 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHorseshoe Regularization for Feature Subset Selection
Paper and Code
Jun 22, 2017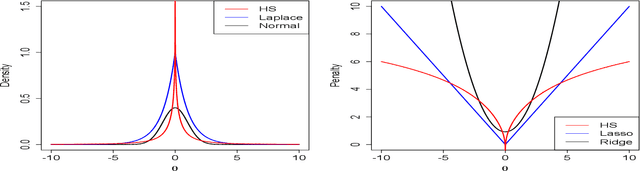
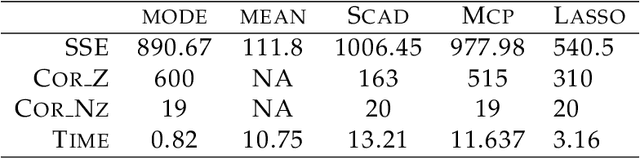
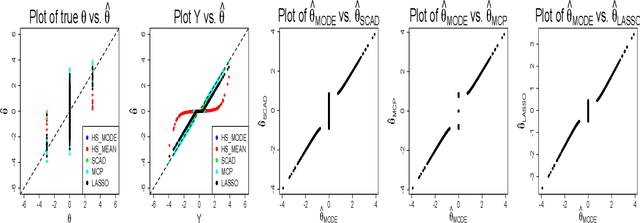
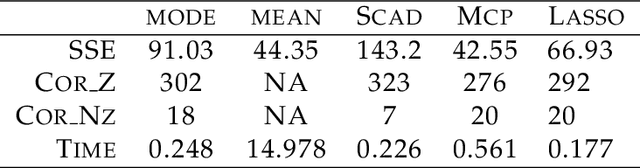
Feature subset selection arises in many high-dimensional applications of statistics, such as compressed sensing and genomics. The $\ell_0$ penalty is ideal for this task, the caveat being it requires the NP-hard combinatorial evaluation of all models. A recent area of considerable interest is to develop efficient algorithms to fit models with a non-convex $\ell_\gamma$ penalty for $\gamma\in (0,1)$, which results in sparser models than the convex $\ell_1$ or lasso penalty, but is harder to fit. We propose an alternative, termed the horseshoe regularization penalty for feature subset selection, and demonstrate its theoretical and computational advantages. The distinguishing feature from existing non-convex optimization approaches is a full probabilistic representation of the penalty as the negative of the logarithm of a suitable prior, which in turn enables efficient expectation-maximization and local linear approximation algorithms for optimization and MCMC for uncertainty quantification. In synthetic and real data, the resulting algorithms provide better statistical performance, and the computation requires a fraction of time of state-of-the-art non-convex solvers.