 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuery Attribute Modeling: Improving search relevance with Semantic Search and Meta Data Filtering
Aug 06, 2025This study introduces Query Attribute Modeling (QAM), a hybrid framework that enhances search precision and relevance by decomposing open text queries into structured metadata tags and semantic elements. QAM addresses traditional search limitations by automatically extracting metadata filters from free-form text queries, reducing noise and enabling focused retrieval of relevant items. Experimental evaluation using the Amazon Toys Reviews dataset (10,000 unique items with 40,000+ reviews and detailed product attributes) demonstrated QAM's superior performance, achieving a mean average precision at 5 (mAP@5) of 52.99\%. This represents significant improvement over conventional methods, including BM25 keyword search, encoder-based semantic similarity search, cross-encoder re-ranking, and hybrid search combining BM25 and semantic results via Reciprocal Rank Fusion (RRF). The results establish QAM as a robust solution for Enterprise Search applications, particularly in e-commerce systems.
Improving Multilingual Capabilities with Cultural and Local Knowledge in Large Language Models While Enhancing Native Performance
Apr 13, 2025



Large Language Models (LLMs) have shown remarkable capabilities, but their development has primarily focused on English and other high-resource languages, leaving many languages underserved. We present our latest Hindi-English bi-lingual LLM \textbf{Mantra-14B} with ~3\% average improvement in benchmark scores over both languages, outperforming models twice its size. Using a curated dataset composed of English and Hindi instruction data of 485K samples, we instruction tuned models such as Qwen-2.5-14B-Instruct and Phi-4 to improve performance over both English and Hindi. Our experiments encompassing seven different LLMs of varying parameter sizes and over 140 training attempts with varying English-Hindi training data ratios demonstrated that it is possible to significantly improve multilingual performance without compromising native performance. Further, our approach avoids resource-intensive techniques like vocabulary expansion or architectural modifications, thus keeping the model size small. Our results indicate that modest fine-tuning with culturally and locally informed data can bridge performance gaps without incurring significant computational overhead. We release our training code, datasets, and models under mit and apache licenses to aid further research towards under-represented and low-resource languages.
1-800-SHARED-TASKS @ NLU of Devanagari Script Languages: Detection of Language, Hate Speech, and Targets using LLMs
Nov 11, 2024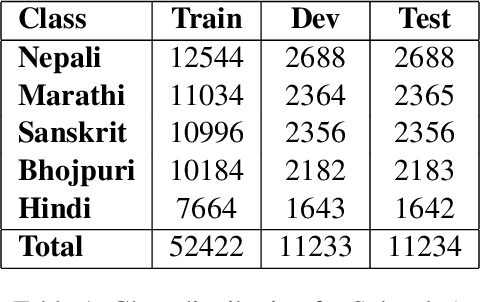
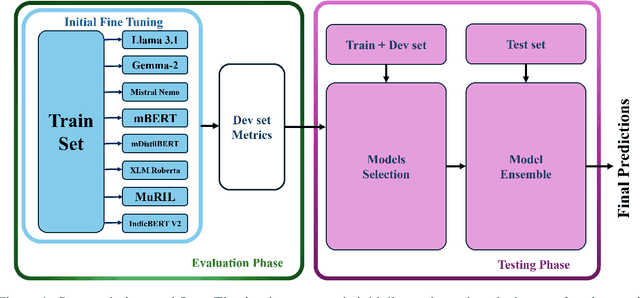
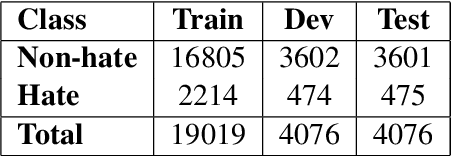
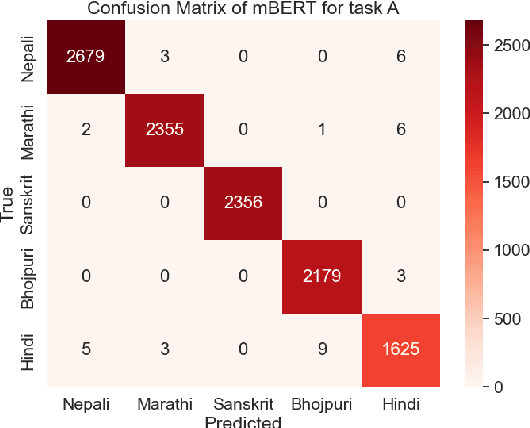
This paper presents a detailed system description of our entry for the CHiPSAL 2025 shared task, focusing on language detection, hate speech identification, and target detection in Devanagari script languages. We experimented with a combination of large language models and their ensembles, including MuRIL, IndicBERT, and Gemma-2, and leveraged unique techniques like focal loss to address challenges in the natural understanding of Devanagari languages, such as multilingual processing and class imbalance. Our approach achieved competitive results across all tasks: F1 of 0.9980, 0.7652, and 0.6804 for Sub-tasks A, B, and C respectively. This work provides insights into the effectiveness of transformer models in tasks with domain-specific and linguistic challenges, as well as areas for potential improvement in future iterations.