 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Early Bird Identifies the Worm: You Can't Beat a Head Start in Long-Term Body Re-ID (ECHO-BID)
Jul 23, 2025Person identification in unconstrained viewing environments presents significant challenges due to variations in distance, viewpoint, imaging conditions, and clothing. We introduce $\textbf{E}$va $\textbf{C}$lothes-Change from $\textbf{H}$idden $\textbf{O}$bjects - $\textbf{B}$ody $\textbf{ID}$entification (ECHO-BID), a class of long-term re-id models built on object-pretrained EVA-02 Large backbones. We compare ECHO-BID to 9 other models that vary systematically in backbone architecture, model size, scale of object classification pretraining, and transfer learning protocol. Models were evaluated on benchmark datasets across constrained, unconstrained, and occluded settings. ECHO-BID, with transfer learning on the most challenging clothes-change data, achieved state-of-the-art results on long-term re-id -- substantially outperforming other methods. ECHO-BID also surpassed other methods by a wide margin in occluded viewing scenarios. A combination of increased model size and Masked Image Modeling during pretraining underlie ECHO-BID's strong performance on long-term re-id. Notably, a smaller, but more challenging transfer learning dataset, generalized better across datasets than a larger, less challenging one. However, the larger dataset with an additional fine-tuning step proved best on the most difficult data. Selecting the correct pretrained backbone architecture and transfer learning protocols can drive substantial gains in long-term re-id performance.
Gaussian Harmony: Attaining Fairness in Diffusion-based Face Generation Models
Dec 21, 2023Diffusion models have achieved great progress in face generation. However, these models amplify the bias in the generation process, leading to an imbalance in distribution of sensitive attributes such as age, gender and race. This paper proposes a novel solution to this problem by balancing the facial attributes of the generated images. We mitigate the bias by localizing the means of the facial attributes in the latent space of the diffusion model using Gaussian mixture models (GMM). Our motivation for choosing GMMs over other clustering frameworks comes from the flexible latent structure of diffusion model. Since each sampling step in diffusion models follows a Gaussian distribution, we show that fitting a GMM model helps us to localize the subspace responsible for generating a specific attribute. Furthermore, our method does not require retraining, we instead localize the subspace on-the-fly and mitigate the bias for generating a fair dataset. We evaluate our approach on multiple face attribute datasets to demonstrate the effectiveness of our approach. Our results demonstrate that our approach leads to a more fair data generation in terms of representational fairness while preserving the quality of generated samples.
Human-Machine Comparison for Cross-Race Face Verification: Race Bias at the Upper Limits of Performance?
May 31, 2023Face recognition algorithms perform more accurately than humans in some cases, though humans and machines both show race-based accuracy differences. As algorithms continue to improve, it is important to continually assess their race bias relative to humans. We constructed a challenging test of 'cross-race' face verification and used it to compare humans and two state-of-the-art face recognition systems. Pairs of same- and different-identity faces of White and Black individuals were selected to be difficult for humans and an open-source implementation of the ArcFace face recognition algorithm from 2019 (5). Human participants (54 Black; 51 White) judged whether face pairs showed the same identity or different identities on a 7-point Likert-type scale. Two top-performing face recognition systems from the Face Recognition Vendor Test-ongoing performed the same test (7). By design, the test proved challenging for humans as a group, who performed above chance, but far less than perfect. Both state-of-the-art face recognition systems scored perfectly (no errors), consequently with equal accuracy for both races. We conclude that state-of-the-art systems for identity verification between two frontal face images of Black and White individuals can surpass the general population. Whether this result generalizes to challenging in-the-wild images is a pressing concern for deploying face recognition systems in unconstrained environments.
Recognizing People by Body Shape Using Deep Networks of Images and Words
May 30, 2023

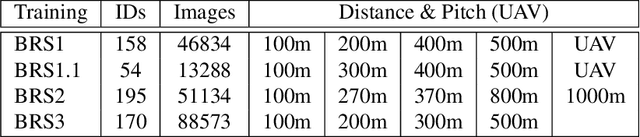

Common and important applications of person identification occur at distances and viewpoints in which the face is not visible or is not sufficiently resolved to be useful. We examine body shape as a biometric across distance and viewpoint variation. We propose an approach that combines standard object classification networks with representations based on linguistic (word-based) descriptions of bodies. Algorithms with and without linguistic training were compared on their ability to identify people from body shape in images captured across a large range of distances/views (close-range, 100m, 200m, 270m, 300m, 370m, 400m, 490m, 500m, 600m, and at elevated pitch in images taken by an unmanned aerial vehicle [UAV]). Accuracy, as measured by identity-match ranking and false accept errors in an open-set test, was surprisingly good. For identity-ranking, linguistic models were more accurate for close-range images, whereas non-linguistic models fared better at intermediary distances. Fusion of the linguistic and non-linguistic embeddings improved performance at all, but the farthest distance. Although the non-linguistic model yielded fewer false accepts at all distances, fusion of the linguistic and non-linguistic models decreased false accepts for all, but the UAV images. We conclude that linguistic and non-linguistic representations of body shape can offer complementary identity information for bodies that can improve identification in applications of interest.
Identity masking effectiveness and gesture recognition: Effects of eye enhancement in seeing through the mask
Jan 20, 2023Face identity masking algorithms developed in recent years aim to protect the privacy of people in video recordings. These algorithms are designed to interfere with identification, while preserving information about facial actions. An important challenge is to preserve subtle actions in the eye region, while obscuring the salient identity cues from the eyes. We evaluated the effectiveness of identity-masking algorithms based on Canny filters, applied with and without eye enhancement, for interfering with identification and preserving facial actions. In Experiments 1 and 2, we tested human participants' ability to match the facial identity of a driver in a low resolution video to a high resolution facial image. Results showed that both masking methods impaired identification, and that eye enhancement did not alter the effectiveness of the Canny filter mask. In Experiment 3, we tested action preservation and found that neither method interfered significantly with driver action perception. We conclude that relatively simple, filter-based masking algorithms, which are suitable for application to low quality video, can be used in privacy protection without compromising action perception.
Twin identification over viewpoint change: A deep convolutional neural network surpasses humans
Jul 12, 2022
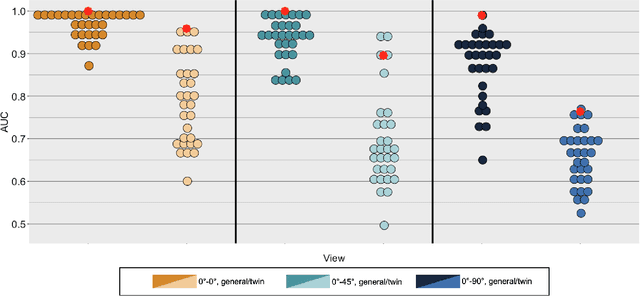
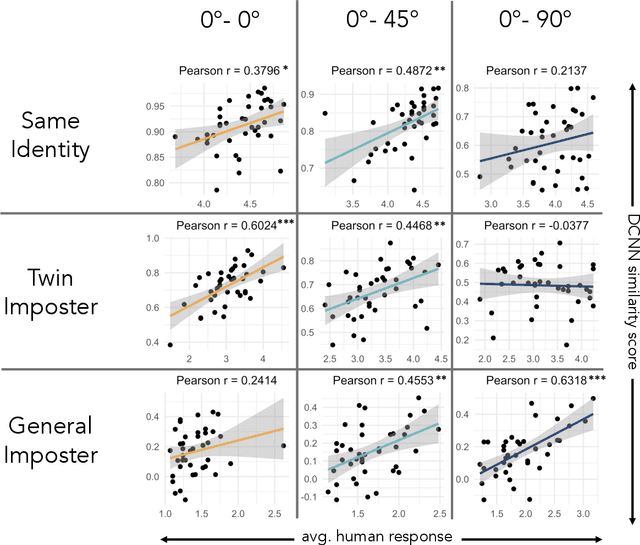
Deep convolutional neural networks (DCNNs) have achieved human-level accuracy in face identification (Phillips et al., 2018), though it is unclear how accurately they discriminate highly-similar faces. Here, humans and a DCNN performed a challenging face-identity matching task that included identical twins. Participants (N=87) viewed pairs of face images of three types: same-identity, general imposter pairs (different identities from similar demographic groups), and twin imposter pairs (identical twin siblings). The task was to determine whether the pairs showed the same person or different people. Identity comparisons were tested in three viewpoint-disparity conditions: frontal to frontal, frontal to 45-degree profile, and frontal to 90-degree profile. Accuracy for discriminating matched-identity pairs from twin-imposters and general imposters was assessed in each viewpoint-disparity condition. Humans were more accurate for general-imposter pairs than twin-imposter pairs, and accuracy declined with increased viewpoint disparity between the images in a pair. A DCNN trained for face identification (Ranjan et al., 2018) was tested on the same image pairs presented to humans. Machine performance mirrored the pattern of human accuracy, but with performance at or above all humans in all but one condition. Human and machine similarity scores were compared across all image-pair types. This item-level analysis showed that human and machine similarity ratings correlated significantly in six of nine image-pair types [range r=0.38 to r=0.63], suggesting general accord between the perception of face similarity by humans and the DCNN. These findings also contribute to our understanding of DCNN performance for discriminating high-resemblance faces, demonstrate that the DCNN performs at a level at or above humans, and suggest a degree of parity between the features used by humans and the DCNN.
The Influence of the Other-Race Effect on Susceptibility to Face Morphing Attacks
Apr 26, 2022
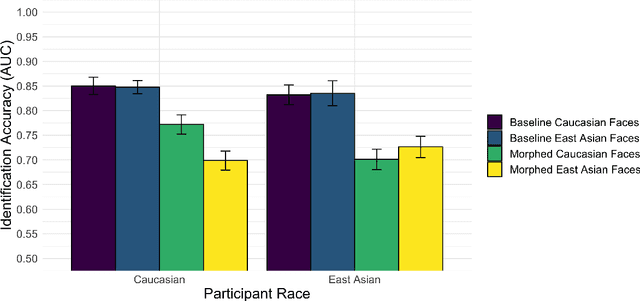
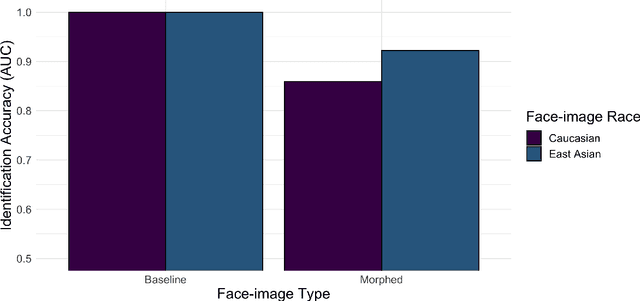
Facial morphs created between two identities resemble both of the faces used to create the morph. Consequently, humans and machines are prone to mistake morphs made from two identities for either of the faces used to create the morph. This vulnerability has been exploited in "morph attacks" in security scenarios. Here, we asked whether the "other-race effect" (ORE) -- the human advantage for identifying own- vs. other-race faces -- exacerbates morph attack susceptibility for humans. We also asked whether face-identification performance in a deep convolutional neural network (DCNN) is affected by the race of morphed faces. Caucasian (CA) and East-Asian (EA) participants performed a face-identity matching task on pairs of CA and EA face images in two conditions. In the morph condition, different-identity pairs consisted of an image of identity "A" and a 50/50 morph between images of identity "A" and "B". In the baseline condition, morphs of different identities never appeared. As expected, morphs were identified mistakenly more often than original face images. Moreover, CA participants showed an advantage for CA faces in comparison to EA faces (a partial ORE). Of primary interest, morph identification was substantially worse for cross-race faces than for own-race faces. Similar to humans, the DCNN performed more accurately for original face images than for morphed image pairs. Notably, the deep network proved substantially more accurate than humans in both cases. The results point to the possibility that DCNNs might be useful for improving face identification accuracy when morphed faces are presented. They also indicate the significance of the ORE in morph attack susceptibility in applied settings.
Face Identification Proficiency Test Designed Using Item Response Theory
Jul 01, 2021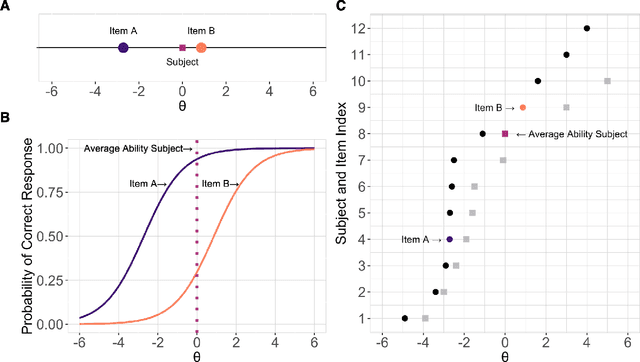
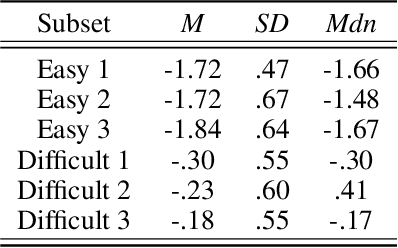
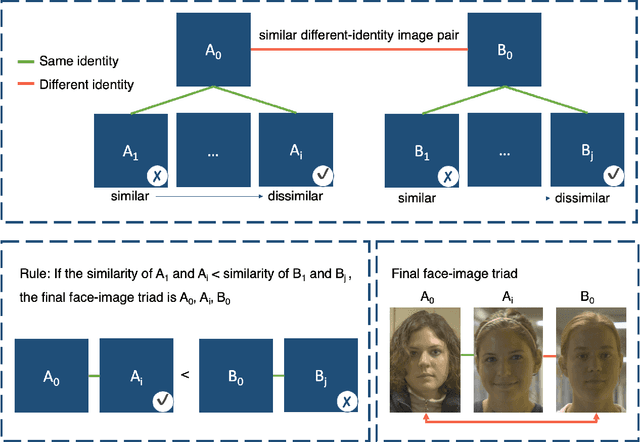
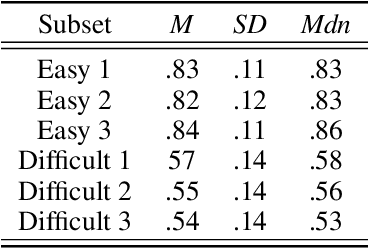
Measures of face identification proficiency are essential to ensure accurate and consistent performance by professional forensic face examiners and others who perform face identification tasks in applied scenarios. Current proficiency tests rely on static sets of stimulus items, and so, cannot be administered validly to the same individual multiple times. To create a proficiency test, a large number of items of "known" difficulty must be assembled. Multiple tests of equal difficulty can be constructed then using subsets of items. Here, we introduce a proficiency test, the Triad Identity Matching (TIM) test, based on stimulus difficulty measures based on Item Response Theory (IRT). Participants view face-image "triads" (N=225) (two images of one identity and one image of a different identity) and select the different identity. In Experiment 1, university students (N=197) showed wide-ranging accuracy on the TIM test. Furthermore, IRT modeling demonstrated that the TIM test produces items of various difficulty levels. In Experiment 2, IRT-based item difficulty measures were used to partition the TIM test into three equally "easy" and three equally "difficult" subsets. Simulation results indicated that the full set, as well as curated subsets, of the TIM items yielded reliable estimates of subject ability. In summary, the TIM test can provide a starting point for developing a framework that is flexible, calibrated, and adaptive to measure proficiency across various ability levels (e.g., professionals or populations with face processing deficits)
Single Unit Status in Deep Convolutional Neural Network Codes for Face Identification: Sparseness Redefined
Mar 01, 2020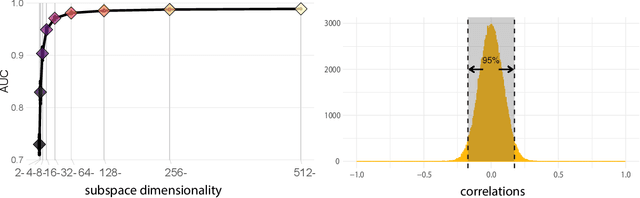
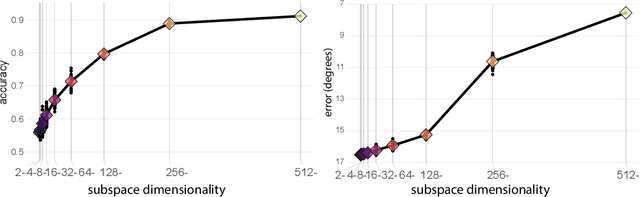
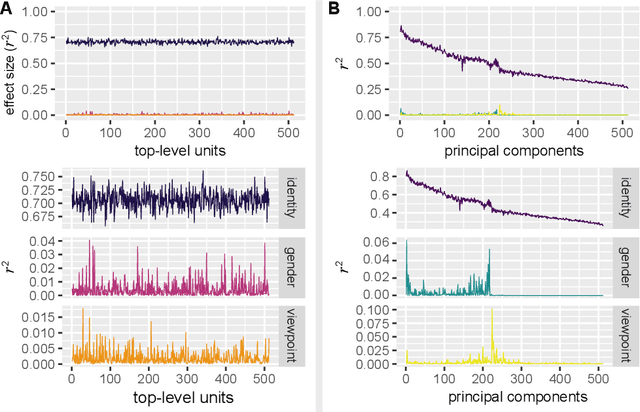
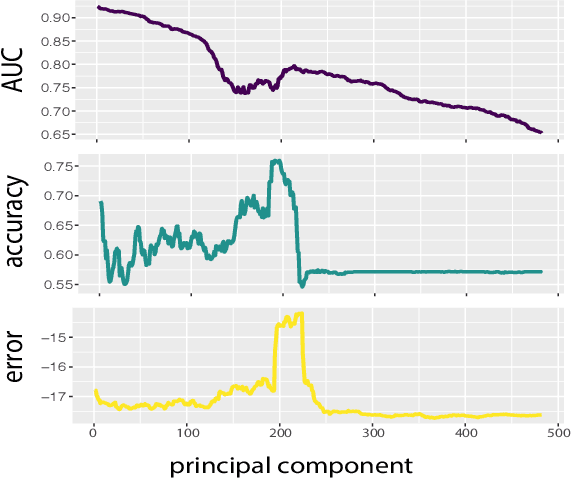
Deep convolutional neural networks (DCNNs) trained for face identification develop representations that generalize over variable images, while retaining subject (e.g., gender) and image (e.g., viewpoint) information. Identity, gender, and viewpoint codes were studied at the "neural unit" and ensemble levels of a face-identification network. At the unit level, identification, gender classification, and viewpoint estimation were measured by deleting units to create variably-sized, randomly-sampled subspaces at the top network layer. Identification of 3,531 identities remained high (area under the ROC approximately 1.0) as dimensionality decreased from 512 units to 16 (0.95), 4 (0.80), and 2 (0.72) units. Individual identities separated statistically on every top-layer unit. Cross-unit responses were minimally correlated, indicating that units code non-redundant identity cues. This "distributed" code requires only a sparse, random sample of units to identify faces accurately. Gender classification declined gradually and viewpoint estimation fell steeply as dimensionality decreased. Individual units were weakly predictive of gender and viewpoint, but ensembles proved effective predictors. Therefore, distributed and sparse codes co-exist in the network units to represent different face attributes. At the ensemble level, principal component analysis of face representations showed that identity, gender, and viewpoint information separated into high-dimensional subspaces, ordered by explained variance. Identity, gender, and viewpoint information contributed to all individual unit responses, undercutting a neural tuning analogy for face attributes. Interpretation of neural-like codes from DCNNs, and by analogy, high-level visual codes, cannot be inferred from single unit responses. Instead, "meaning" is encoded by directions in the high-dimensional space.
Accuracy comparison across face recognition algorithms: Where are we on measuring race bias?
Dec 16, 2019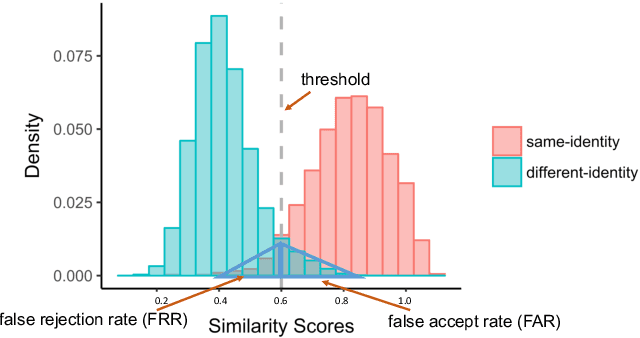
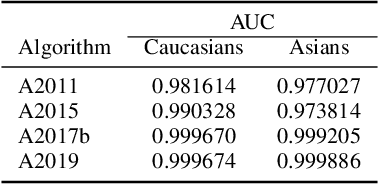

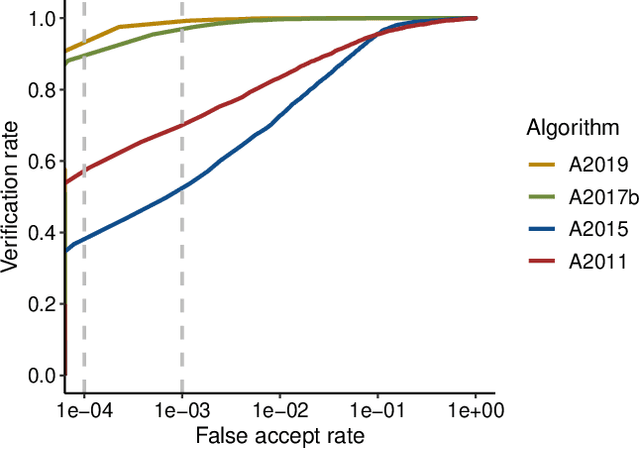
Previous generations of face recognition algorithms differ in accuracy for faces of different races (race bias). Whether deep convolutional neural networks (DCNNs) are race biased is less studied. To measure race bias in algorithms, it is important to consider the underlying factors. Here, we present the possible underlying factors and methodological considerations for assessing race bias in algorithms. We investigate data-driven and scenario modeling factors. Data-driven factors include image quality, image population statistics, and algorithm architecture. Scenario modeling considers the role of the "user" of the algorithm (e.g., threshold decisions and demographic constraints). To illustrate how these issues apply, we present data from four face recognition algorithms (one pre- DCNN, three DCNN) for Asian and Caucasian faces. First, for all four algorithms, the degree of bias varied depending on the identification decision threshold. Second, for all algorithms, to achieve equal false accept rates (FARs), Asian faces required higher identification thresholds than Caucasian faces. Third, dataset difficulty affected both overall recognition accuracy and race bias. Fourth, demographic constraints on the formulation of the distributions used in the test, impacted estimates of algorithm accuracy. We conclude with a recommended checklist for measuring race bias in face recognition algorithms.