 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuery Attribute Modeling: Improving search relevance with Semantic Search and Meta Data Filtering
Aug 06, 2025This study introduces Query Attribute Modeling (QAM), a hybrid framework that enhances search precision and relevance by decomposing open text queries into structured metadata tags and semantic elements. QAM addresses traditional search limitations by automatically extracting metadata filters from free-form text queries, reducing noise and enabling focused retrieval of relevant items. Experimental evaluation using the Amazon Toys Reviews dataset (10,000 unique items with 40,000+ reviews and detailed product attributes) demonstrated QAM's superior performance, achieving a mean average precision at 5 (mAP@5) of 52.99\%. This represents significant improvement over conventional methods, including BM25 keyword search, encoder-based semantic similarity search, cross-encoder re-ranking, and hybrid search combining BM25 and semantic results via Reciprocal Rank Fusion (RRF). The results establish QAM as a robust solution for Enterprise Search applications, particularly in e-commerce systems.
Uncovering Cultural Representation Disparities in Vision-Language Models
May 22, 2025Vision-Language Models (VLMs) have demonstrated impressive capabilities across a range of tasks, yet concerns about their potential biases exist. This work investigates the extent to which prominent VLMs exhibit cultural biases by evaluating their performance on an image-based country identification task at a country level. Utilizing the geographically diverse Country211 dataset, we probe several large vision language models (VLMs) under various prompting strategies: open-ended questions, multiple-choice questions (MCQs) including challenging setups like multilingual and adversarial settings. Our analysis aims to uncover disparities in model accuracy across different countries and question formats, providing insights into how training data distribution and evaluation methodologies might influence cultural biases in VLMs. The findings highlight significant variations in performance, suggesting that while VLMs possess considerable visual understanding, they inherit biases from their pre-training data and scale that impact their ability to generalize uniformly across diverse global contexts.
Robust and Fine-Grained Detection of AI Generated Texts
Apr 16, 2025An ideal detection system for machine generated content is supposed to work well on any generator as many more advanced LLMs come into existence day by day. Existing systems often struggle with accurately identifying AI-generated content over shorter texts. Further, not all texts might be entirely authored by a human or LLM, hence we focused more over partial cases i.e human-LLM co-authored texts. Our paper introduces a set of models built for the task of token classification which are trained on an extensive collection of human-machine co-authored texts, which performed well over texts of unseen domains, unseen generators, texts by non-native speakers and those with adversarial inputs. We also introduce a new dataset of over 2.4M such texts mostly co-authored by several popular proprietary LLMs over 23 languages. We also present findings of our models' performance over each texts of each domain and generator. Additional findings include comparison of performance against each adversarial method, length of input texts and characteristics of generated texts compared to the original human authored texts.
Improving Multilingual Capabilities with Cultural and Local Knowledge in Large Language Models While Enhancing Native Performance
Apr 13, 2025



Large Language Models (LLMs) have shown remarkable capabilities, but their development has primarily focused on English and other high-resource languages, leaving many languages underserved. We present our latest Hindi-English bi-lingual LLM \textbf{Mantra-14B} with ~3\% average improvement in benchmark scores over both languages, outperforming models twice its size. Using a curated dataset composed of English and Hindi instruction data of 485K samples, we instruction tuned models such as Qwen-2.5-14B-Instruct and Phi-4 to improve performance over both English and Hindi. Our experiments encompassing seven different LLMs of varying parameter sizes and over 140 training attempts with varying English-Hindi training data ratios demonstrated that it is possible to significantly improve multilingual performance without compromising native performance. Further, our approach avoids resource-intensive techniques like vocabulary expansion or architectural modifications, thus keeping the model size small. Our results indicate that modest fine-tuning with culturally and locally informed data can bridge performance gaps without incurring significant computational overhead. We release our training code, datasets, and models under mit and apache licenses to aid further research towards under-represented and low-resource languages.
Kaleidoscope: In-language Exams for Massively Multilingual Vision Evaluation
Apr 09, 2025The evaluation of vision-language models (VLMs) has mainly relied on English-language benchmarks, leaving significant gaps in both multilingual and multicultural coverage. While multilingual benchmarks have expanded, both in size and languages, many rely on translations of English datasets, failing to capture cultural nuances. In this work, we propose Kaleidoscope, as the most comprehensive exam benchmark to date for the multilingual evaluation of vision-language models. Kaleidoscope is a large-scale, in-language multimodal benchmark designed to evaluate VLMs across diverse languages and visual inputs. Kaleidoscope covers 18 languages and 14 different subjects, amounting to a total of 20,911 multiple-choice questions. Built through an open science collaboration with a diverse group of researchers worldwide, Kaleidoscope ensures linguistic and cultural authenticity. We evaluate top-performing multilingual vision-language models and find that they perform poorly on low-resource languages and in complex multimodal scenarios. Our results highlight the need for progress on culturally inclusive multimodal evaluation frameworks.
1-800-SHARED-TASKS at RegNLP: Lexical Reranking of Semantic Retrieval (LeSeR) for Regulatory Question Answering
Dec 08, 2024



This paper presents the system description of our entry for the COLING 2025 RegNLP RIRAG (Regulatory Information Retrieval and Answer Generation) challenge, focusing on leveraging advanced information retrieval and answer generation techniques in regulatory domains. We experimented with a combination of embedding models, including Stella, BGE, CDE, and Mpnet, and leveraged fine-tuning and reranking for retrieving relevant documents in top ranks. We utilized a novel approach, LeSeR, which achieved competitive results with a recall@10 of 0.8201 and map@10 of 0.6655 for retrievals. This work highlights the transformative potential of natural language processing techniques in regulatory applications, offering insights into their capabilities for implementing a retrieval augmented generation system while identifying areas for future improvement in robustness and domain adaptation.
SeQwen at the Financial Misinformation Detection Challenge Task: Sequential Learning for Claim Verification and Explanation Generation in Financial Domains
Nov 30, 2024This paper presents the system description of our entry for the COLING 2025 FMD challenge, focusing on misinformation detection in financial domains. We experimented with a combination of large language models, including Qwen, Mistral, and Gemma-2, and leveraged pre-processing and sequential learning for not only identifying fraudulent financial content but also generating coherent, and concise explanations that clarify the rationale behind the classifications. Our approach achieved competitive results with an F1-score of 0.8283 for classification, and ROUGE-1 of 0.7253 for explanations. This work highlights the transformative potential of LLMs in financial applications, offering insights into their capabilities for combating misinformation and enhancing transparency while identifying areas for future improvement in robustness and domain adaptation.
1-800-SHARED-TASKS @ NLU of Devanagari Script Languages: Detection of Language, Hate Speech, and Targets using LLMs
Nov 11, 2024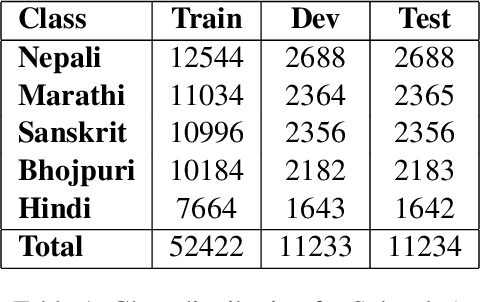
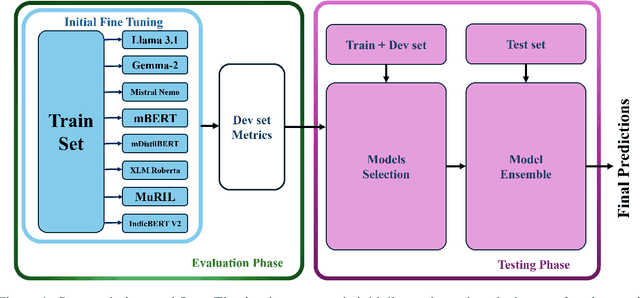
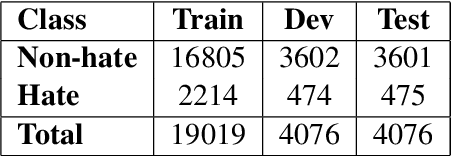
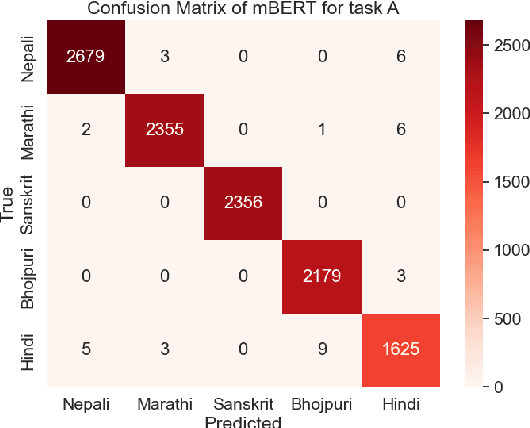
This paper presents a detailed system description of our entry for the CHiPSAL 2025 shared task, focusing on language detection, hate speech identification, and target detection in Devanagari script languages. We experimented with a combination of large language models and their ensembles, including MuRIL, IndicBERT, and Gemma-2, and leveraged unique techniques like focal loss to address challenges in the natural understanding of Devanagari languages, such as multilingual processing and class imbalance. Our approach achieved competitive results across all tasks: F1 of 0.9980, 0.7652, and 0.6804 for Sub-tasks A, B, and C respectively. This work provides insights into the effectiveness of transformer models in tasks with domain-specific and linguistic challenges, as well as areas for potential improvement in future iterations.
RKadiyala at SemEval-2024 Task 8: Black-Box Word-Level Text Boundary Detection in Partially Machine Generated Texts
Oct 22, 2024With increasing usage of generative models for text generation and widespread use of machine generated texts in various domains, being able to distinguish between human written and machine generated texts is a significant challenge. While existing models and proprietary systems focus on identifying whether given text is entirely human written or entirely machine generated, only a few systems provide insights at sentence or paragraph level at likelihood of being machine generated at a non reliable accuracy level, working well only for a set of domains and generators. This paper introduces few reliable approaches for the novel task of identifying which part of a given text is machine generated at a word level while comparing results from different approaches and methods. We present a comparison with proprietary systems , performance of our model on unseen domains' and generators' texts. The findings reveal significant improvements in detection accuracy along with comparison on other aspects of detection capabilities. Finally we discuss potential avenues for improvement and implications of our work. The proposed model is also well suited for detecting which parts of a text are machine generated in outputs of Instruct variants of many LLMs.
Large Language Models for Cross-lingual Emotion Detection
Oct 21, 2024



This paper presents a detailed system description of our entry for the WASSA 2024 Task 2, focused on cross-lingual emotion detection. We utilized a combination of large language models (LLMs) and their ensembles to effectively understand and categorize emotions across different languages. Our approach not only outperformed other submissions with a large margin, but also demonstrated the strength of integrating multiple models to enhance performance. Additionally, We conducted a thorough comparison of the benefits and limitations of each model used. An error analysis is included along with suggested areas for future improvement. This paper aims to offer a clear and comprehensive understanding of advanced techniques in emotion detection, making it accessible even to those new to the field.