 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLePaRD: A Large-Scale Dataset of Judges Citing Precedents
Nov 15, 2023



We present the Legal Passage Retrieval Dataset LePaRD. LePaRD is a massive collection of U.S. federal judicial citations to precedent in context. The dataset aims to facilitate work on legal passage prediction, a challenging practice-oriented legal retrieval and reasoning task. Legal passage prediction seeks to predict relevant passages from precedential court decisions given the context of a legal argument. We extensively evaluate various retrieval approaches on LePaRD, and find that classification appears to work best. However, we note that legal precedent prediction is a difficult task, and there remains significant room for improvement. We hope that by publishing LePaRD, we will encourage others to engage with a legal NLP task that promises to help expand access to justice by reducing the burden associated with legal research. A subset of the LePaRD dataset is freely available and the whole dataset will be released upon publication.
Understanding Human Judgments of Causality
Dec 19, 2019

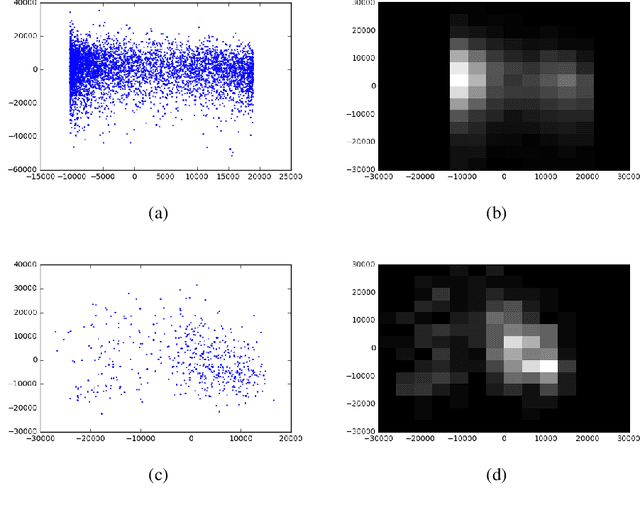
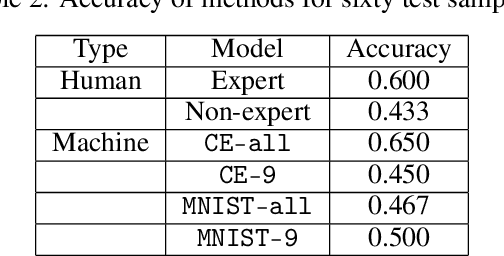
Discriminating between causality and correlation is a major problem in machine learning, and theoretical tools for determining causality are still being developed. However, people commonly make causality judgments and are often correct, even in unfamiliar domains. What are humans doing to make these judgments? This paper examines differences in human experts' and non-experts' ability to attribute causality by comparing their performances to those of machine-learning algorithms. We collected human judgments by using Amazon Mechanical Turk (MTurk) and then divided the human subjects into two groups: experts and non-experts. We also prepared expert and non-expert machine algorithms based on different training of convolutional neural network (CNN) models. The results showed that human experts' judgments were similar to those made by an "expert" CNN model trained on a large number of examples from the target domain. The human non-experts' judgments resembled the prediction outputs of the CNN model that was trained on only the small number of examples used during the MTurk instruction. We also analyzed the differences between the expert and non-expert machine algorithms based on their neural representations to evaluate the performances, providing insight into the human experts' and non-experts' cognitive abilities.
Urban Swarms: A new approach for autonomous waste management
Mar 01, 2019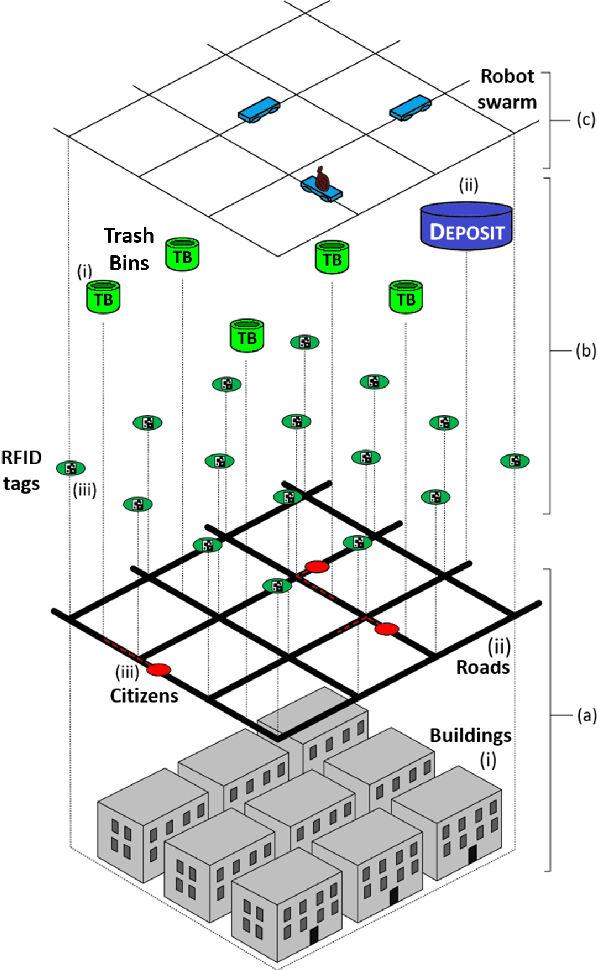
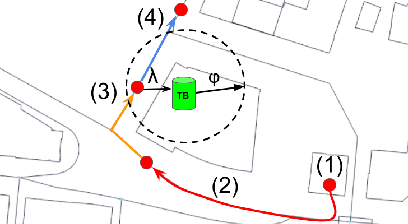

Modern cities are growing ecosystems that face new challenges due to the increasing population demands. One of the many problems they face nowadays is waste management, which has become a pressing issue requiring new solutions. Swarm robotics systems have been attracting an increasing amount of attention in the past years and they are expected to become one of the main driving factors for innovation in the field of robotics. The research presented in this paper explores the feasibility of a swarm robotics system in an urban environment. By using bio-inspired foraging methods such as multi-place foraging and stigmergy-based navigation, a swarm of robots is able to improve the efficiency and autonomy of the urban waste management system in a realistic scenario. To achieve this, a diverse set of simulation experiments was conducted using real-world GIS data and implementing different garbage collection scenarios driven by robot swarms. Results presented in this research show that the proposed system outperforms current approaches. Moreover, results not only show the efficiency of our solution, but also give insights about how to design and customize these systems.
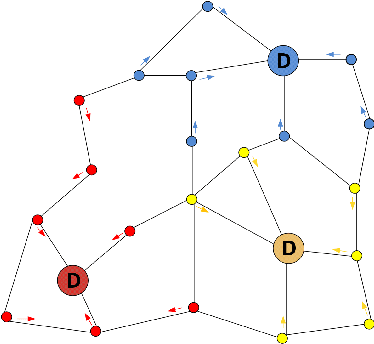
How to Organize your Deep Reinforcement Learning Agents: The Importance of Communication Topology
Nov 30, 2018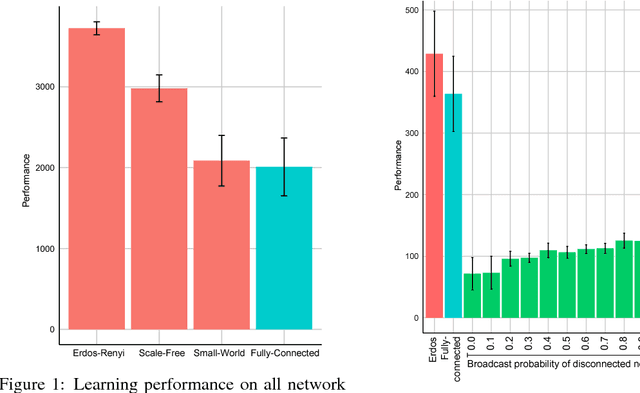

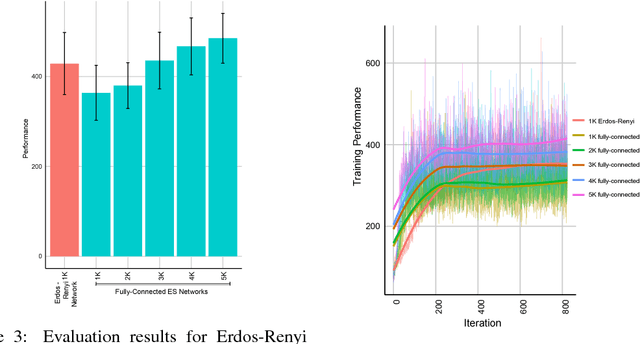
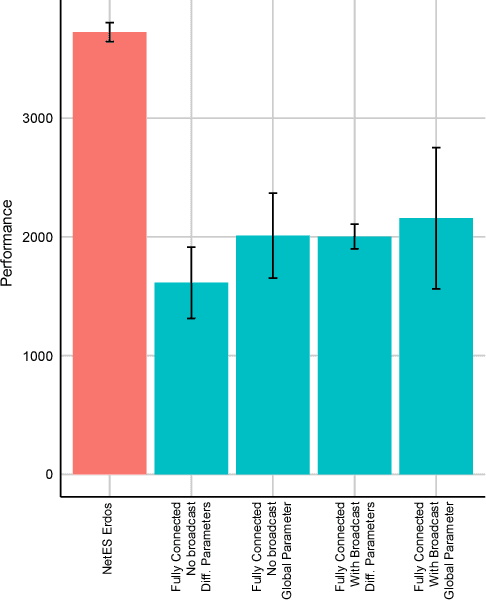
In this empirical paper, we investigate how learning agents can be arranged in more efficient communication topologies for improved learning. This is an important problem because a common technique to improve speed and robustness of learning in deep reinforcement learning and many other machine learning algorithms is to run multiple learning agents in parallel. The standard communication architecture typically involves all agents intermittently communicating with each other (fully connected topology) or with a centralized server (star topology). Unfortunately, optimizing the topology of communication over the space of all possible graphs is a hard problem, so we borrow results from the networked optimization and collective intelligence literatures which suggest that certain families of network topologies can lead to strong improvements over fully-connected networks. We start by introducing alternative network topologies to DRL benchmark tasks under the Evolution Strategies paradigm which we call Network Evolution Strategies. We explore the relative performance of the four main graph families and observe that one such family (Erdos-Renyi random graphs) empirically outperforms all other families, including the de facto fully-connected communication topologies. Additionally, the use of alternative network topologies has a multiplicative performance effect: we observe that when 1000 learning agents are arranged in a carefully designed communication topology, they can compete with 3000 agents arranged in the de facto fully-connected topology. Overall, our work suggests that distributed machine learning algorithms would learn more efficiently if the communication topology between learning agents was optimized.