 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMelGAN: Generative Adversarial Networks for Conditional Waveform Synthesis
Oct 28, 2019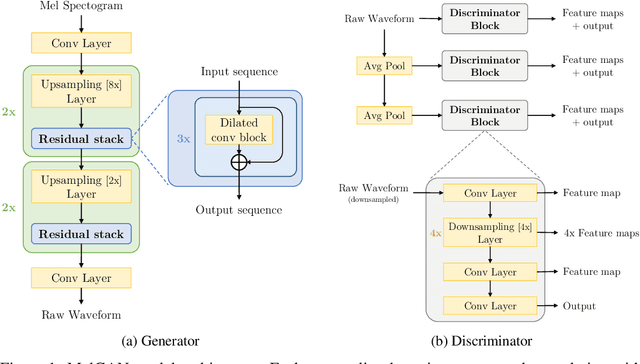


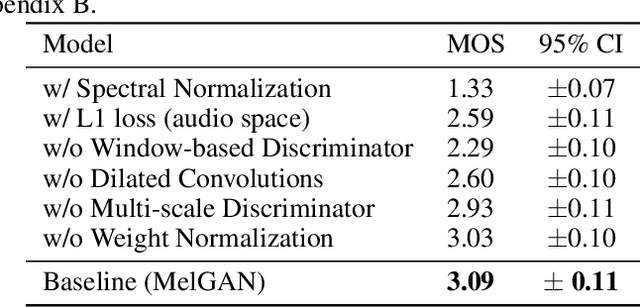
Previous works (Donahue et al., 2018a; Engel et al., 2019a) have found that generating coherent raw audio waveforms with GANs is challenging. In this paper, we show that it is possible to train GANs reliably to generate high quality coherent waveforms by introducing a set of architectural changes and simple training techniques. Subjective evaluation metric (Mean Opinion Score, or MOS) shows the effectiveness of the proposed approach for high quality mel-spectrogram inversion. To establish the generality of the proposed techniques, we show qualitative results of our model in speech synthesis, music domain translation and unconditional music synthesis. We evaluate the various components of the model through ablation studies and suggest a set of guidelines to design general purpose discriminators and generators for conditional sequence synthesis tasks. Our model is non-autoregressive, fully convolutional, with significantly fewer parameters than competing models and generalizes to unseen speakers for mel-spectrogram inversion. Our pytorch implementation runs at more than 100x faster than realtime on GTX 1080Ti GPU and more than 2x faster than real-time on CPU, without any hardware specific optimization tricks.