance of cultural and linguistic inclusivity, encouraging the development of models that can serve diverse global populations effectively. Our benchmark is publicly available.
1-800-SHARED-TASKS @ NLU of Devanagari Script Languages: Detection of Language, Hate Speech, and Targets using LLMs
Nov 11, 2024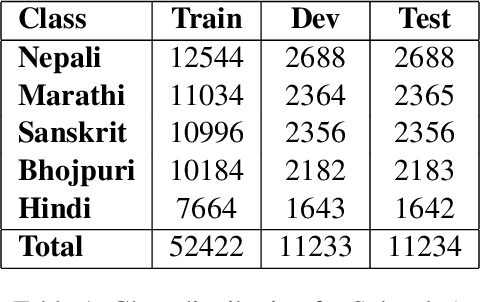
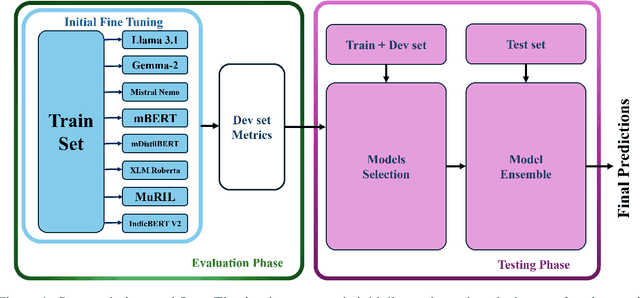
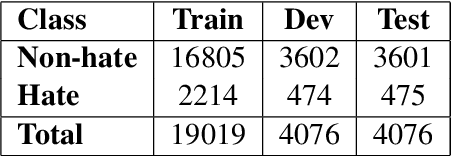
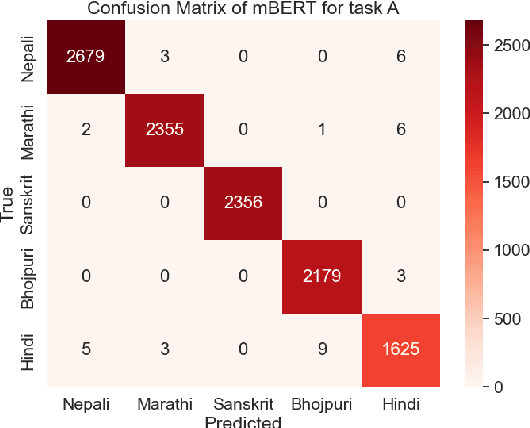
This paper presents a detailed system description of our entry for the CHiPSAL 2025 shared task, focusing on language detection, hate speech identification, and target detection in Devanagari script languages. We experimented with a combination of large language models and their ensembles, including MuRIL, IndicBERT, and Gemma-2, and leveraged unique techniques like focal loss to address challenges in the natural understanding of Devanagari languages, such as multilingual processing and class imbalance. Our approach achieved competitive results across all tasks: F1 of 0.9980, 0.7652, and 0.6804 for Sub-tasks A, B, and C respectively. This work provides insights into the effectiveness of transformer models in tasks with domain-specific and linguistic challenges, as well as areas for potential improvement in future iterations.
Augmenting Legal Decision Support Systems with LLM-based NLI for Analyzing Social Media Evidence
Oct 21, 2024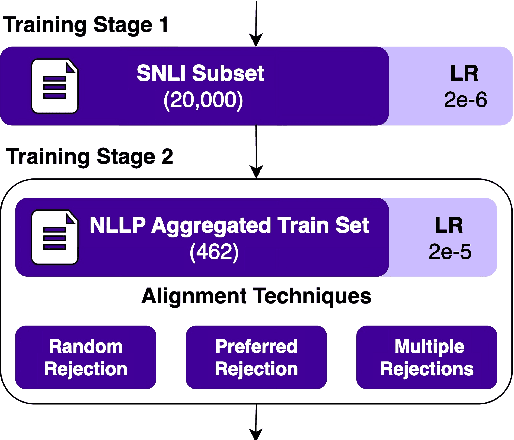


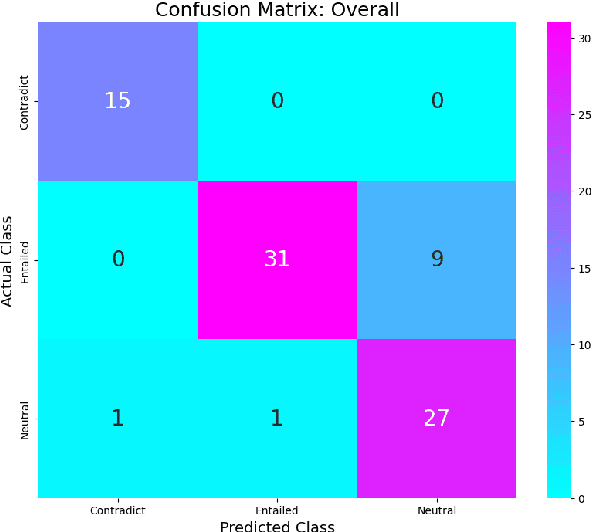
This paper presents our system description and error analysis of our entry for NLLP 2024 shared task on Legal Natural Language Inference (L-NLI) \citep{hagag2024legallenssharedtask2024}. The task required classifying these relationships as entailed, contradicted, or neutral, indicating any association between the review and the complaint. Our system emerged as the winning submission, significantly outperforming other entries with a substantial margin and demonstrating the effectiveness of our approach in legal text analysis. We provide a detailed analysis of the strengths and limitations of each model and approach tested, along with a thorough error analysis and suggestions for future improvements. This paper aims to contribute to the growing field of legal NLP by offering insights into advanced techniques for natural language inference in legal contexts, making it accessible to both experts and newcomers in the field.
The Prompt Report: A Systematic Survey of Prompting Techniques
Jun 06, 2024Generative Artificial Intelligence (GenAI) systems are being increasingly deployed across all parts of industry and research settings. Developers and end users interact with these systems through the use of prompting or prompt engineering. While prompting is a widespread and highly researched concept, there exists conflicting terminology and a poor ontological understanding of what constitutes a prompt due to the area's nascency. This paper establishes a structured understanding of prompts, by assembling a taxonomy of prompting techniques and analyzing their use. We present a comprehensive vocabulary of 33 vocabulary terms, a taxonomy of 58 text-only prompting techniques, and 40 techniques for other modalities. We further present a meta-analysis of the entire literature on natural language prefix-prompting.
Flikcer -- A Chrome Extension to Resolve Online Epileptogenic Visual Content with Real-Time Luminance Frequency Analysis
Aug 21, 2021



Video content with fast luminance variations, or with spatial patterns of high contrast - referred to as epileptogenic visual content - may induce seizures on viewers with photosensitive epilepsy, and even cause discomfort in users not affected by this disease. Flikcer is a web app in the form of a website and chrome extension which aims to resolve epileptic content in videos. It provides the number of possible triggers for a seizure. It also provides the timestamps for these triggers along with a safer version of the video, free to download. The algorithm is written in Python and uses machine learning and computer vision. A key aspect of the algorithm is its computational efficiency, allowing real time implementation for public users.