 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Small-Scale Large Language Models Function Calling for Reasoning Tasks
Oct 24, 2024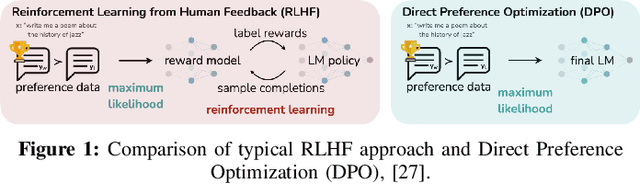

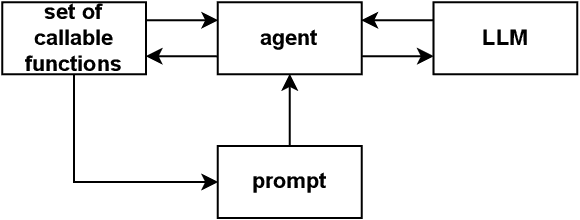
Recent advancements in Large Language Models (LLMs) have demonstrated exceptional capabilities in natural language understanding and generation. While these models excel in general complex reasoning tasks, they still face challenges in mathematical problem-solving and logical reasoning. To address these limitations, researchers have explored function calling abilities, allowing LLMs to execute provided functions and utilize their outputs for task completion. However, concentrating on specific tasks can be very inefficient for large-scale LLMs to be used, because of the expensive cost of training and inference stages they need in terms of computational resources. This study introduces a novel framework for training smaller language models in function calling, focusing on specific logical and mathematical reasoning tasks. The approach aims to improve performances of small-scale models for these tasks using function calling, ensuring a high level of accuracy. Our framework employs an agent that, given a problem and a set of callable functions, queries the LLM by injecting a description and examples of the usable functions into the prompt and managing their calls in a step-by-step reasoning chain. This process is used to create a dataset of correct and incorrect reasoning chain chat completions from a large-scale LLM. This dataset is used to train a smaller LLM using Reinforcement Learning from Human Feedback (RLHF), specifically employing the Direct Preference Optimization (DPO) technique. Experimental results demonstrate how the proposed approach balances the trade-off between model size and performance, improving the ability of function calling for reasoning tasks, in smaller models.
A machine learning workflow to address credit default prediction
Mar 06, 2024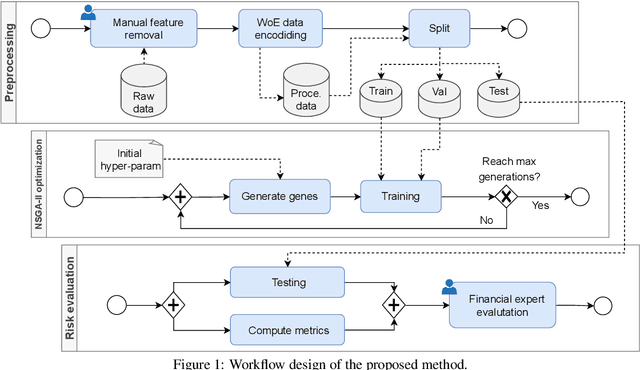

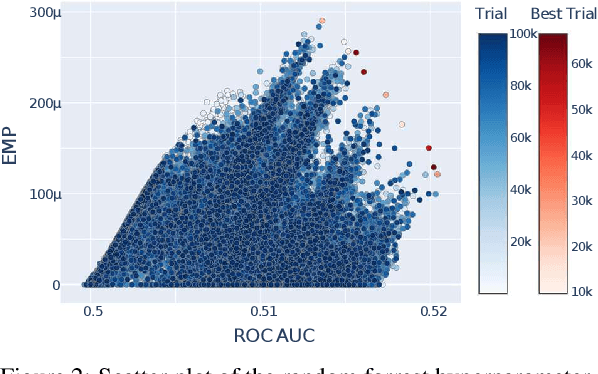
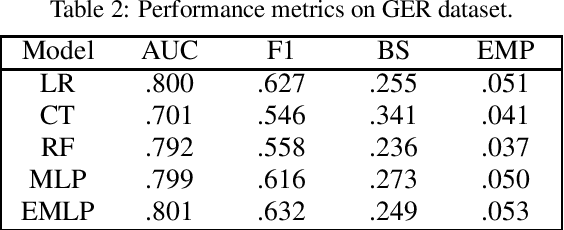
Due to the recent increase in interest in Financial Technology (FinTech), applications like credit default prediction (CDP) are gaining significant industrial and academic attention. In this regard, CDP plays a crucial role in assessing the creditworthiness of individuals and businesses, enabling lenders to make informed decisions regarding loan approvals and risk management. In this paper, we propose a workflow-based approach to improve CDP, which refers to the task of assessing the probability that a borrower will default on his or her credit obligations. The workflow consists of multiple steps, each designed to leverage the strengths of different techniques featured in machine learning pipelines and, thus best solve the CDP task. We employ a comprehensive and systematic approach starting with data preprocessing using Weight of Evidence encoding, a technique that ensures in a single-shot data scaling by removing outliers, handling missing values, and making data uniform for models working with different data types. Next, we train several families of learning models, introducing ensemble techniques to build more robust models and hyperparameter optimization via multi-objective genetic algorithms to consider both predictive accuracy and financial aspects. Our research aims at contributing to the FinTech industry in providing a tool to move toward more accurate and reliable credit risk assessment, benefiting both lenders and borrowers.
Cerbero-7B: A Leap Forward in Language-Specific LLMs Through Enhanced Chat Corpus Generation and Evaluation
Nov 27, 2023This study introduces a novel approach for generating high-quality, language-specific chat corpora using a self-chat mechanism. We combine a generator LLM for creating new samples and an embedder LLM to ensure diversity. A new Masked Language Modelling (MLM) model-based quality assessment metric is proposed for evaluating and filtering the corpora. Utilizing the llama2-70b as the generator and a multilingual sentence transformer as embedder, we generate an Italian chat corpus and refine the Fauno corpus, which is based on translated English ChatGPT self-chat data. The refinement uses structural assertions and Natural Language Processing techniques. Both corpora undergo a comprehensive quality evaluation using the proposed MLM model-based quality metric. The Italian LLM fine-tuned with these corpora demonstrates significantly enhanced language comprehension and question-answering skills. The resultant model, cerbero-7b, establishes a new state-of-the-art for Italian LLMs. This approach marks a substantial advancement in the development of language-specific LLMs, with a special emphasis on augmenting corpora for underrepresented languages like Italian.
TeTIm-Eval: a novel curated evaluation data set for comparing text-to-image models
Dec 15, 2022Evaluating and comparing text-to-image models is a challenging problem. Significant advances in the field have recently been made, piquing interest of various industrial sectors. As a consequence, a gold standard in the field should cover a variety of tasks and application contexts. In this paper a novel evaluation approach is experimented, on the basis of: (i) a curated data set, made by high-quality royalty-free image-text pairs, divided into ten categories; (ii) a quantitative metric, the CLIP-score, (iii) a human evaluation task to distinguish, for a given text, the real and the generated images. The proposed method has been applied to the most recent models, i.e., DALLE2, Latent Diffusion, Stable Diffusion, GLIDE and Craiyon. Early experimental results show that the accuracy of the human judgement is fully coherent with the CLIP-score. The dataset has been made available to the public.
Generating images from caption and vice versa via CLIP-Guided Generative Latent Space Search
Feb 26, 2021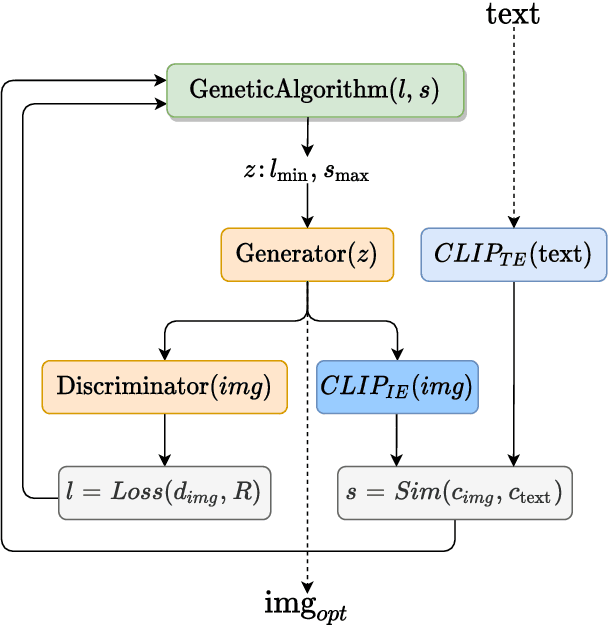



In this research work we present CLIP-GLaSS, a novel zero-shot framework to generate an image (or a caption) corresponding to a given caption (or image). CLIP-GLaSS is based on the CLIP neural network, which, given an image and a descriptive caption, provides similar embeddings. Differently, CLIP-GLaSS takes a caption (or an image) as an input, and generates the image (or the caption) whose CLIP embedding is the most similar to the input one. This optimal image (or caption) is produced via a generative network, after an exploration by a genetic algorithm. Promising results are shown, based on the experimentation of the image Generators BigGAN and StyleGAN2, and of the text Generator GPT2
Solving the scalarization issues of Advantage-based Reinforcement Learning Algorithms
Apr 08, 2020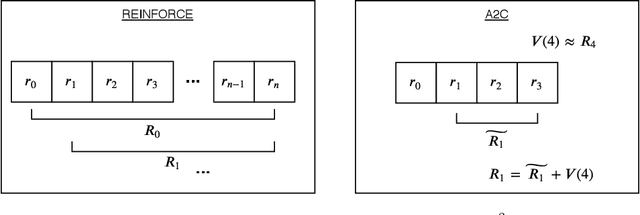
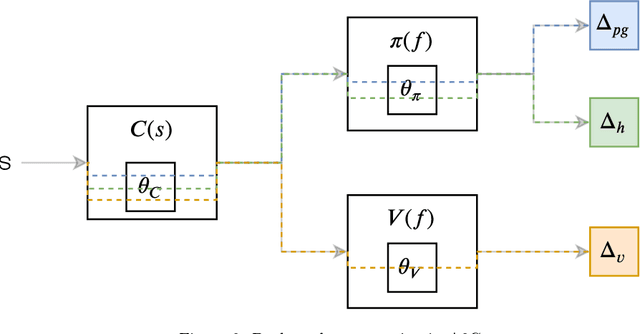
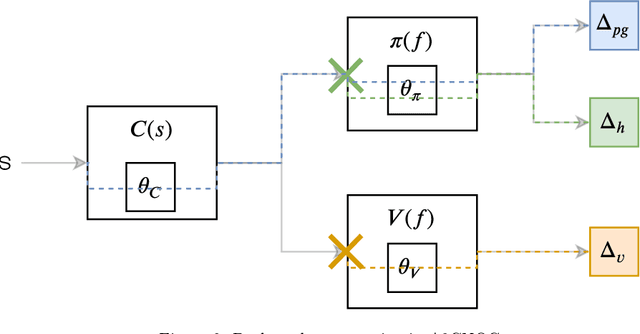
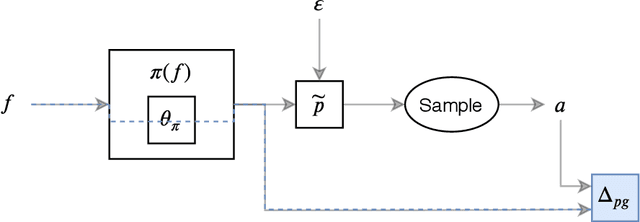
In this paper we investigate some of the issues that arise from the scalarization of the multi-objective optimization problem in the Advantage Actor Critic (A2C) reinforcement learning algorithm. We show how a naive scalarization leads to gradients overlapping and we also argue that the entropy regularization term just inject uncontrolled noise into the system. We propose two methods: one to avoid gradient overlapping (NOG) but keeping the same loss formulation; and one to avoid the noise injection (TE) but generating action distributions with a desired entropy. A comprehensive pilot experiment has been carried out showing how using our proposed methods speeds up the training of 210%. We argue how the proposed solutions can be applied to all the Advantage based reinforcement learning algorithms.
Formal derivation of Mesh Neural Networks with their Forward-Only gradient Propagation
May 19, 2019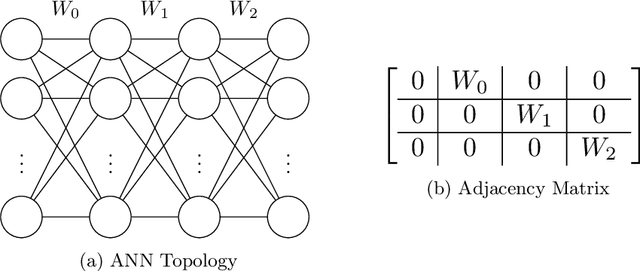
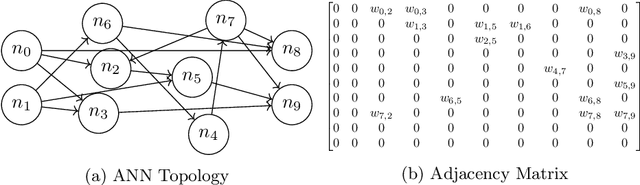
This paper proposes the Mesh Neural Network (MNN), a novel architecture which allows neurons to be connected in any topology, to efficiently route information. In MNNs, information is propagated between neurons throughout a state transition function. State and error gradients are then directly computed from state updates without backward computation. The MNN architecture and the error propagation schema is formalized and derived in tensor algebra. The proposed computational model can fully supply a gradient descent process, and is suitable for very large scale NNs, due to its expressivity and training efficiency, with respect to NNs based on back-propagation and computational graphs.
Urban Swarms: A new approach for autonomous waste management
Mar 01, 2019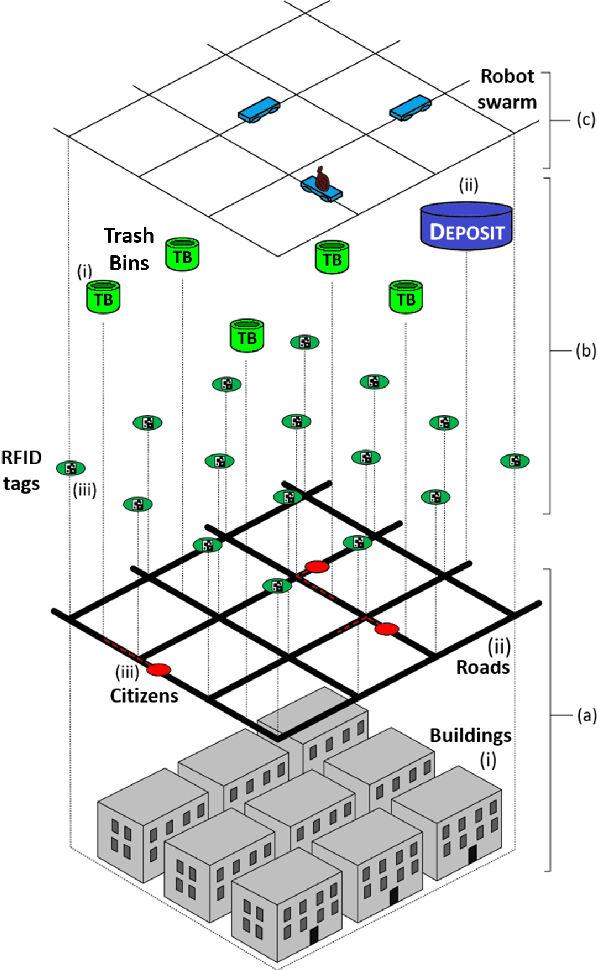
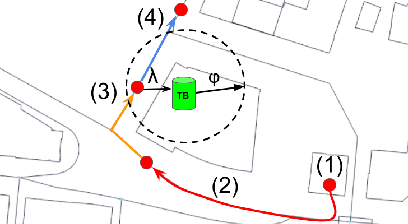

Modern cities are growing ecosystems that face new challenges due to the increasing population demands. One of the many problems they face nowadays is waste management, which has become a pressing issue requiring new solutions. Swarm robotics systems have been attracting an increasing amount of attention in the past years and they are expected to become one of the main driving factors for innovation in the field of robotics. The research presented in this paper explores the feasibility of a swarm robotics system in an urban environment. By using bio-inspired foraging methods such as multi-place foraging and stigmergy-based navigation, a swarm of robots is able to improve the efficiency and autonomy of the urban waste management system in a realistic scenario. To achieve this, a diverse set of simulation experiments was conducted using real-world GIS data and implementing different garbage collection scenarios driven by robot swarms. Results presented in this research show that the proposed system outperforms current approaches. Moreover, results not only show the efficiency of our solution, but also give insights about how to design and customize these systems.
A stigmergy-based analysis of city hotspots to discover trends and anomalies in urban transportation usage
Apr 16, 2018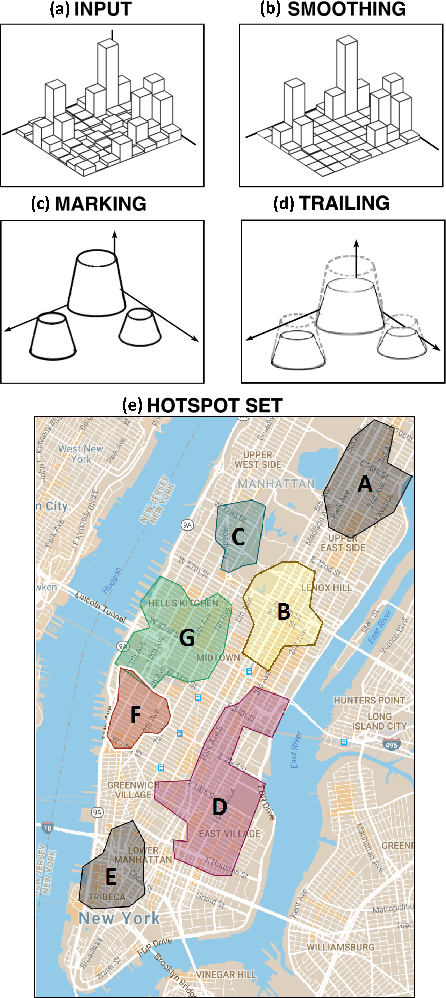

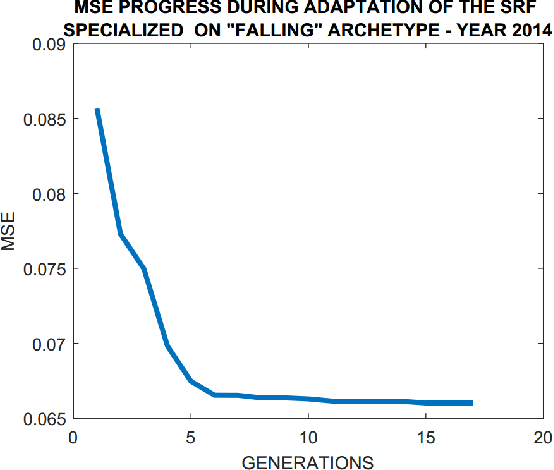
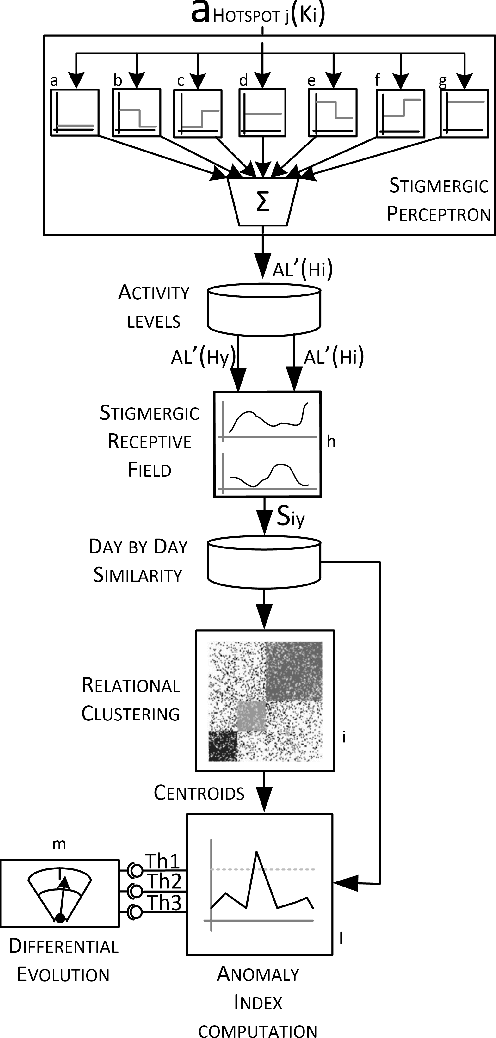
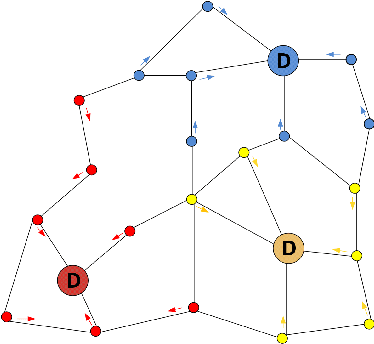
A key aspect of a sustainable urban transportation system is the effectiveness of transportation policies. To be effective, a policy has to consider a broad range of elements, such as pollution emission, traffic flow, and human mobility. Due to the complexity and variability of these elements in the urban area, to produce effective policies remains a very challenging task. With the introduction of the smart city paradigm, a widely available amount of data can be generated in the urban spaces. Such data can be a fundamental source of knowledge to improve policies because they can reflect the sustainability issues underlying the city. In this context, we propose an approach to exploit urban positioning data based on stigmergy, a bio-inspired mechanism providing scalar and temporal aggregation of samples. By employing stigmergy, samples in proximity with each other are aggregated into a functional structure called trail. The trail summarizes relevant dynamics in data and allows matching them, providing a measure of their similarity. Moreover, this mechanism can be specialized to unfold specific dynamics. Specifically, we identify high-density urban areas (i.e hotspots), analyze their activity over time, and unfold anomalies. Moreover, by matching activity patterns, a continuous measure of the dissimilarity with respect to the typical activity pattern is provided. This measure can be used by policy makers to evaluate the effect of policies and change them dynamically. As a case study, we analyze taxi trip data gathered in Manhattan from 2013 to 2015.
Stigmergy-based modeling to discover urban activity patterns from positioning data
Apr 12, 2017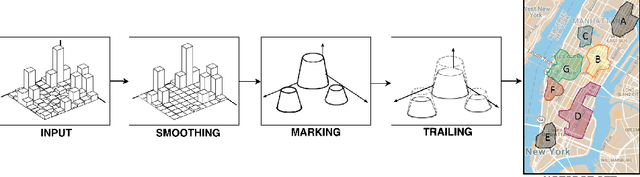

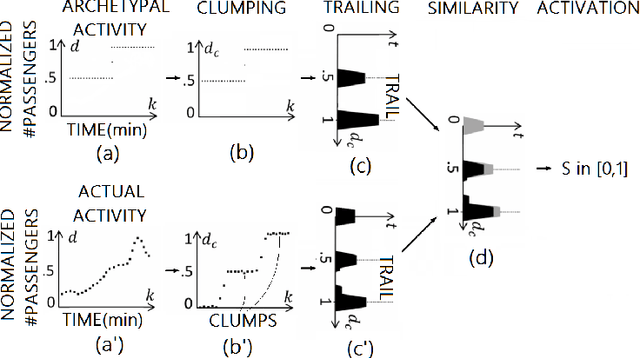
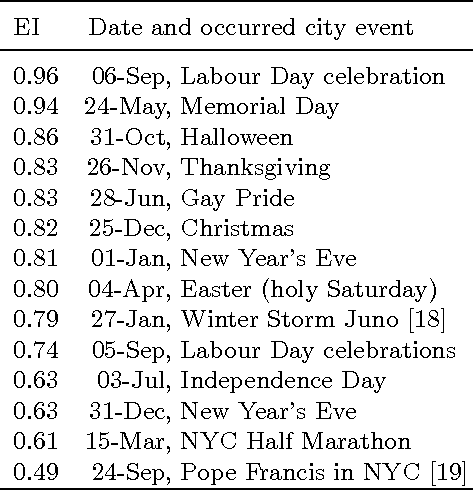
Positioning data offer a remarkable source of information to analyze crowds urban dynamics. However, discovering urban activity patterns from the emergent behavior of crowds involves complex system modeling. An alternative approach is to adopt computational techniques belonging to the emergent paradigm, which enables self-organization of data and allows adaptive analysis. Specifically, our approach is based on stigmergy. By using stigmergy each sample position is associated with a digital pheromone deposit, which progressively evaporates and aggregates with other deposits according to their spatiotemporal proximity. Based on this principle, we exploit positioning data to identify high density areas (hotspots) and characterize their activity over time. This characterization allows the comparison of dynamics occurring in different days, providing a similarity measure exploitable by clustering techniques. Thus, we cluster days according to their activity behavior, discovering unexpected urban activity patterns. As a case study, we analyze taxi traces in New York City during 2015.