 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQUAIL: Quantization Aware Unlearning for Mitigating Misinformation in LLMs
Jan 21, 2026Machine unlearning aims to remove specific knowledge (e.g., copyrighted or private data) from a trained model without full retraining. In practice, models are often quantized (e.g., 4-bit) for deployment, but we find that quantization can catastrophically restore forgotten information [1]. In this paper, we (1) analyze why low-bit quantization undermines unlearning, and (2) propose a quantization-aware unlearning method to mitigate this. We first compute weight-change statistics and bucket overlaps in quantization to show that typical unlearning updates are too small to cross quantization thresholds. Building on this insight, we introduce a logits space hinge loss: for each forget example, we force the output logits of the unlearned model to differ from the original model by at least a margin (half the quantization step). This ensures forgotten examples remain distinguishable even after quantization. We evaluate on language and classification tasks (including a Twitter misinformation dataset) and show our method preserves forgetting under 4-bit quantization, whereas existing methods almost entirely recover the forgotten knowledge.
Query Attribute Modeling: Improving search relevance with Semantic Search and Meta Data Filtering
Aug 06, 2025This study introduces Query Attribute Modeling (QAM), a hybrid framework that enhances search precision and relevance by decomposing open text queries into structured metadata tags and semantic elements. QAM addresses traditional search limitations by automatically extracting metadata filters from free-form text queries, reducing noise and enabling focused retrieval of relevant items. Experimental evaluation using the Amazon Toys Reviews dataset (10,000 unique items with 40,000+ reviews and detailed product attributes) demonstrated QAM's superior performance, achieving a mean average precision at 5 (mAP@5) of 52.99\%. This represents significant improvement over conventional methods, including BM25 keyword search, encoder-based semantic similarity search, cross-encoder re-ranking, and hybrid search combining BM25 and semantic results via Reciprocal Rank Fusion (RRF). The results establish QAM as a robust solution for Enterprise Search applications, particularly in e-commerce systems.
Robust and Fine-Grained Detection of AI Generated Texts
Apr 16, 2025An ideal detection system for machine generated content is supposed to work well on any generator as many more advanced LLMs come into existence day by day. Existing systems often struggle with accurately identifying AI-generated content over shorter texts. Further, not all texts might be entirely authored by a human or LLM, hence we focused more over partial cases i.e human-LLM co-authored texts. Our paper introduces a set of models built for the task of token classification which are trained on an extensive collection of human-machine co-authored texts, which performed well over texts of unseen domains, unseen generators, texts by non-native speakers and those with adversarial inputs. We also introduce a new dataset of over 2.4M such texts mostly co-authored by several popular proprietary LLMs over 23 languages. We also present findings of our models' performance over each texts of each domain and generator. Additional findings include comparison of performance against each adversarial method, length of input texts and characteristics of generated texts compared to the original human authored texts.
Improving Multilingual Capabilities with Cultural and Local Knowledge in Large Language Models While Enhancing Native Performance
Apr 13, 2025



Large Language Models (LLMs) have shown remarkable capabilities, but their development has primarily focused on English and other high-resource languages, leaving many languages underserved. We present our latest Hindi-English bi-lingual LLM \textbf{Mantra-14B} with ~3\% average improvement in benchmark scores over both languages, outperforming models twice its size. Using a curated dataset composed of English and Hindi instruction data of 485K samples, we instruction tuned models such as Qwen-2.5-14B-Instruct and Phi-4 to improve performance over both English and Hindi. Our experiments encompassing seven different LLMs of varying parameter sizes and over 140 training attempts with varying English-Hindi training data ratios demonstrated that it is possible to significantly improve multilingual performance without compromising native performance. Further, our approach avoids resource-intensive techniques like vocabulary expansion or architectural modifications, thus keeping the model size small. Our results indicate that modest fine-tuning with culturally and locally informed data can bridge performance gaps without incurring significant computational overhead. We release our training code, datasets, and models under mit and apache licenses to aid further research towards under-represented and low-resource languages.
1-800-SHARED-TASKS @ NLU of Devanagari Script Languages: Detection of Language, Hate Speech, and Targets using LLMs
Nov 11, 2024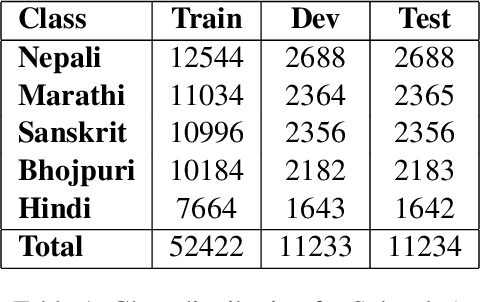
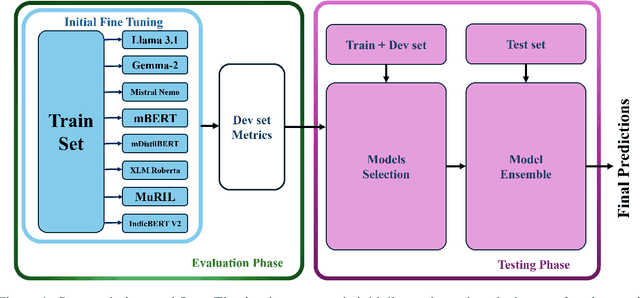
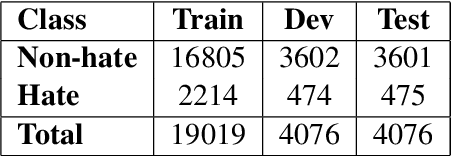
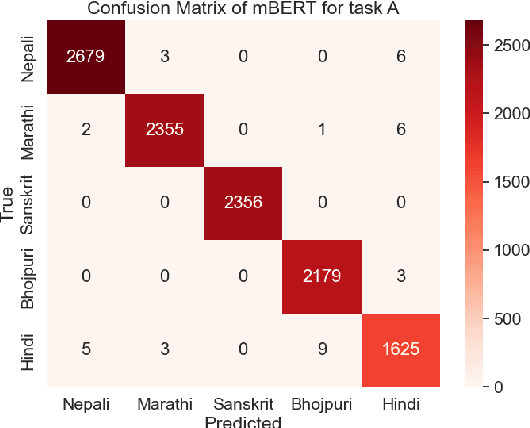
This paper presents a detailed system description of our entry for the CHiPSAL 2025 shared task, focusing on language detection, hate speech identification, and target detection in Devanagari script languages. We experimented with a combination of large language models and their ensembles, including MuRIL, IndicBERT, and Gemma-2, and leveraged unique techniques like focal loss to address challenges in the natural understanding of Devanagari languages, such as multilingual processing and class imbalance. Our approach achieved competitive results across all tasks: F1 of 0.9980, 0.7652, and 0.6804 for Sub-tasks A, B, and C respectively. This work provides insights into the effectiveness of transformer models in tasks with domain-specific and linguistic challenges, as well as areas for potential improvement in future iterations.
Augmenting Legal Decision Support Systems with LLM-based NLI for Analyzing Social Media Evidence
Oct 21, 2024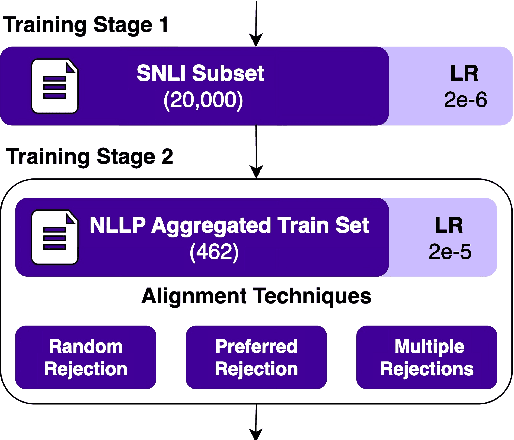


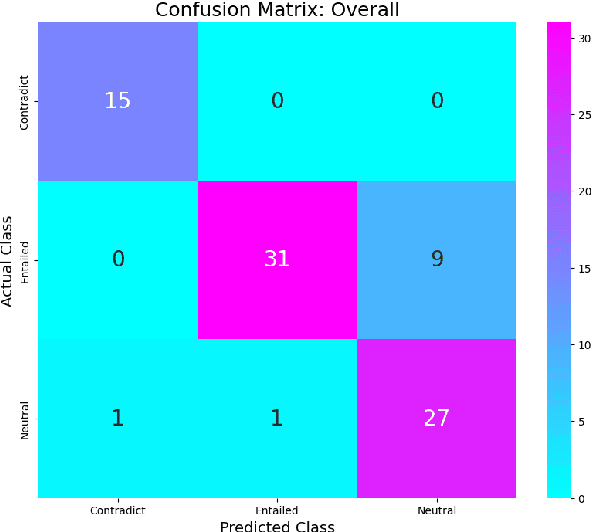
This paper presents our system description and error analysis of our entry for NLLP 2024 shared task on Legal Natural Language Inference (L-NLI) \citep{hagag2024legallenssharedtask2024}. The task required classifying these relationships as entailed, contradicted, or neutral, indicating any association between the review and the complaint. Our system emerged as the winning submission, significantly outperforming other entries with a substantial margin and demonstrating the effectiveness of our approach in legal text analysis. We provide a detailed analysis of the strengths and limitations of each model and approach tested, along with a thorough error analysis and suggestions for future improvements. This paper aims to contribute to the growing field of legal NLP by offering insights into advanced techniques for natural language inference in legal contexts, making it accessible to both experts and newcomers in the field.