 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStatistical Query Lower Bounds for List-Decodable Linear Regression
Jun 17, 2021
We study the problem of list-decodable linear regression, where an adversary can corrupt a majority of the examples. Specifically, we are given a set $T$ of labeled examples $(x, y) \in \mathbb{R}^d \times \mathbb{R}$ and a parameter $0< \alpha <1/2$ such that an $\alpha$-fraction of the points in $T$ are i.i.d. samples from a linear regression model with Gaussian covariates, and the remaining $(1-\alpha)$-fraction of the points are drawn from an arbitrary noise distribution. The goal is to output a small list of hypothesis vectors such that at least one of them is close to the target regression vector. Our main result is a Statistical Query (SQ) lower bound of $d^{\mathrm{poly}(1/\alpha)}$ for this problem. Our SQ lower bound qualitatively matches the performance of previously developed algorithms, providing evidence that current upper bounds for this task are nearly best possible.
Outlier-Robust Learning of Ising Models Under Dobrushin's Condition
Feb 03, 2021We study the problem of learning Ising models satisfying Dobrushin's condition in the outlier-robust setting where a constant fraction of the samples are adversarially corrupted. Our main result is to provide the first computationally efficient robust learning algorithm for this problem with near-optimal error guarantees. Our algorithm can be seen as a special case of an algorithm for robustly learning a distribution from a general exponential family. To prove its correctness for Ising models, we establish new anti-concentration results for degree-$2$ polynomials of Ising models that may be of independent interest.
Outlier-Robust High-Dimensional Sparse Estimation via Iterative Filtering
Nov 19, 2019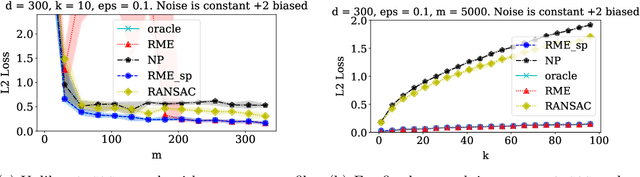
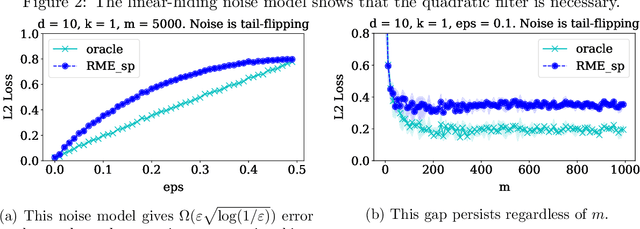

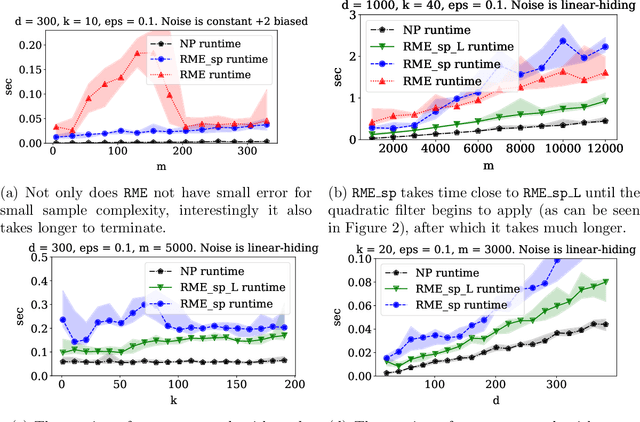
We study high-dimensional sparse estimation tasks in a robust setting where a constant fraction of the dataset is adversarially corrupted. Specifically, we focus on the fundamental problems of robust sparse mean estimation and robust sparse PCA. We give the first practically viable robust estimators for these problems. In more detail, our algorithms are sample and computationally efficient and achieve near-optimal robustness guarantees. In contrast to prior provable algorithms which relied on the ellipsoid method, our algorithms use spectral techniques to iteratively remove outliers from the dataset. Our experimental evaluation on synthetic data shows that our algorithms are scalable and significantly outperform a range of previous approaches, nearly matching the best error rate without corruptions.
Robust Learning of Fixed-Structure Bayesian Networks
Oct 29, 2018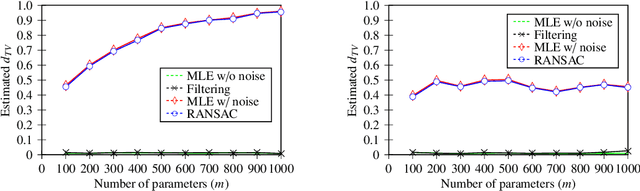
We investigate the problem of learning Bayesian networks in a robust model where an $\epsilon$-fraction of the samples are adversarially corrupted. In this work, we study the fully observable discrete case where the structure of the network is given. Even in this basic setting, previous learning algorithms either run in exponential time or lose dimension-dependent factors in their error guarantees. We provide the first computationally efficient robust learning algorithm for this problem with dimension-independent error guarantees. Our algorithm has near-optimal sample complexity, runs in polynomial time, and achieves error that scales nearly-linearly with the fraction of adversarially corrupted samples. Finally, we show on both synthetic and semi-synthetic data that our algorithm performs well in practice.
Efficient Algorithms and Lower Bounds for Robust Linear Regression
May 31, 2018We study the problem of high-dimensional linear regression in a robust model where an $\epsilon$-fraction of the samples can be adversarially corrupted. We focus on the fundamental setting where the covariates of the uncorrupted samples are drawn from a Gaussian distribution $\mathcal{N}(0, \Sigma)$ on $\mathbb{R}^d$. We give nearly tight upper bounds and computational lower bounds for this problem. Specifically, our main contributions are as follows: For the case that the covariance matrix is known to be the identity, we give a sample near-optimal and computationally efficient algorithm that outputs a candidate hypothesis vector $\widehat{\beta}$ which approximates the unknown regression vector $\beta$ within $\ell_2$-norm $O(\epsilon \log(1/\epsilon) \sigma)$, where $\sigma$ is the standard deviation of the random observation noise. An error of $\Omega (\epsilon \sigma)$ is information-theoretically necessary, even with infinite sample size. Prior work gave an algorithm for this problem with sample complexity $\tilde{\Omega}(d^2/\epsilon^2)$ whose error guarantee scales with the $\ell_2$-norm of $\beta$. For the case of unknown covariance, we show that we can efficiently achieve the same error guarantee as in the known covariance case using an additional $\tilde{O}(d^2/\epsilon^2)$ unlabeled examples. On the other hand, an error of $O(\epsilon \sigma)$ can be information-theoretically attained with $O(d/\epsilon^2)$ samples. We prove a Statistical Query (SQ) lower bound providing evidence that this quadratic tradeoff in the sample size is inherent. More specifically, we show that any polynomial time SQ learning algorithm for robust linear regression (in Huber's contamination model) with estimation complexity $O(d^{2-c})$, where $c>0$ is an arbitrarily small constant, must incur an error of $\Omega(\sqrt{\epsilon} \sigma)$.
Being Robust (in High Dimensions) Can Be Practical
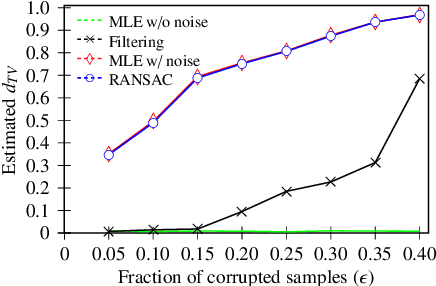
Mar 13, 2018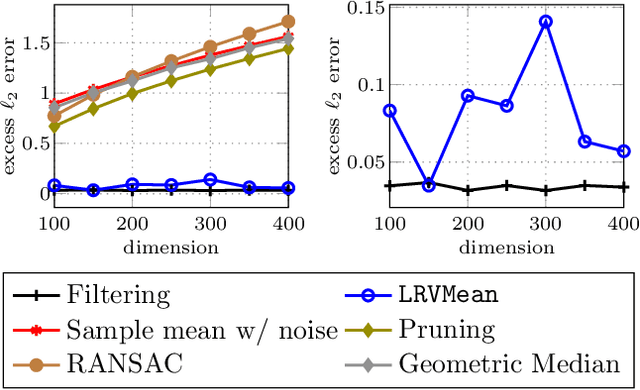
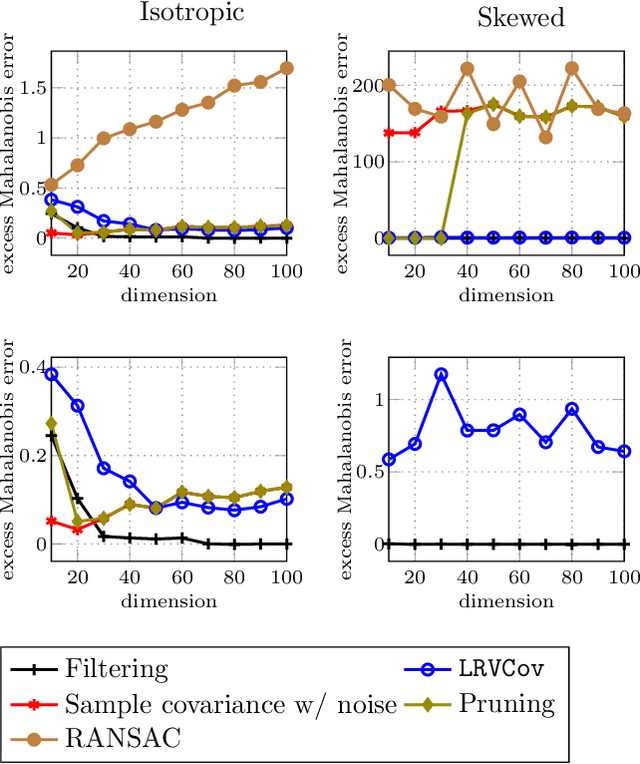
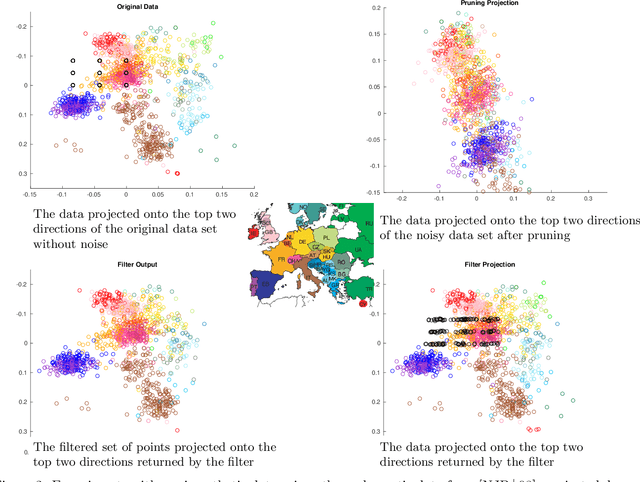
Robust estimation is much more challenging in high dimensions than it is in one dimension: Most techniques either lead to intractable optimization problems or estimators that can tolerate only a tiny fraction of errors. Recent work in theoretical computer science has shown that, in appropriate distributional models, it is possible to robustly estimate the mean and covariance with polynomial time algorithms that can tolerate a constant fraction of corruptions, independent of the dimension. However, the sample and time complexity of these algorithms is prohibitively large for high-dimensional applications. In this work, we address both of these issues by establishing sample complexity bounds that are optimal, up to logarithmic factors, as well as giving various refinements that allow the algorithms to tolerate a much larger fraction of corruptions. Finally, we show on both synthetic and real data that our algorithms have state-of-the-art performance and suddenly make high-dimensional robust estimation a realistic possibility.
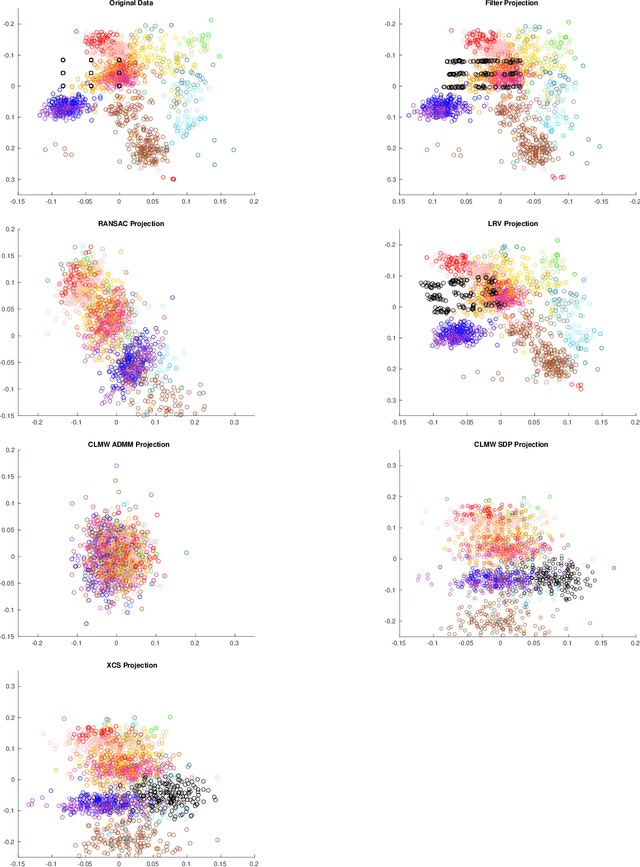
Sever: A Robust Meta-Algorithm for Stochastic Optimization
Mar 07, 2018
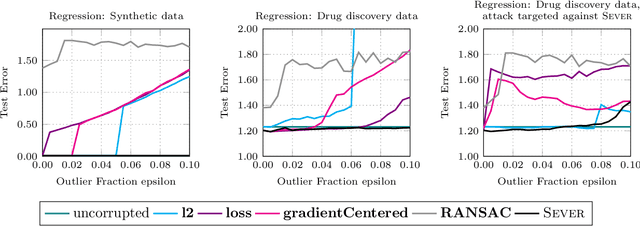
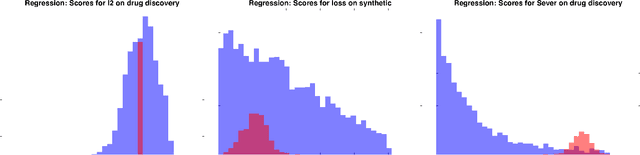

In high dimensions, most machine learning methods are brittle to even a small fraction of structured outliers. To address this, we introduce a new meta-algorithm that can take in a base learner such as least squares or stochastic gradient descent, and harden the learner to be resistant to outliers. Our method, Sever, possesses strong theoretical guarantees yet is also highly scalable -- beyond running the base learner itself, it only requires computing the top singular vector of a certain $n \times d$ matrix. We apply Sever on a drug design dataset and a spam classification dataset, and find that in both cases it has substantially greater robustness than several baselines. On the spam dataset, with $1\%$ corruptions, we achieved $7.4\%$ test error, compared to $13.4\%-20.5\%$ for the baselines, and $3\%$ error on the uncorrupted dataset. Similarly, on the drug design dataset, with $10\%$ corruptions, we achieved $1.42$ mean-squared error test error, compared to $1.51$-$2.33$ for the baselines, and $1.23$ error on the uncorrupted dataset.
Near-Optimal Sample Complexity Bounds for Maximum Likelihood Estimation of Multivariate Log-concave Densities
Feb 28, 2018
We study the problem of learning multivariate log-concave densities with respect to a global loss function. We obtain the first upper bound on the sample complexity of the maximum likelihood estimator (MLE) for a log-concave density on $\mathbb{R}^d$, for all $d \geq 4$. Prior to this work, no finite sample upper bound was known for this estimator in more than $3$ dimensions. In more detail, we prove that for any $d \geq 1$ and $\epsilon>0$, given $\tilde{O}_d((1/\epsilon)^{(d+3)/2})$ samples drawn from an unknown log-concave density $f_0$ on $\mathbb{R}^d$, the MLE outputs a hypothesis $h$ that with high probability is $\epsilon$-close to $f_0$, in squared Hellinger loss. A sample complexity lower bound of $\Omega_d((1/\epsilon)^{(d+1)/2})$ was previously known for any learning algorithm that achieves this guarantee. We thus establish that the sample complexity of the log-concave MLE is near-optimal, up to an $\tilde{O}(1/\epsilon)$ factor.
List-Decodable Robust Mean Estimation and Learning Mixtures of Spherical Gaussians
Nov 20, 2017We study the problem of list-decodable Gaussian mean estimation and the related problem of learning mixtures of separated spherical Gaussians. We develop a set of techniques that yield new efficient algorithms with significantly improved guarantees for these problems. {\bf List-Decodable Mean Estimation.} Fix any $d \in \mathbb{Z}_+$ and $0< \alpha <1/2$. We design an algorithm with runtime $O (\mathrm{poly}(n/\alpha)^{d})$ that outputs a list of $O(1/\alpha)$ many candidate vectors such that with high probability one of the candidates is within $\ell_2$-distance $O(\alpha^{-1/(2d)})$ from the true mean. The only previous algorithm for this problem achieved error $\tilde O(\alpha^{-1/2})$ under second moment conditions. For $d = O(1/\epsilon)$, our algorithm runs in polynomial time and achieves error $O(\alpha^{\epsilon})$. We also give a Statistical Query lower bound suggesting that the complexity of our algorithm is qualitatively close to best possible. {\bf Learning Mixtures of Spherical Gaussians.} We give a learning algorithm for mixtures of spherical Gaussians that succeeds under significantly weaker separation assumptions compared to prior work. For the prototypical case of a uniform mixture of $k$ identity covariance Gaussians we obtain: For any $\epsilon>0$, if the pairwise separation between the means is at least $\Omega(k^{\epsilon}+\sqrt{\log(1/\delta)})$, our algorithm learns the unknown parameters within accuracy $\delta$ with sample complexity and running time $\mathrm{poly} (n, 1/\delta, (k/\epsilon)^{1/\epsilon})$. The previously best known polynomial time algorithm required separation at least $k^{1/4} \mathrm{polylog}(k/\delta)$. Our main technical contribution is a new technique, using degree-$d$ multivariate polynomials, to remove outliers from high-dimensional datasets where the majority of the points are corrupted.
Robustly Learning a Gaussian: Getting Optimal Error, Efficiently
Nov 05, 2017We study the fundamental problem of learning the parameters of a high-dimensional Gaussian in the presence of noise -- where an $\varepsilon$-fraction of our samples were chosen by an adversary. We give robust estimators that achieve estimation error $O(\varepsilon)$ in the total variation distance, which is optimal up to a universal constant that is independent of the dimension. In the case where just the mean is unknown, our robustness guarantee is optimal up to a factor of $\sqrt{2}$ and the running time is polynomial in $d$ and $1/\epsilon$. When both the mean and covariance are unknown, the running time is polynomial in $d$ and quasipolynomial in $1/\varepsilon$. Moreover all of our algorithms require only a polynomial number of samples. Our work shows that the same sorts of error guarantees that were established over fifty years ago in the one-dimensional setting can also be achieved by efficient algorithms in high-dimensional settings.