 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDissecting Human Body Representations in Deep Networks Trained for Person Identification
Feb 21, 2025Long-term body identification algorithms have emerged recently with the increased availability of high-quality training data. We seek to fill knowledge gaps about these models by analyzing body image embeddings from four body identification networks trained with 1.9 million images across 4,788 identities and 9 databases. By analyzing a diverse range of architectures (ViT, SWIN-ViT, CNN, and linguistically primed CNN), we first show that the face contributes to the accuracy of body identification algorithms and that these algorithms can identify faces to some extent -- with no explicit face training. Second, we show that representations (embeddings) generated by body identification algorithms encode information about gender, as well as image-based information including view (yaw) and even the dataset from which the image originated. Third, we demonstrate that identification accuracy can be improved without additional training by operating directly and selectively on the learned embedding space. Leveraging principal component analysis (PCA), identity comparisons were consistently more accurate in subspaces that eliminated dimensions that explained large amounts of variance. These three findings were surprisingly consistent across architectures and test datasets. This work represents the first analysis of body representations produced by long-term re-identification networks trained on challenging unconstrained datasets.
Unconstrained Body Recognition at Altitude and Range: Comparing Four Approaches
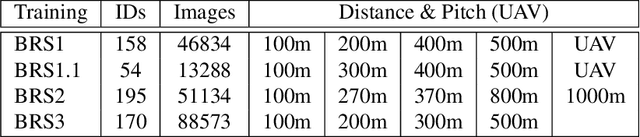
Feb 10, 2025This study presents an investigation of four distinct approaches to long-term person identification using body shape. Unlike short-term re-identification systems that rely on temporary features (e.g., clothing), we focus on learning persistent body shape characteristics that remain stable over time. We introduce a body identification model based on a Vision Transformer (ViT) (Body Identification from Diverse Datasets, BIDDS) and on a Swin-ViT model (Swin-BIDDS). We also expand on previous approaches based on the Linguistic and Non-linguistic Core ResNet Identity Models (LCRIM and NLCRIM), but with improved training. All models are trained on a large and diverse dataset of over 1.9 million images of approximately 5k identities across 9 databases. Performance was evaluated on standard re-identification benchmark datasets (MARS, MSMT17, Outdoor Gait, DeepChange) and on an unconstrained dataset that includes images at a distance (from close-range to 1000m), at altitude (from an unmanned aerial vehicle, UAV), and with clothing change. A comparative analysis across these models provides insights into how different backbone architectures and input image sizes impact long-term body identification performance across real-world conditions.
Recognizing People by Body Shape Using Deep Networks of Images and Words
May 30, 2023


Common and important applications of person identification occur at distances and viewpoints in which the face is not visible or is not sufficiently resolved to be useful. We examine body shape as a biometric across distance and viewpoint variation. We propose an approach that combines standard object classification networks with representations based on linguistic (word-based) descriptions of bodies. Algorithms with and without linguistic training were compared on their ability to identify people from body shape in images captured across a large range of distances/views (close-range, 100m, 200m, 270m, 300m, 370m, 400m, 490m, 500m, 600m, and at elevated pitch in images taken by an unmanned aerial vehicle [UAV]). Accuracy, as measured by identity-match ranking and false accept errors in an open-set test, was surprisingly good. For identity-ranking, linguistic models were more accurate for close-range images, whereas non-linguistic models fared better at intermediary distances. Fusion of the linguistic and non-linguistic embeddings improved performance at all, but the farthest distance. Although the non-linguistic model yielded fewer false accepts at all distances, fusion of the linguistic and non-linguistic models decreased false accepts for all, but the UAV images. We conclude that linguistic and non-linguistic representations of body shape can offer complementary identity information for bodies that can improve identification in applications of interest.