 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFirst Proof
Feb 05, 2026To assess the ability of current AI systems to correctly answer research-level mathematics questions, we share a set of ten math questions which have arisen naturally in the research process of the authors. The questions had not been shared publicly until now; the answers are known to the authors of the questions but will remain encrypted for a short time.
Discrete scalar curvature as a weighted sum of Ollivier-Ricci curvatures
Oct 06, 2025

We study the relationship between discrete analogues of Ricci and scalar curvature that are defined for point clouds and graphs. In the discrete setting, Ricci curvature is replaced by Ollivier-Ricci curvature. Scalar curvature can be computed as the trace of Ricci curvature for a Riemannian manifold; this motivates a new definition of a scalar version of Ollivier-Ricci curvature. We show that our definition converges to scalar curvature for nearest neighbor graphs obtained by sampling from a manifold. We also prove some new results about the convergence of Ollivier-Ricci curvature to Ricci curvature.
EmbedOR: Provable Cluster-Preserving Visualizations with Curvature-Based Stochastic Neighbor Embeddings
Sep 03, 2025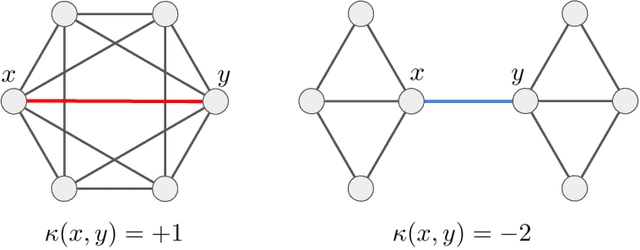
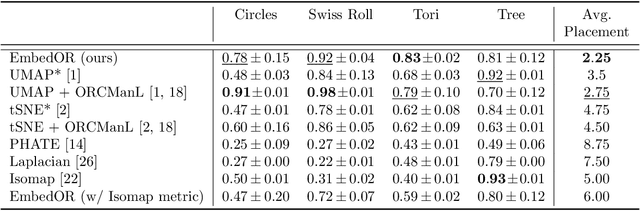


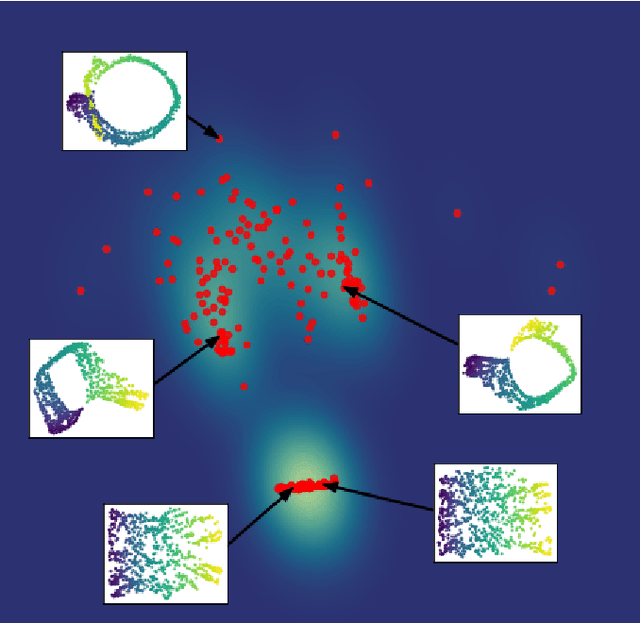
Stochastic Neighbor Embedding (SNE) algorithms like UMAP and tSNE often produce visualizations that do not preserve the geometry of noisy and high dimensional data. In particular, they can spuriously separate connected components of the underlying data submanifold and can fail to find clusters in well-clusterable data. To address these limitations, we propose EmbedOR, a SNE algorithm that incorporates discrete graph curvature. Our algorithm stochastically embeds the data using a curvature-enhanced distance metric that emphasizes underlying cluster structure. Critically, we prove that the EmbedOR distance metric extends consistency results for tSNE to a much broader class of datasets. We also describe extensive experiments on synthetic and real data that demonstrate the visualization and geometry-preservation capabilities of EmbedOR. We find that, unlike other SNE algorithms and UMAP, EmbedOR is much less likely to fragment continuous, high-density regions of the data. Finally, we demonstrate that the EmbedOR distance metric can be used as a tool to annotate existing visualizations to identify fragmentation and provide deeper insight into the underlying geometry of the data.
Subsampling, aligning, and averaging to find circular coordinates in recurrent time series
Dec 24, 2024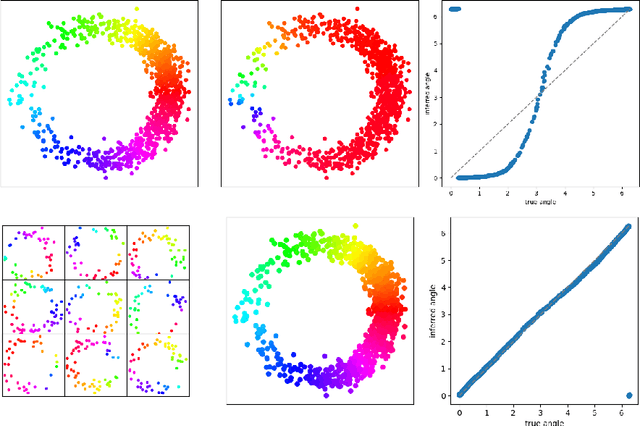
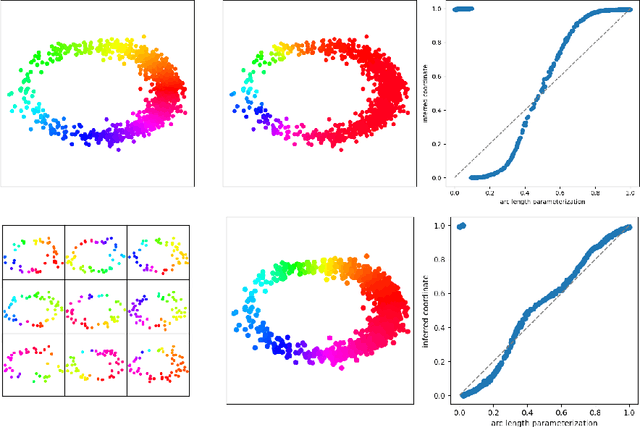
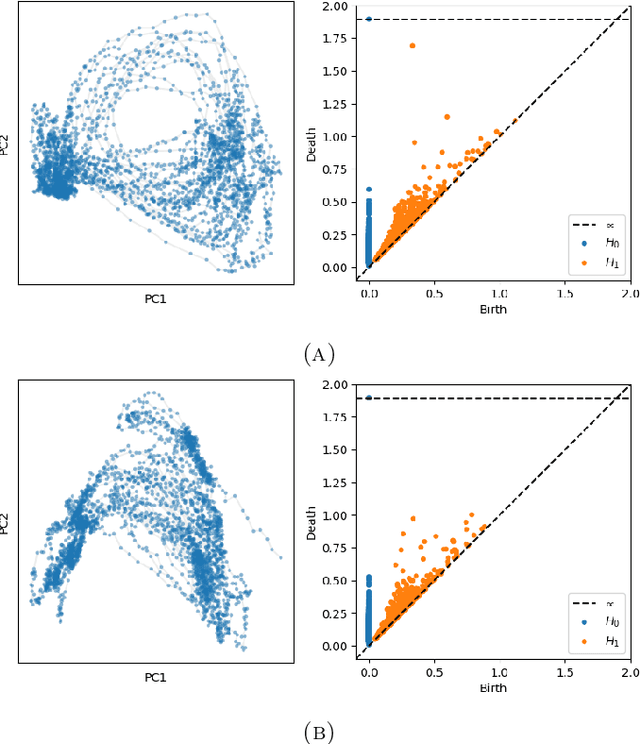
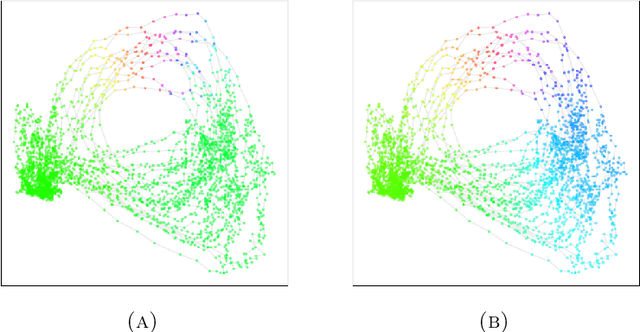
We introduce a new algorithm for finding robust circular coordinates on data that is expected to exhibit recurrence, such as that which appears in neuronal recordings of C. elegans. Techniques exist to create circular coordinates on a simplicial complex from a dimension 1 cohomology class, and these can be applied to the Rips complex of a dataset when it has a prominent class in its dimension 1 cohomology. However, it is known this approach is extremely sensitive to uneven sampling density. Our algorithm comes with a new method to correct for uneven sampling density, adapting our prior work on averaging coordinates in manifold learning. We use rejection sampling to correct for inhomogeneous sampling and then apply Procrustes matching to align and average the subsamples. In addition to providing a more robust coordinate than other approaches, this subsampling and averaging approach has better efficiency. We validate our technique on both synthetic data sets and neuronal activity recordings. Our results reveal a topological model of neuronal trajectories for C. elegans that is constructed from loops in which different regions of the brain state space can be mapped to specific and interpretable macroscopic behaviors in the worm.
Recovering Manifold Structure Using Ollivier-Ricci Curvature
Oct 02, 2024

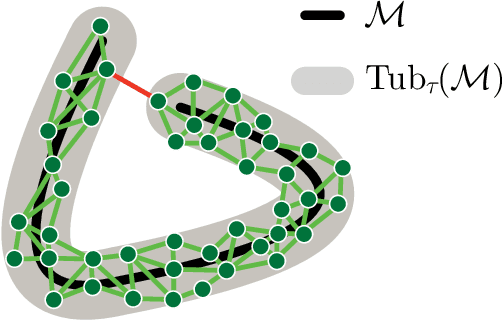

We introduce ORC-ManL, a new algorithm to prune spurious edges from nearest neighbor graphs using a criterion based on Ollivier-Ricci curvature and estimated metric distortion. Our motivation comes from manifold learning: we show that when the data generating the nearest-neighbor graph consists of noisy samples from a low-dimensional manifold, edges that shortcut through the ambient space have more negative Ollivier-Ricci curvature than edges that lie along the data manifold. We demonstrate that our method outperforms alternative pruning methods and that it significantly improves performance on many downstream geometric data analysis tasks that use nearest neighbor graphs as input. Specifically, we evaluate on manifold learning, persistent homology, dimension estimation, and others. We also show that ORC-ManL can be used to improve clustering and manifold learning of single-cell RNA sequencing data. Finally, we provide empirical convergence experiments that support our theoretical findings.
Resampling and averaging coordinates on data
Aug 02, 2024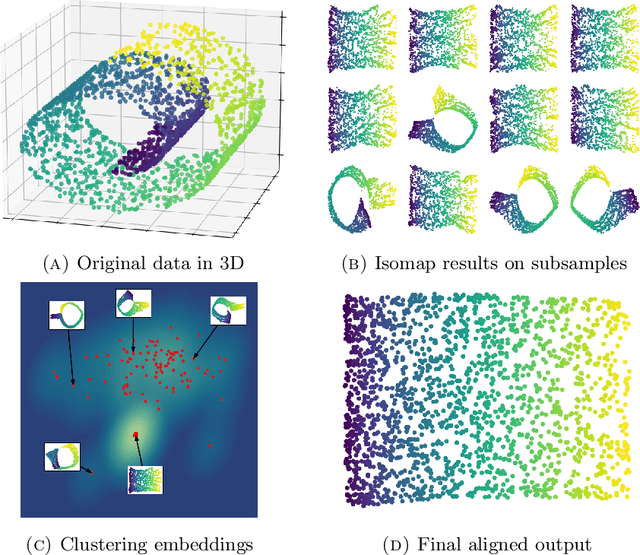
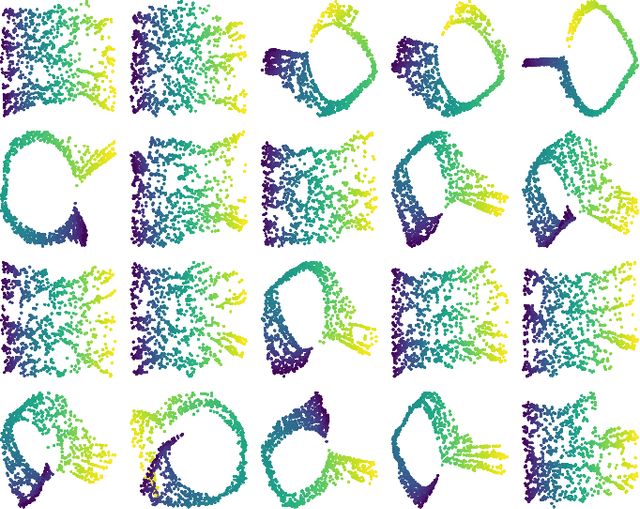
We introduce algorithms for robustly computing intrinsic coordinates on point clouds. Our approach relies on generating many candidate coordinates by subsampling the data and varying hyperparameters of the embedding algorithm (e.g., manifold learning). We then identify a subset of representative embeddings by clustering the collection of candidate coordinates and using shape descriptors from topological data analysis. The final output is the embedding obtained as an average of the representative embeddings using generalized Procrustes analysis. We validate our algorithm on both synthetic data and experimental measurements from genomics, demonstrating robustness to noise and outliers.
An Intrinsic Approach to Scalar-Curvature Estimation for Point Clouds
Aug 04, 2023
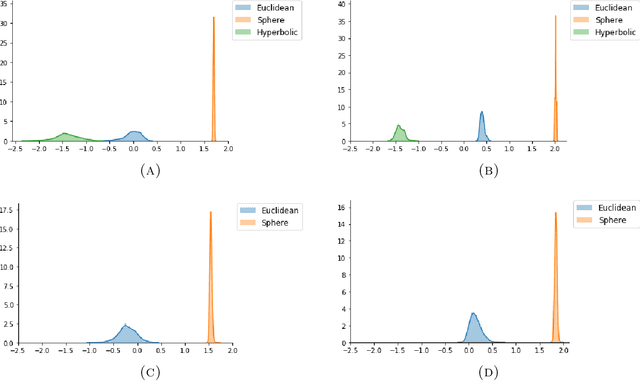


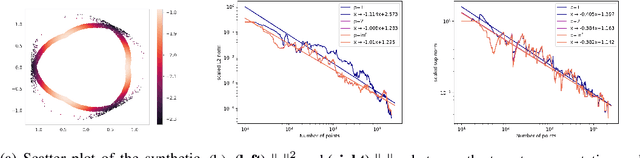
We introduce an intrinsic estimator for the scalar curvature of a data set presented as a finite metric space. Our estimator depends only on the metric structure of the data and not on an embedding in $\mathbb{R}^n$. We show that the estimator is consistent in the sense that for points sampled from a probability measure on a compact Riemannian manifold, the estimator converges to the scalar curvature as the number of points increases. To justify its use in applications, we show that the estimator is stable with respect to perturbations of the metric structure, e.g., noise in the sample or error estimating the intrinsic metric. We validate our estimator experimentally on synthetic data that is sampled from manifolds with specified curvature.
A Framework for Fast and Stable Representations of Multiparameter Persistent Homology Decompositions
Jun 19, 2023
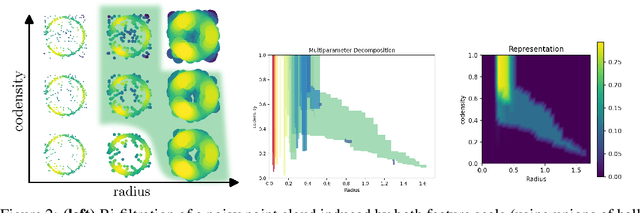
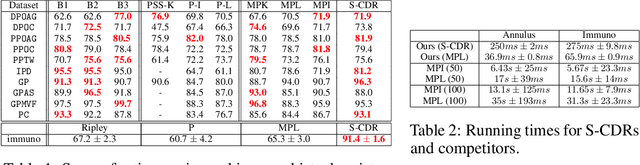
Topological data analysis (TDA) is an area of data science that focuses on using invariants from algebraic topology to provide multiscale shape descriptors for geometric data sets such as point clouds. One of the most important such descriptors is {\em persistent homology}, which encodes the change in shape as a filtration parameter changes; a typical parameter is the feature scale. For many data sets, it is useful to simultaneously vary multiple filtration parameters, for example feature scale and density. While the theoretical properties of single parameter persistent homology are well understood, less is known about the multiparameter case. In particular, a central question is the problem of representing multiparameter persistent homology by elements of a vector space for integration with standard machine learning algorithms. Existing approaches to this problem either ignore most of the multiparameter information to reduce to the one-parameter case or are heuristic and potentially unstable in the face of noise. In this article, we introduce a new general representation framework that leverages recent results on {\em decompositions} of multiparameter persistent homology. This framework is rich in information, fast to compute, and encompasses previous approaches. Moreover, we establish theoretical stability guarantees under this framework as well as efficient algorithms for practical computation, making this framework an applicable and versatile tool for analyzing geometric and point cloud data. We validate our stability results and algorithms with numerical experiments that demonstrate statistical convergence, prediction accuracy, and fast running times on several real data sets.
MREC: a fast and versatile framework for aligning and matching point clouds with applications to single cell molecular data
Feb 20, 2020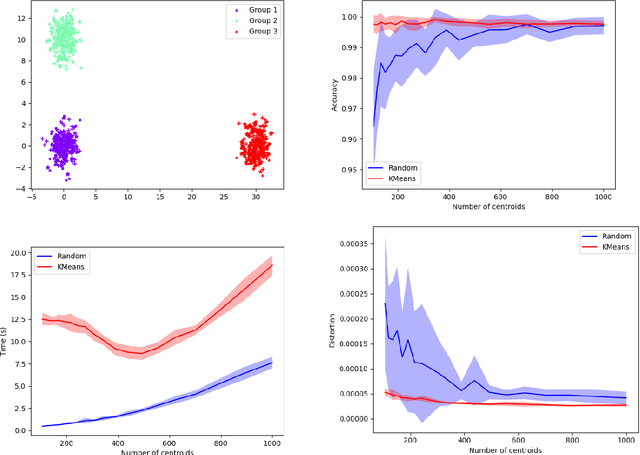

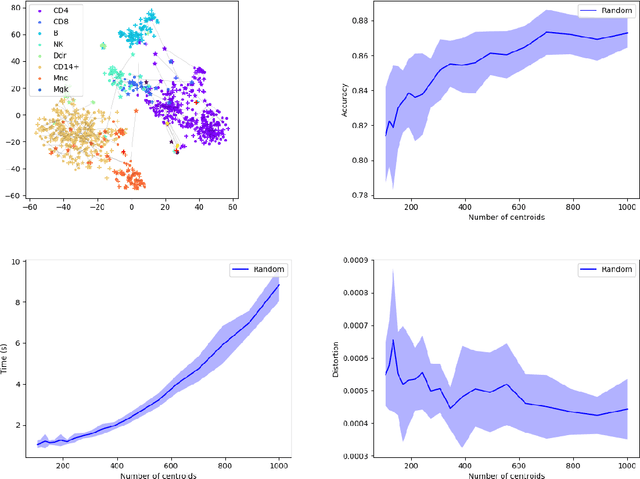
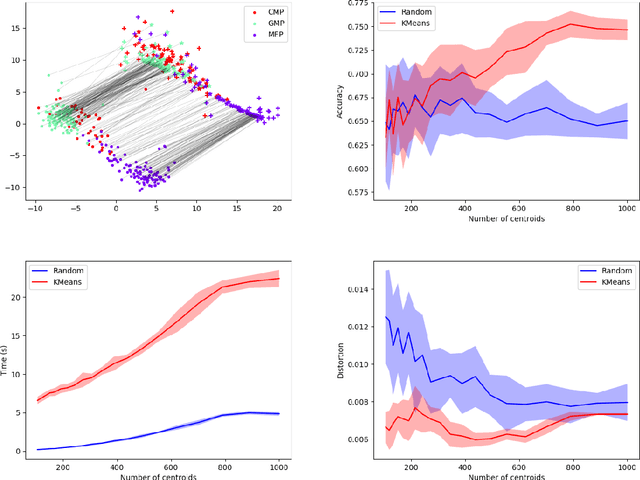
Comparing and aligning large datasets is a pervasive problem occurring across many different knowledge domains. We introduce and study MREC, a recursive decomposition algorithm for computing matchings between data sets. The basic idea is to partition the data, match the partitions, and then recursively match the points within each pair of identified partitions. The matching itself is done using black box matching procedures that are too expensive to run on the entire data set. Using an absolute measure of the quality of a matching, the framework supports optimization over parameters including partitioning procedures and matching algorithms. By design, MREC can be applied to extremely large data sets. We analyze the procedure to describe when we can expect it to work well and demonstrate its flexibility and power by applying it to a number of alignment problems arising in the analysis of single cell molecular data.
Testing to distinguish measures on metric spaces
Feb 04, 2018
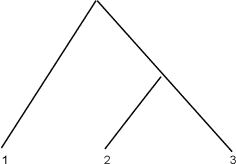
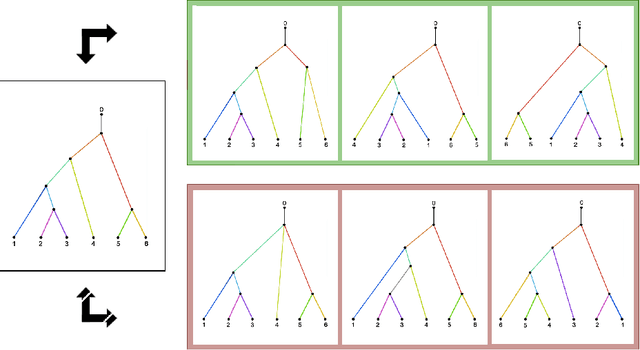
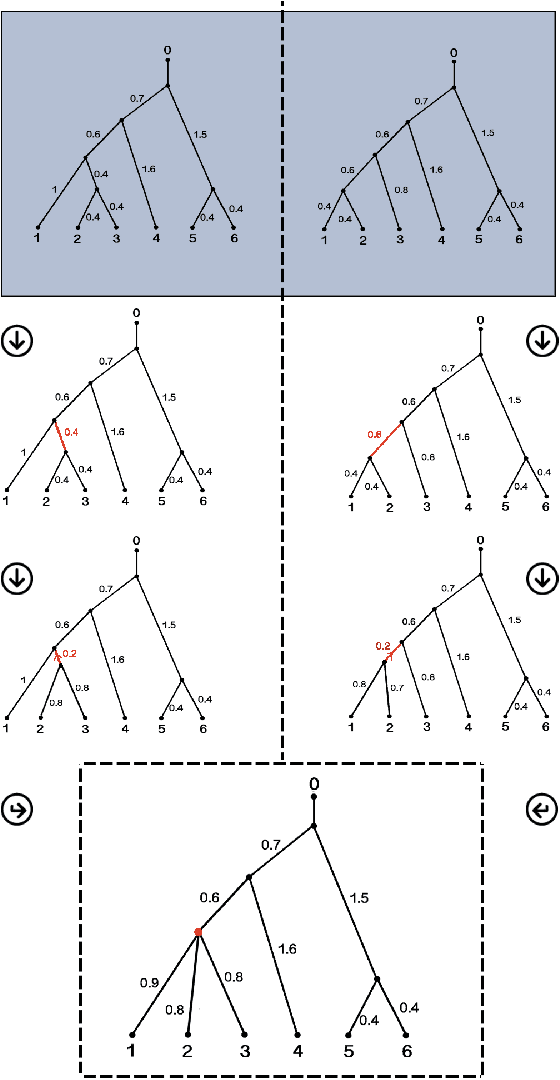
We study the problem of distinguishing between two distributions on a metric space; i.e., given metric measure spaces $({\mathbb X}, d, \mu_1)$ and $({\mathbb X}, d, \mu_2)$, we are interested in the problem of determining from finite data whether or not $\mu_1$ is $\mu_2$. The key is to use pairwise distances between observations and, employing a reconstruction theorem of Gromov, we can perform such a test using a two sample Kolmogorov--Smirnov test. A real analysis using phylogenetic trees and flu data is presented.