 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMelGAN: Generative Adversarial Networks for Conditional Waveform Synthesis
Oct 28, 2019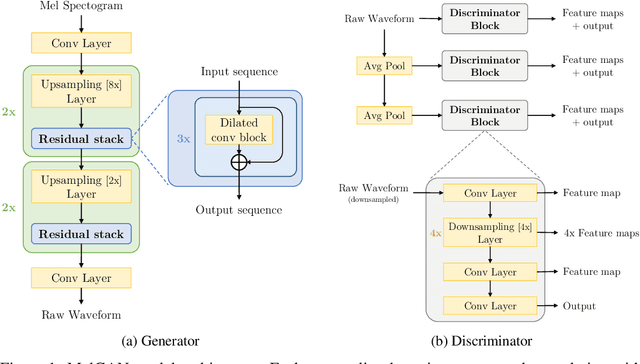


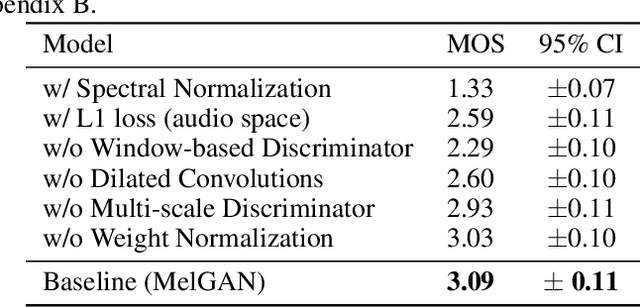
Previous works (Donahue et al., 2018a; Engel et al., 2019a) have found that generating coherent raw audio waveforms with GANs is challenging. In this paper, we show that it is possible to train GANs reliably to generate high quality coherent waveforms by introducing a set of architectural changes and simple training techniques. Subjective evaluation metric (Mean Opinion Score, or MOS) shows the effectiveness of the proposed approach for high quality mel-spectrogram inversion. To establish the generality of the proposed techniques, we show qualitative results of our model in speech synthesis, music domain translation and unconditional music synthesis. We evaluate the various components of the model through ablation studies and suggest a set of guidelines to design general purpose discriminators and generators for conditional sequence synthesis tasks. Our model is non-autoregressive, fully convolutional, with significantly fewer parameters than competing models and generalizes to unseen speakers for mel-spectrogram inversion. Our pytorch implementation runs at more than 100x faster than realtime on GTX 1080Ti GPU and more than 2x faster than real-time on CPU, without any hardware specific optimization tricks.
A Deep Reinforcement Learning Chatbot (Short Version)
Jan 20, 2018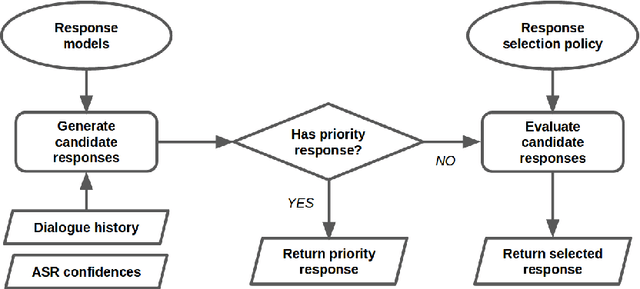
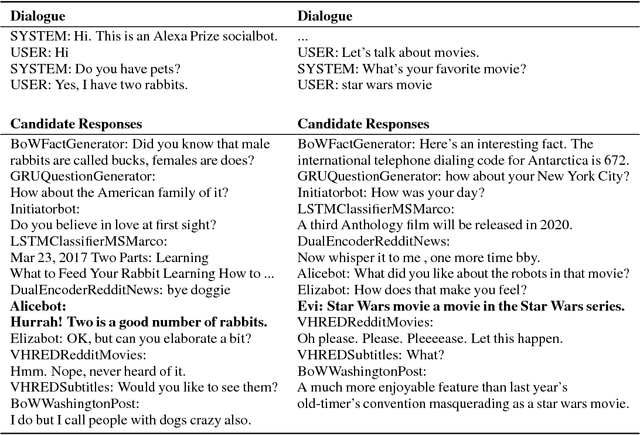
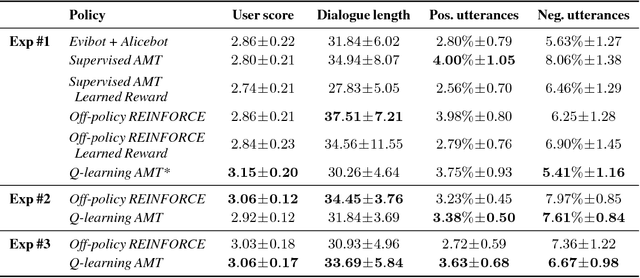
We present MILABOT: a deep reinforcement learning chatbot developed by the Montreal Institute for Learning Algorithms (MILA) for the Amazon Alexa Prize competition. MILABOT is capable of conversing with humans on popular small talk topics through both speech and text. The system consists of an ensemble of natural language generation and retrieval models, including neural network and template-based models. By applying reinforcement learning to crowdsourced data and real-world user interactions, the system has been trained to select an appropriate response from the models in its ensemble. The system has been evaluated through A/B testing with real-world users, where it performed significantly better than other systems. The results highlight the potential of coupling ensemble systems with deep reinforcement learning as a fruitful path for developing real-world, open-domain conversational agents.
ObamaNet: Photo-realistic lip-sync from text
Dec 06, 2017
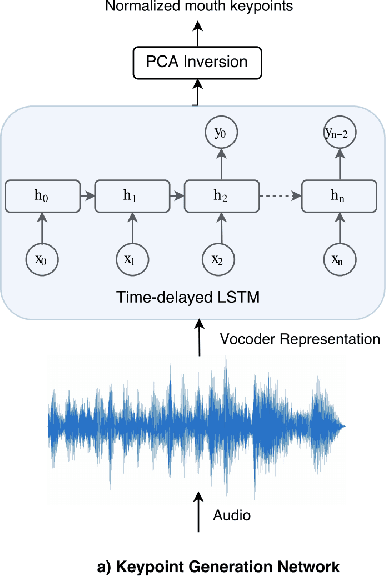
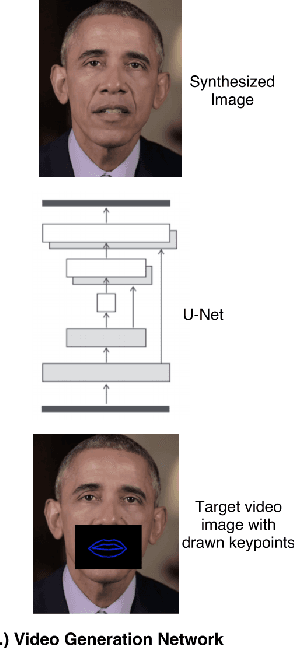

We present ObamaNet, the first architecture that generates both audio and synchronized photo-realistic lip-sync videos from any new text. Contrary to other published lip-sync approaches, ours is only composed of fully trainable neural modules and does not rely on any traditional computer graphics methods. More precisely, we use three main modules: a text-to-speech network based on Char2Wav, a time-delayed LSTM to generate mouth-keypoints synced to the audio, and a network based on Pix2Pix to generate the video frames conditioned on the keypoints.
A Deep Reinforcement Learning Chatbot
Nov 05, 2017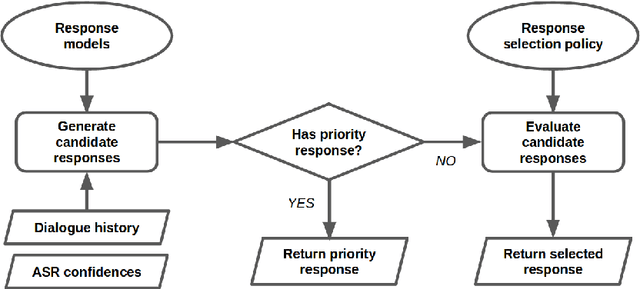
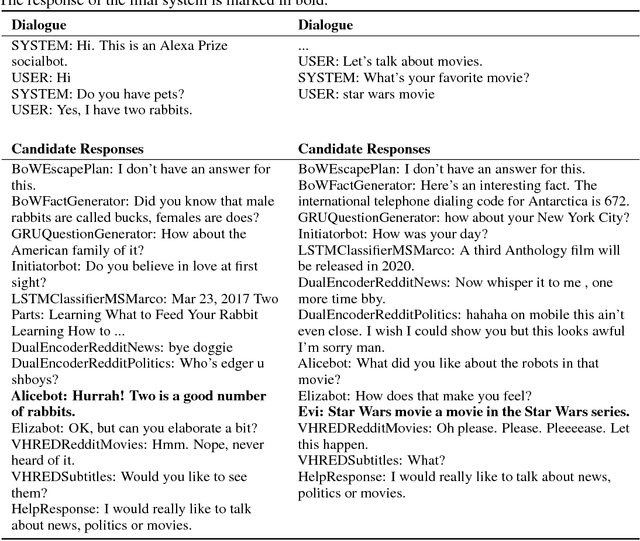
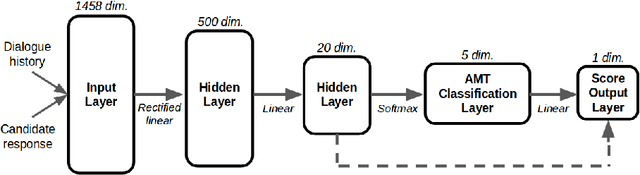

We present MILABOT: a deep reinforcement learning chatbot developed by the Montreal Institute for Learning Algorithms (MILA) for the Amazon Alexa Prize competition. MILABOT is capable of conversing with humans on popular small talk topics through both speech and text. The system consists of an ensemble of natural language generation and retrieval models, including template-based models, bag-of-words models, sequence-to-sequence neural network and latent variable neural network models. By applying reinforcement learning to crowdsourced data and real-world user interactions, the system has been trained to select an appropriate response from the models in its ensemble. The system has been evaluated through A/B testing with real-world users, where it performed significantly better than many competing systems. Due to its machine learning architecture, the system is likely to improve with additional data.
Deep Neural Networks for Anatomical Brain Segmentation
Jun 25, 2015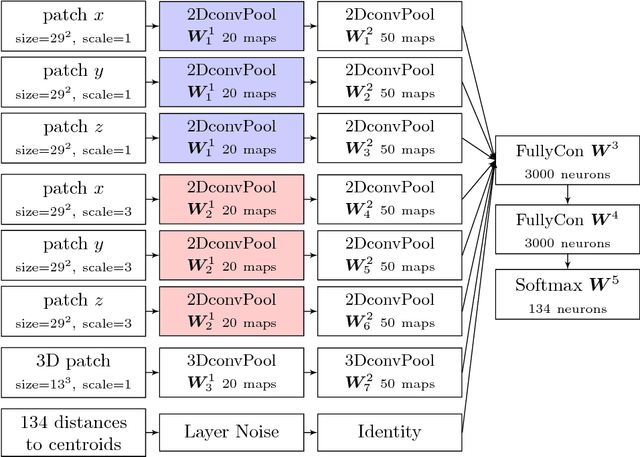
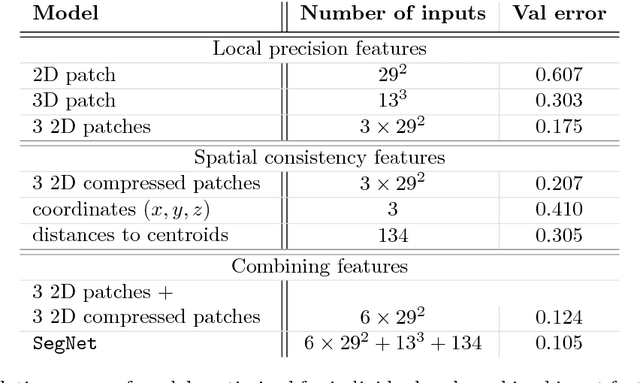

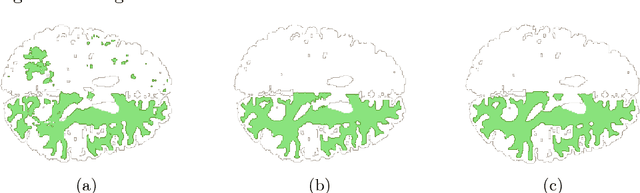
We present a novel approach to automatically segment magnetic resonance (MR) images of the human brain into anatomical regions. Our methodology is based on a deep artificial neural network that assigns each voxel in an MR image of the brain to its corresponding anatomical region. The inputs of the network capture information at different scales around the voxel of interest: 3D and orthogonal 2D intensity patches capture the local spatial context while large, compressed 2D orthogonal patches and distances to the regional centroids enforce global spatial consistency. Contrary to commonly used segmentation methods, our technique does not require any non-linear registration of the MR images. To benchmark our model, we used the dataset provided for the MICCAI 2012 challenge on multi-atlas labelling, which consists of 35 manually segmented MR images of the brain. We obtained competitive results (mean dice coefficient 0.725, error rate 0.163) showing the potential of our approach. To our knowledge, our technique is the first to tackle the anatomical segmentation of the whole brain using deep neural networks.