 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePulp Motion: Framing-aware multimodal camera and human motion generation
Oct 06, 2025Treating human motion and camera trajectory generation separately overlooks a core principle of cinematography: the tight interplay between actor performance and camera work in the screen space. In this paper, we are the first to cast this task as a text-conditioned joint generation, aiming to maintain consistent on-screen framing while producing two heterogeneous, yet intrinsically linked, modalities: human motion and camera trajectories. We propose a simple, model-agnostic framework that enforces multimodal coherence via an auxiliary modality: the on-screen framing induced by projecting human joints onto the camera. This on-screen framing provides a natural and effective bridge between modalities, promoting consistency and leading to more precise joint distribution. We first design a joint autoencoder that learns a shared latent space, together with a lightweight linear transform from the human and camera latents to a framing latent. We then introduce auxiliary sampling, which exploits this linear transform to steer generation toward a coherent framing modality. To support this task, we also introduce the PulpMotion dataset, a human-motion and camera-trajectory dataset with rich captions, and high-quality human motions. Extensive experiments across DiT- and MAR-based architectures show the generality and effectiveness of our method in generating on-frame coherent human-camera motions, while also achieving gains on textual alignment for both modalities. Our qualitative results yield more cinematographically meaningful framings setting the new state of the art for this task. Code, models and data are available in our \href{https://www.lix.polytechnique.fr/vista/projects/2025_pulpmotion_courant/}{project page}.
A Framework for Fast and Stable Representations of Multiparameter Persistent Homology Decompositions
Jun 19, 2023
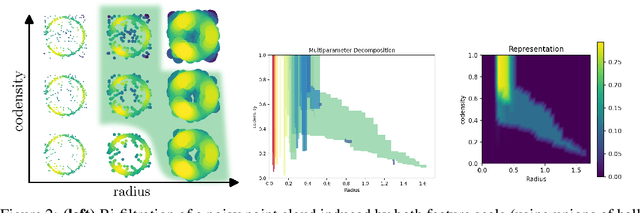
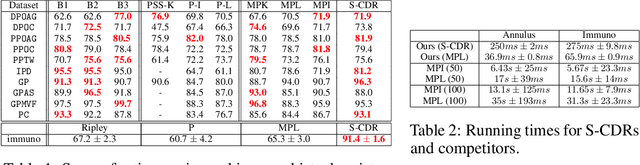
Topological data analysis (TDA) is an area of data science that focuses on using invariants from algebraic topology to provide multiscale shape descriptors for geometric data sets such as point clouds. One of the most important such descriptors is {\em persistent homology}, which encodes the change in shape as a filtration parameter changes; a typical parameter is the feature scale. For many data sets, it is useful to simultaneously vary multiple filtration parameters, for example feature scale and density. While the theoretical properties of single parameter persistent homology are well understood, less is known about the multiparameter case. In particular, a central question is the problem of representing multiparameter persistent homology by elements of a vector space for integration with standard machine learning algorithms. Existing approaches to this problem either ignore most of the multiparameter information to reduce to the one-parameter case or are heuristic and potentially unstable in the face of noise. In this article, we introduce a new general representation framework that leverages recent results on {\em decompositions} of multiparameter persistent homology. This framework is rich in information, fast to compute, and encompasses previous approaches. Moreover, we establish theoretical stability guarantees under this framework as well as efficient algorithms for practical computation, making this framework an applicable and versatile tool for analyzing geometric and point cloud data. We validate our stability results and algorithms with numerical experiments that demonstrate statistical convergence, prediction accuracy, and fast running times on several real data sets.
Stable Vectorization of Multiparameter Persistent Homology using Signed Barcodes as Measures
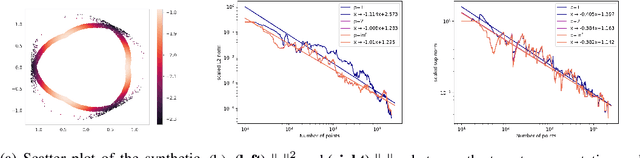
Jun 06, 2023Persistent homology (PH) provides topological descriptors for geometric data, such as weighted graphs, which are interpretable, stable to perturbations, and invariant under, e.g., relabeling. Most applications of PH focus on the one-parameter case -- where the descriptors summarize the changes in topology of data as it is filtered by a single quantity of interest -- and there is now a wide array of methods enabling the use of one-parameter PH descriptors in data science, which rely on the stable vectorization of these descriptors as elements of a Hilbert space. Although the multiparameter PH (MPH) of data that is filtered by several quantities of interest encodes much richer information than its one-parameter counterpart, the scarceness of stability results for MPH descriptors has so far limited the available options for the stable vectorization of MPH. In this paper, we aim to bring together the best of both worlds by showing how the interpretation of signed barcodes -- a recent family of MPH descriptors -- as signed measures leads to natural extensions of vectorization strategies from one parameter to multiple parameters. The resulting feature vectors are easy to define and to compute, and provably stable. While, as a proof of concept, we focus on simple choices of signed barcodes and vectorizations, we already see notable performance improvements when comparing our feature vectors to state-of-the-art topology-based methods on various types of data.