 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Kernel Posterior Learning under Infinite Variance Prior Weights
Oct 02, 2024Neal (1996) proved that infinitely wide shallow Bayesian neural networks (BNN) converge to Gaussian processes (GP), when the network weights have bounded prior variance. Cho & Saul (2009) provided a useful recursive formula for deep kernel processes for relating the covariance kernel of each layer to the layer immediately below. Moreover, they worked out the form of the layer-wise covariance kernel in an explicit manner for several common activation functions. Recent works, including Aitchison et al. (2021), have highlighted that the covariance kernels obtained in this manner are deterministic and hence, precludes any possibility of representation learning, which amounts to learning a non-degenerate posterior of a random kernel given the data. To address this, they propose adding artificial noise to the kernel to retain stochasticity, and develop deep kernel inverse Wishart processes. Nonetheless, this artificial noise injection could be critiqued in that it would not naturally emerge in a classic BNN architecture under an infinite-width limit. To address this, we show that a Bayesian deep neural network, where each layer width approaches infinity, and all network weights are elliptically distributed with infinite variance, converges to a process with $\alpha$-stable marginals in each layer that has a conditionally Gaussian representation. These conditional random covariance kernels could be recursively linked in the manner of Cho & Saul (2009), even though marginally the process exhibits stable behavior, and hence covariances are not even necessarily defined. We also provide useful generalizations of the recent results of Lor\'ia & Bhadra (2024) on shallow networks to multi-layer networks, and remedy the computational burden of their approach. The computational and statistical benefits over competing approaches stand out in simulations and in demonstrations on benchmark data sets.
Likelihood Based Inference in Fully and Partially Observed Exponential Family Graphical Models with Intractable Normalizing Constants
Apr 27, 2024Probabilistic graphical models that encode an underlying Markov random field are fundamental building blocks of generative modeling to learn latent representations in modern multivariate data sets with complex dependency structures. Among these, the exponential family graphical models are especially popular, given their fairly well-understood statistical properties and computational scalability to high-dimensional data based on pseudo-likelihood methods. These models have been successfully applied in many fields, such as the Ising model in statistical physics and count graphical models in genomics. Another strand of models allows some nodes to be latent, so as to allow the marginal distribution of the observable nodes to depart from exponential family to capture more complex dependence. These approaches form the basis of generative models in artificial intelligence, such as the Boltzmann machines and their restricted versions. A fundamental barrier to likelihood-based (i.e., both maximum likelihood and fully Bayesian) inference in both fully and partially observed cases is the intractability of the likelihood. The usual workaround is via adopting pseudo-likelihood based approaches, following the pioneering work of Besag (1974). The goal of this paper is to demonstrate that full likelihood based analysis of these models is feasible in a computationally efficient manner. The chief innovation lies in using a technique of Geyer (1991) to estimate the intractable normalizing constant, as well as its gradient, for intractable graphical models. Extensive numerical results, supporting theory and comparisons with pseudo-likelihood based approaches demonstrate the applicability of the proposed method.
Posterior Inference on Infinitely Wide Bayesian Neural Networks under Weights with Unbounded Variance
May 18, 2023From the classical and influential works of Neal (1996), it is known that the infinite width scaling limit of a Bayesian neural network with one hidden layer is a Gaussian process, \emph{when the network weights have bounded prior variance}. Neal's result has been extended to networks with multiple hidden layers and to convolutional neural networks, also with Gaussian process scaling limits. The tractable properties of Gaussian processes then allow straightforward posterior inference and uncertainty quantification, considerably simplifying the study of the limit process compared to a network of finite width. Neural network weights with unbounded variance, however, pose unique challenges. In this case, the classical central limit theorem breaks down and it is well known that the scaling limit is an $\alpha$-stable process under suitable conditions. However, current literature is primarily limited to forward simulations under these processes and the problem of posterior inference under such a scaling limit remains largely unaddressed, unlike in the Gaussian process case. To this end, our contribution is an interpretable and computationally efficient procedure for posterior inference, using a \emph{conditionally Gaussian} representation, that then allows full use of the Gaussian process machinery for tractable posterior inference and uncertainty quantification in the non-Gaussian regime.
Merging Two Cultures: Deep and Statistical Learning
Oct 22, 2021



Merging the two cultures of deep and statistical learning provides insights into structured high-dimensional data. Traditional statistical modeling is still a dominant strategy for structured tabular data. Deep learning can be viewed through the lens of generalized linear models (GLMs) with composite link functions. Sufficient dimensionality reduction (SDR) and sparsity performs nonlinear feature engineering. We show that prediction, interpolation and uncertainty quantification can be achieved using probabilistic methods at the output layer of the model. Thus a general framework for machine learning arises that first generates nonlinear features (a.k.a factors) via sparse regularization and stochastic gradient optimisation and second uses a stochastic output layer for predictive uncertainty. Rather than using shallow additive architectures as in many statistical models, deep learning uses layers of semi affine input transformations to provide a predictive rule. Applying these layers of transformations leads to a set of attributes (a.k.a features) to which predictive statistical methods can be applied. Thus we achieve the best of both worlds: scalability and fast predictive rule construction together with uncertainty quantification. Sparse regularisation with un-supervised or supervised learning finds the features. We clarify the duality between shallow and wide models such as PCA, PPR, RRR and deep but skinny architectures such as autoencoders, MLPs, CNN, and LSTM. The connection with data transformations is of practical importance for finding good network architectures. By incorporating probabilistic components at the output level we allow for predictive uncertainty. For interpolation we use deep Gaussian process and ReLU trees for classification. We provide applications to regression, classification and interpolation. Finally, we conclude with directions for future research.
Kriging: Beyond Matérn
Nov 14, 2019



The Mat\'ern covariance function is a popular choice for prediction in spatial statistics and uncertainty quantification literature. A key benefit of the Mat\'ern class is that it is possible to get precise control over the degree of differentiability of the process realizations. However, the Mat\'ern class possesses exponentially decaying tails, and thus may not be suitable for modeling long range dependence. This problem can be remedied using polynomial covariances; however one loses control over the degree of differentiability of the process realizations, in that the realizations using polynomial covariances are either infinitely differentiable or not differentiable at all. We construct a new family of covariance functions using a scale mixture representation of the Mat\'ern class where one obtains the benefits of both Mat\'ern and polynomial covariances. The resultant covariance contains two parameters: one controls the degree of differentiability near the origin and the other controls the tail heaviness, independently of each other. Using a spectral representation, we derive theoretical properties of this new covariance including equivalence measures and asymptotic behavior of the maximum likelihood estimators under infill asymptotics. The improved theoretical properties in predictive performance of this new covariance class are verified via extensive simulations. Application using NASA's Orbiting Carbon Observatory-2 satellite data confirms the advantage of this new covariance class over the Mat\'ern class, especially in extrapolative settings.
Horseshoe Regularization for Machine Learning in Complex and Deep Models
Apr 24, 2019

Since the advent of the horseshoe priors for regularization, global-local shrinkage methods have proved to be a fertile ground for the development of Bayesian methodology in machine learning, specifically for high-dimensional regression and classification problems. They have achieved remarkable success in computation, and enjoy strong theoretical support. Most of the existing literature has focused on the linear Gaussian case; see Bhadra et al. (2019) for a systematic survey. The purpose of the current article is to demonstrate that the horseshoe regularization is useful far more broadly, by reviewing both methodological and computational developments in complex models that are more relevant to machine learning applications. Specifically, we focus on methodological challenges in horseshoe regularization in nonlinear and non-Gaussian models; multivariate models; and deep neural networks. We also outline the recent computational developments in horseshoe shrinkage for complex models along with a list of available software implementations that allows one to venture out beyond the comfort zone of the canonical linear regression problems.
Divide and Recombine for Large and Complex Data: Model Likelihood Functions using MCMC
Jan 15, 2018
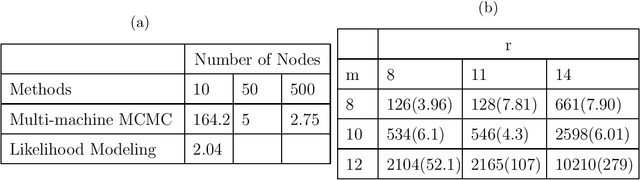

In Divide & Recombine (D&R), big data are divided into subsets, each analytic method is applied to subsets, and the outputs are recombined. This enables deep analysis and practical computational performance. An innovate D\&R procedure is proposed to compute likelihood functions of data-model (DM) parameters for big data. The likelihood-model (LM) is a parametric probability density function of the DM parameters. The density parameters are estimated by fitting the density to MCMC draws from each subset DM likelihood function, and then the fitted densities are recombined. The procedure is illustrated using normal and skew-normal LMs for the logistic regression DM.
Horseshoe Regularization for Feature Subset Selection
Jun 22, 2017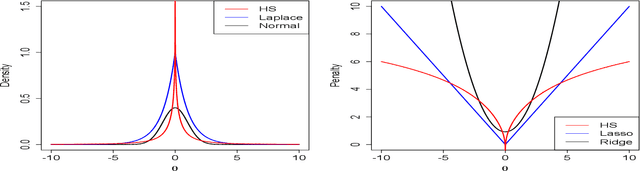
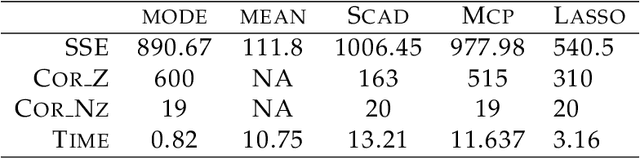
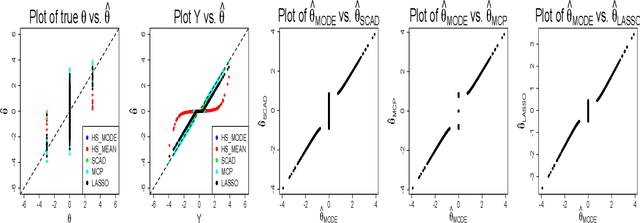
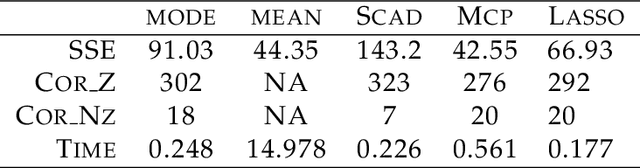
Feature subset selection arises in many high-dimensional applications of statistics, such as compressed sensing and genomics. The $\ell_0$ penalty is ideal for this task, the caveat being it requires the NP-hard combinatorial evaluation of all models. A recent area of considerable interest is to develop efficient algorithms to fit models with a non-convex $\ell_\gamma$ penalty for $\gamma\in (0,1)$, which results in sparser models than the convex $\ell_1$ or lasso penalty, but is harder to fit. We propose an alternative, termed the horseshoe regularization penalty for feature subset selection, and demonstrate its theoretical and computational advantages. The distinguishing feature from existing non-convex optimization approaches is a full probabilistic representation of the penalty as the negative of the logarithm of a suitable prior, which in turn enables efficient expectation-maximization and local linear approximation algorithms for optimization and MCMC for uncertainty quantification. In synthetic and real data, the resulting algorithms provide better statistical performance, and the computation requires a fraction of time of state-of-the-art non-convex solvers.