 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoFi-Dec: Hallucination-Resistant Decoding via Coarse-to-Fine Generative Feedback in Large Vision-Language Models
Dec 29, 2025Large Vision-Language Models (LVLMs) have achieved impressive progress in multi-modal understanding and generation. However, they still tend to produce hallucinated content that is inconsistent with the visual input, which limits their reliability in real-world applications. We propose \textbf{CoFi-Dec}, a training-free decoding framework that mitigates hallucinations by integrating generative self-feedback with coarse-to-fine visual conditioning. Inspired by the human visual process from global scene perception to detailed inspection, CoFi-Dec first generates two intermediate textual responses conditioned on coarse- and fine-grained views of the original image. These responses are then transformed into synthetic images using a text-to-image model, forming multi-level visual hypotheses that enrich grounding cues. To unify the predictions from these multiple visual conditions, we introduce a Wasserstein-based fusion mechanism that aligns their predictive distributions into a geometrically consistent decoding trajectory. This principled fusion reconciles high-level semantic consistency with fine-grained visual grounding, leading to more robust and faithful outputs. Extensive experiments on six hallucination-focused benchmarks show that CoFi-Dec substantially reduces both entity-level and semantic-level hallucinations, outperforming existing decoding strategies. The framework is model-agnostic, requires no additional training, and can be seamlessly applied to a wide range of LVLMs. The implementation is available at https://github.com/AI-Researcher-Team/CoFi-Dec.
PurifyGen: A Risk-Discrimination and Semantic-Purification Model for Safe Text-to-Image Generation
Dec 29, 2025Recent advances in diffusion models have notably enhanced text-to-image (T2I) generation quality, but they also raise the risk of generating unsafe content. Traditional safety methods like text blacklisting or harmful content classification have significant drawbacks: they can be easily circumvented or require extensive datasets and extra training. To overcome these challenges, we introduce PurifyGen, a novel, training-free approach for safe T2I generation that retains the model's original weights. PurifyGen introduces a dual-stage strategy for prompt purification. First, we evaluate the safety of each token in a prompt by computing its complementary semantic distance, which measures the semantic proximity between the prompt tokens and concept embeddings from predefined toxic and clean lists. This enables fine-grained prompt classification without explicit keyword matching or retraining. Tokens closer to toxic concepts are flagged as risky. Second, for risky prompts, we apply a dual-space transformation: we project toxic-aligned embeddings into the null space of the toxic concept matrix, effectively removing harmful semantic components, and simultaneously align them into the range space of clean concepts. This dual alignment purifies risky prompts by both subtracting unsafe semantics and reinforcing safe ones, while retaining the original intent and coherence. We further define a token-wise strategy to selectively replace only risky token embeddings, ensuring minimal disruption to safe content. PurifyGen offers a plug-and-play solution with theoretical grounding and strong generalization to unseen prompts and models. Extensive testing shows that PurifyGen surpasses current methods in reducing unsafe content across five datasets and competes well with training-dependent approaches. The code can refer to https://github.com/AI-Researcher-Team/PurifyGen.
TV-RAG: A Temporal-aware and Semantic Entropy-Weighted Framework for Long Video Retrieval and Understanding
Dec 29, 2025Large Video Language Models (LVLMs) have rapidly emerged as the focus of multimedia AI research. Nonetheless, when confronted with lengthy videos, these models struggle: their temporal windows are narrow, and they fail to notice fine-grained semantic shifts that unfold over extended durations. Moreover, mainstream text-based retrieval pipelines, which rely chiefly on surface-level lexical overlap, ignore the rich temporal interdependence among visual, audio, and subtitle channels. To mitigate these limitations, we propose TV-RAG, a training-free architecture that couples temporal alignment with entropy-guided semantics to improve long-video reasoning. The framework contributes two main mechanisms: \emph{(i)} a time-decay retrieval module that injects explicit temporal offsets into the similarity computation, thereby ranking text queries according to their true multimedia context; and \emph{(ii)} an entropy-weighted key-frame sampler that selects evenly spaced, information-dense frames, reducing redundancy while preserving representativeness. By weaving these temporal and semantic signals together, TV-RAG realises a dual-level reasoning routine that can be grafted onto any LVLM without re-training or fine-tuning. The resulting system offers a lightweight, budget-friendly upgrade path and consistently surpasses most leading baselines across established long-video benchmarks such as Video-MME, MLVU, and LongVideoBench, confirming the effectiveness of our model. The code can be found at https://github.com/AI-Researcher-Team/TV-RAG.
Part123: Part-aware 3D Reconstruction from a Single-view Image
May 27, 2024



Recently, the emergence of diffusion models has opened up new opportunities for single-view reconstruction. However, all the existing methods represent the target object as a closed mesh devoid of any structural information, thus neglecting the part-based structure, which is crucial for many downstream applications, of the reconstructed shape. Moreover, the generated meshes usually suffer from large noises, unsmooth surfaces, and blurry textures, making it challenging to obtain satisfactory part segments using 3D segmentation techniques. In this paper, we present Part123, a novel framework for part-aware 3D reconstruction from a single-view image. We first use diffusion models to generate multiview-consistent images from a given image, and then leverage Segment Anything Model (SAM), which demonstrates powerful generalization ability on arbitrary objects, to generate multiview segmentation masks. To effectively incorporate 2D part-based information into 3D reconstruction and handle inconsistency, we introduce contrastive learning into a neural rendering framework to learn a part-aware feature space based on the multiview segmentation masks. A clustering-based algorithm is also developed to automatically derive 3D part segmentation results from the reconstructed models. Experiments show that our method can generate 3D models with high-quality segmented parts on various objects. Compared to existing unstructured reconstruction methods, the part-aware 3D models from our method benefit some important applications, including feature-preserving reconstruction, primitive fitting, and 3D shape editing.
Discovering "Semantics" in Super-Resolution Networks
Aug 01, 2021



Super-resolution (SR) is a fundamental and representative task of low-level vision area. It is generally thought that the features extracted from the SR network have no specific semantic information, and the network simply learns complex non-linear mappings from input to output. Can we find any "semantics" in SR networks? In this paper, we give affirmative answers to this question. By analyzing the feature representations with dimensionality reduction and visualization, we successfully discover the deep semantic representations in SR networks, \textit{i.e.}, deep degradation representations (DDR), which relate to the image degradation types and degrees. We also reveal the differences in representation semantics between classification and SR networks. Through extensive experiments and analysis, we draw a series of observations and conclusions, which are of great significance for future work, such as interpreting the intrinsic mechanisms of low-level CNN networks and developing new evaluation approaches for blind SR.
Blind Image Super-Resolution: A Survey and Beyond
Jul 07, 2021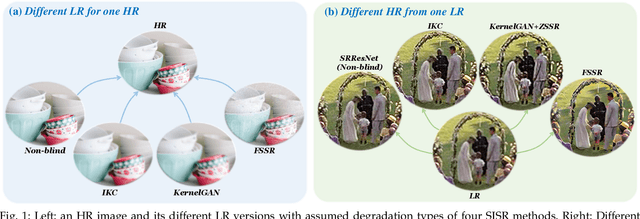



Blind image super-resolution (SR), aiming to super-resolve low-resolution images with unknown degradation, has attracted increasing attention due to its significance in promoting real-world applications. Many novel and effective solutions have been proposed recently, especially with the powerful deep learning techniques. Despite years of efforts, it still remains as a challenging research problem. This paper serves as a systematic review on recent progress in blind image SR, and proposes a taxonomy to categorize existing methods into three different classes according to their ways of degradation modelling and the data used for solving the SR model. This taxonomy helps summarize and distinguish among existing methods. We hope to provide insights into current research states, as well as to reveal novel research directions worth exploring. In addition, we make a summary on commonly used datasets and previous competitions related to blind image SR. Last but not least, a comparison among different methods is provided with detailed analysis on their merits and demerits using both synthetic and real testing images.