 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePitfalls of Assessing Extracted Hierarchies for Multi-Class Classification
Jan 26, 2021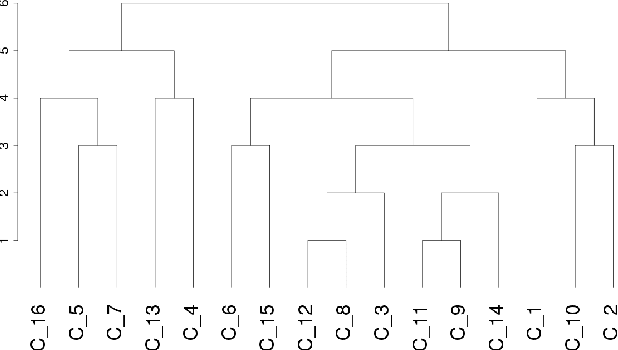
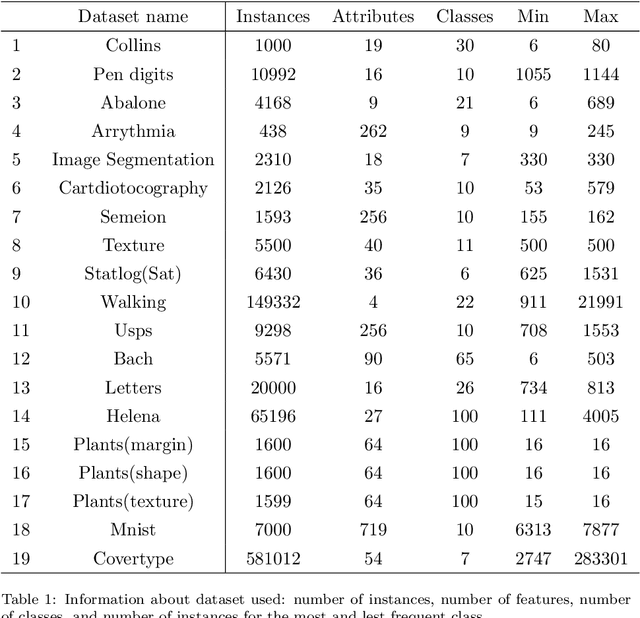
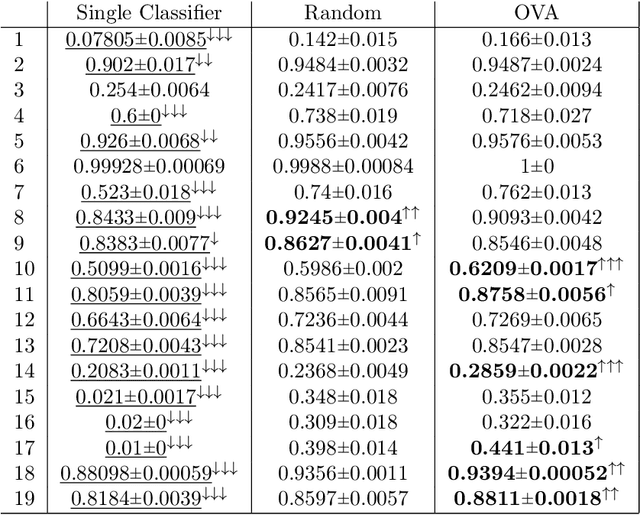
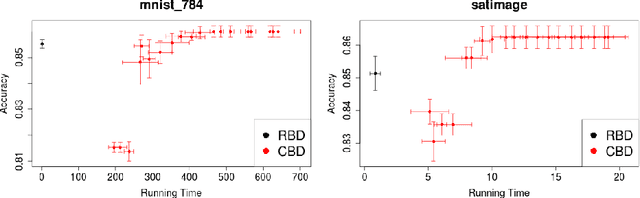
Using hierarchies of classes is one of the standard methods to solve multi-class classification problems. In the literature, selecting the right hierarchy is considered to play a key role in improving classification performance. Although different methods have been proposed, there is still a lack of understanding of what makes one method to extract hierarchies perform better or worse. To this effect, we analyze and compare some of the most popular approaches to extracting hierarchies. We identify some common pitfalls that may lead practitioners to make misleading conclusions about their methods. In addition, to address some of these problems, we demonstrate that using random hierarchies is an appropriate benchmark to assess how the hierarchy's quality affects the classification performance. In particular, we show how the hierarchy's quality can become irrelevant depending on the experimental setup: when using powerful enough classifiers, the final performance is not affected by the quality of the hierarchy. We also show how comparing the effect of the hierarchies against non-hierarchical approaches might incorrectly indicate their superiority. Our results confirm that datasets with a high number of classes generally present complex structures in how these classes relate to each other. In these datasets, the right hierarchy can dramatically improve classification performance.
No Free Lunch But A Cheaper Supper: A General Framework for Streaming Anomaly Detection
Sep 23, 2019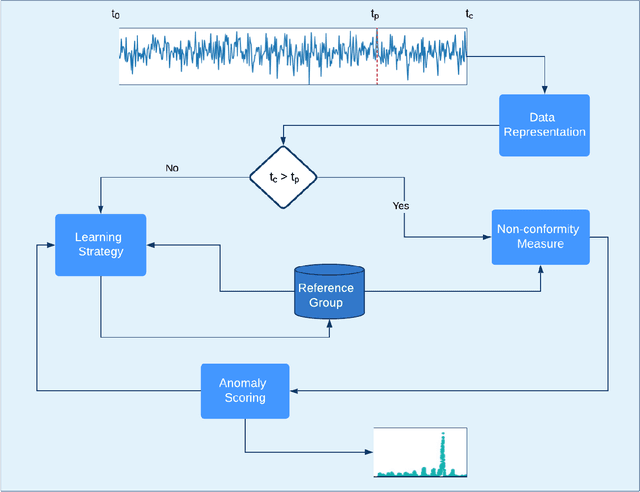
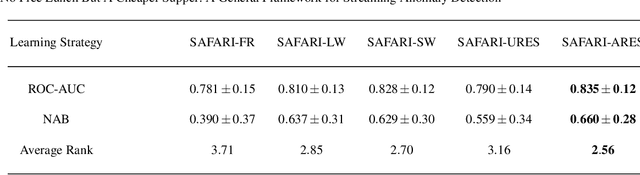
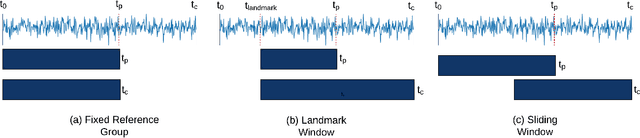
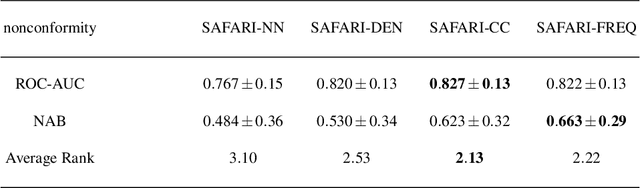
In recent years, there has been increased research interest in detecting anomalies in temporal streaming data. A variety of algorithms have been developed in the data mining community, which can be divided into two categories (i.e., general and ad hoc). In most cases, general approaches assume the one-size-fits-all solution model where a single anomaly detector can detect all anomalies in any domain. To date, there exists no single general method that has been shown to outperform the others across different anomaly types, use cases and datasets. On the other hand, ad hoc approaches that are designed for a specific application lack flexibility. Adapting an existing algorithm is not straightforward if the specific constraints or requirements for the existing task change. In this paper, we propose SAFARI, a general framework formulated by abstracting and unifying the fundamental tasks in streaming anomaly detection, which provides a flexible and extensible anomaly detection procedure. SAFARI helps to facilitate more elaborate algorithm comparisons by allowing us to isolate the effects of shared and unique characteristics of different algorithms on detection performance. Using SAFARI, we have implemented various anomaly detectors and identified a research gap that motivates us to propose a novel learning strategy in this work. We conducted an extensive evaluation study of 20 detectors that are composed using SAFARI and compared their performances using real-world benchmark datasets with different properties. The results indicate that there is no single superior detector that works well for every case, proving our hypothesis that "there is no free lunch" in the streaming anomaly detection world. Finally, we discuss the benefits and drawbacks of each method in-depth and draw a set of conclusions to guide future users of SAFARI.
A Data-Driven Approach for Discovery of Heat Load Patterns in District Heating
Jan 14, 2019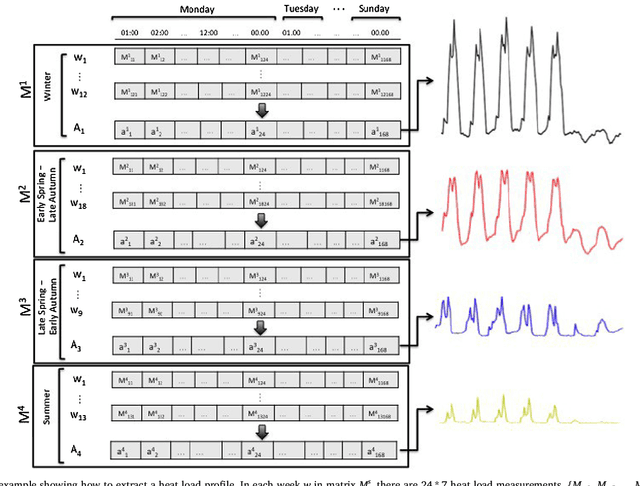
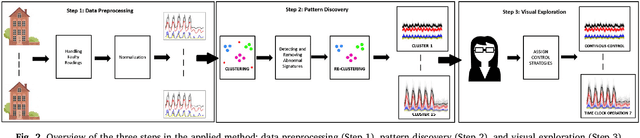
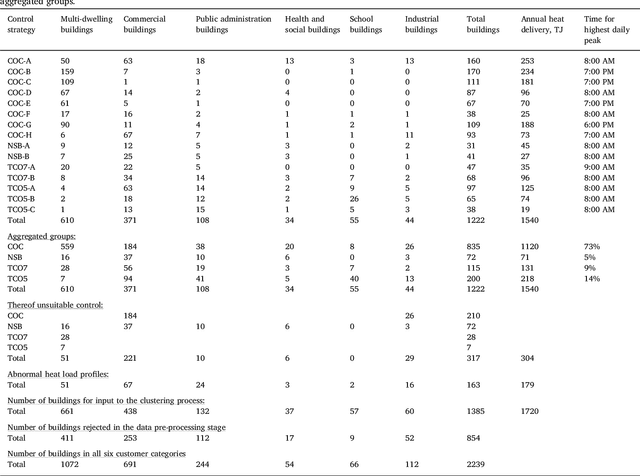
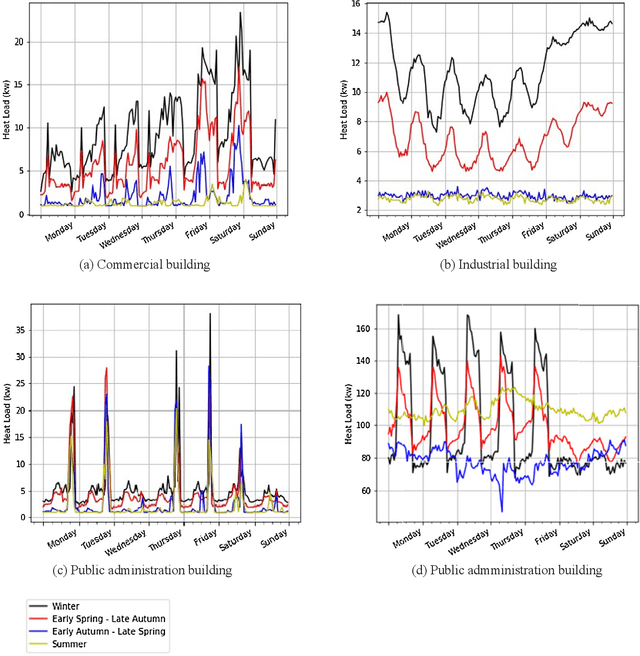
Understanding the heat use of customers is crucial for effective district heating (DH) operations and management. Unfortunately, existing knowledge about customers and their heat load behaviors is quite scarce and very few studies have been focusing on this aspect. The deployment of smart meters offers a unique opportunity for researchers and DH utilities to analyze large-scale data and discover both typical, as well as atypical, patterns in the network. Heat load pattern discovery is a challenging task in DH systems, since a comprehensive analysis needs to involve many customers. Most of the past studies have relied on analysis of a small number of buildings, which are not shown to be picked as the representative examples. Therefore, the knowledge discovered in such studies is not enough to generalize for the entire network. In this work, we propose a data-driven approach that enables automatic discovery of heat load patterns in a complete district heating network. Our method clusters the buildings into different groups based on the characteristics of their load profiles, extracts the representative patterns for each of them, and detects abnormal profiles, i.e., the ones deviating from the expected behavior. We present the first comprehensive analysis of the heat load patterns by conducting a case study on all the buildings, in six customer categories, connected to two district heating networks in the south of Sweden. Our method has captured fifteen typical patterns among the heat load profiles of all buildings in our dataset. It shows that control strategies are not enough to explain the variability in the heat load behaviors. In conclusion, we demonstrate that the proposed approach has a great potential to develop knowledge about customers and their heat use habits in practice by automatically analyzing their typical and atypical profiles in large-scale.
Exploring home robot capabilities by medium fidelity prototyping
Oct 09, 2017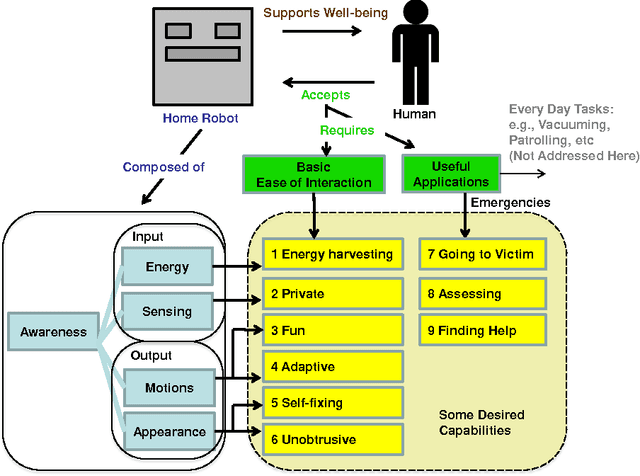
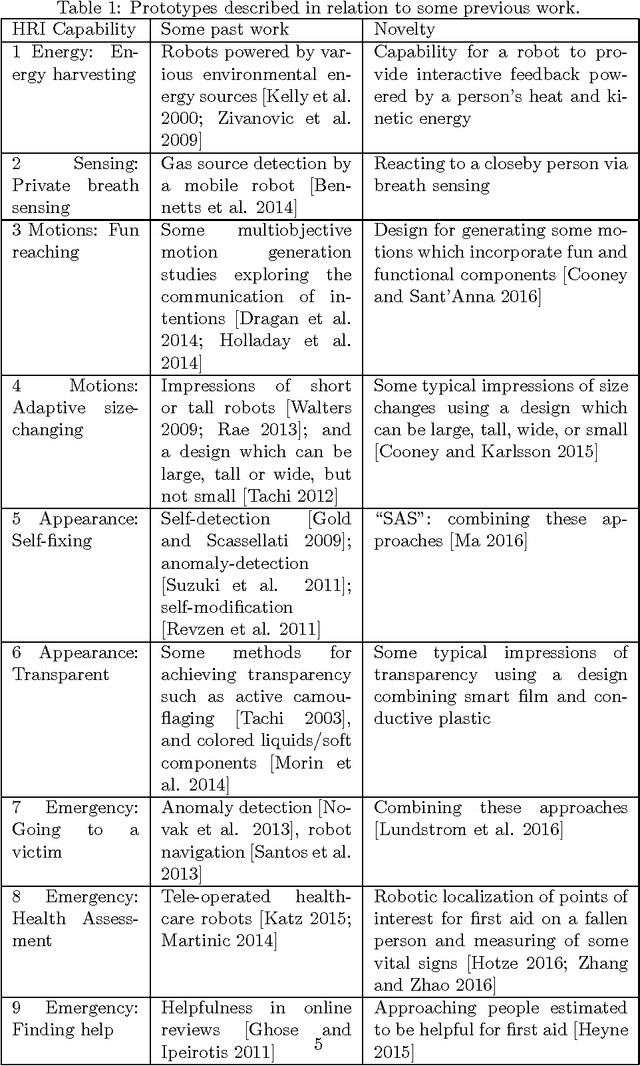
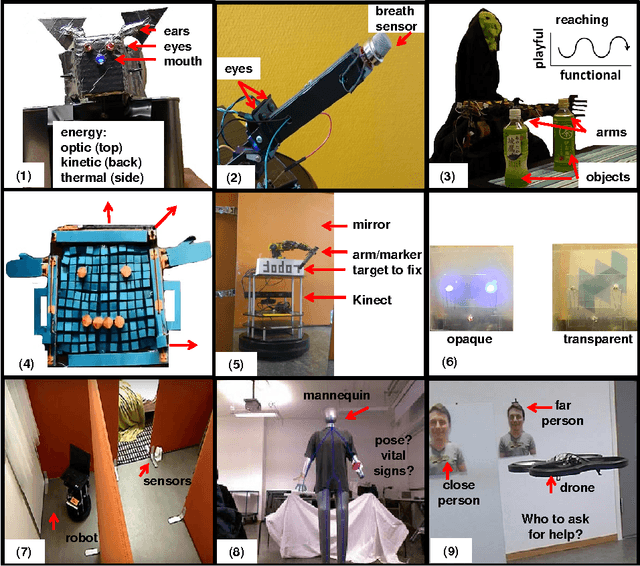

In order for autonomous robots to be able to support people's well-being in homes and everyday environments, new interactive capabilities will be required, as exemplified by the soft design used for Disney's recent robot character Baymax in popular fiction. Home robots will be required to be easy to interact with and intelligent--adaptive, fun, unobtrusive and involving little effort to power and maintain--and capable of carrying out useful tasks both on an everyday level and during emergencies. The current article adopts an exploratory medium fidelity prototyping approach for testing some new robotic capabilities in regard to recognizing people's activities and intentions and behaving in a way which is transparent to people. Results are discussed with the aim of informing next designs.