 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSolving the scalarization issues of Advantage-based Reinforcement Learning Algorithms
Paper and Code
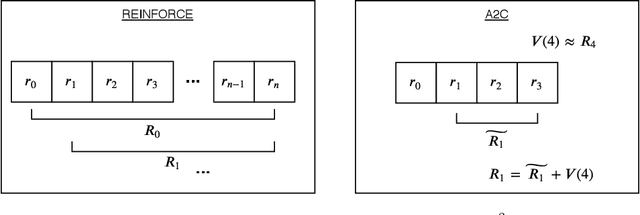
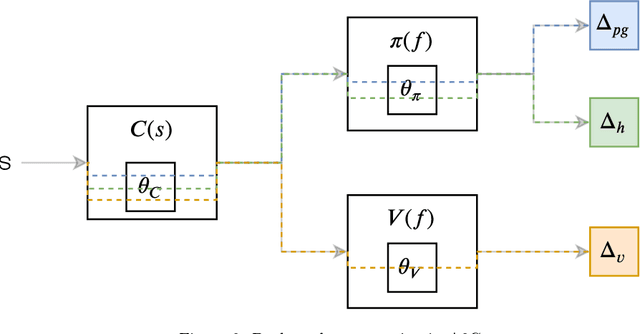
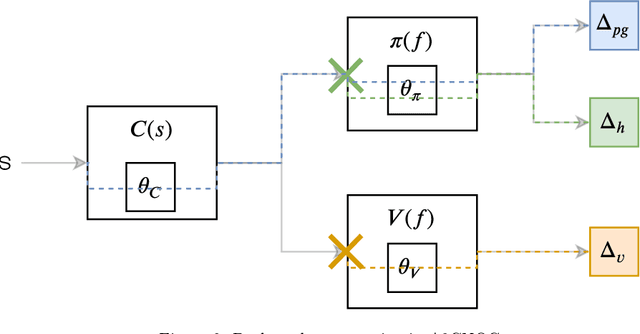
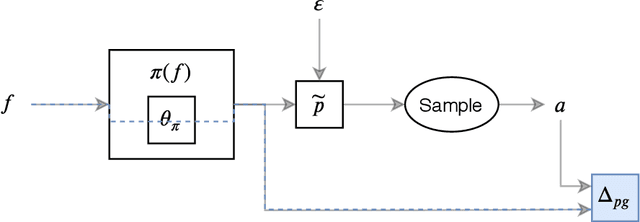
In this paper we investigate some of the issues that arise from the scalarization of the multi-objective optimization problem in the Advantage Actor Critic (A2C) reinforcement learning algorithm. We show how a naive scalarization leads to gradients overlapping and we also argue that the entropy regularization term just inject uncontrolled noise into the system. We propose two methods: one to avoid gradient overlapping (NOG) but keeping the same loss formulation; and one to avoid the noise injection (TE) but generating action distributions with a desired entropy. A comprehensive pilot experiment has been carried out showing how using our proposed methods speeds up the training of 210%. We argue how the proposed solutions can be applied to all the Advantage based reinforcement learning algorithms.