 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Small-Scale Large Language Models Function Calling for Reasoning Tasks
Oct 24, 2024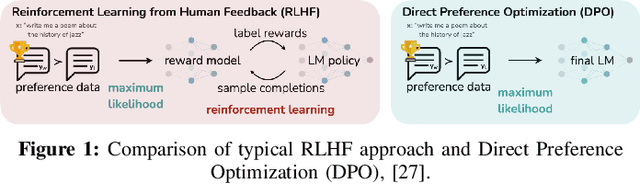

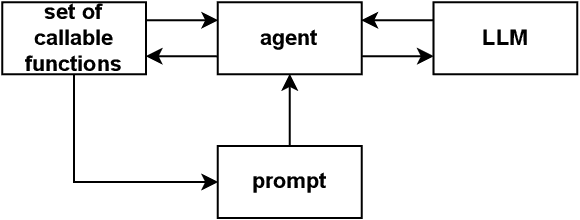
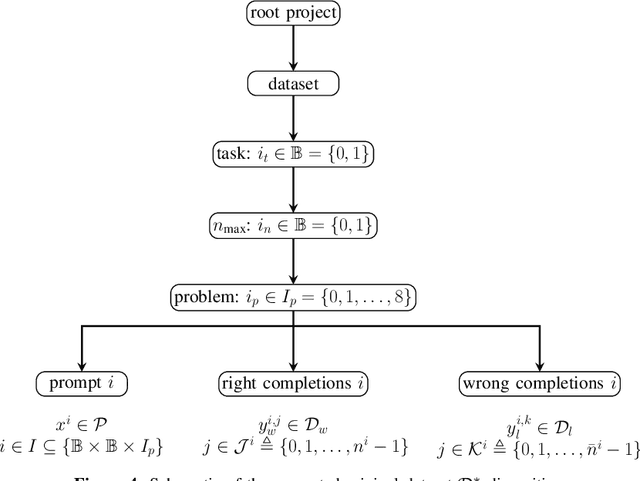
Recent advancements in Large Language Models (LLMs) have demonstrated exceptional capabilities in natural language understanding and generation. While these models excel in general complex reasoning tasks, they still face challenges in mathematical problem-solving and logical reasoning. To address these limitations, researchers have explored function calling abilities, allowing LLMs to execute provided functions and utilize their outputs for task completion. However, concentrating on specific tasks can be very inefficient for large-scale LLMs to be used, because of the expensive cost of training and inference stages they need in terms of computational resources. This study introduces a novel framework for training smaller language models in function calling, focusing on specific logical and mathematical reasoning tasks. The approach aims to improve performances of small-scale models for these tasks using function calling, ensuring a high level of accuracy. Our framework employs an agent that, given a problem and a set of callable functions, queries the LLM by injecting a description and examples of the usable functions into the prompt and managing their calls in a step-by-step reasoning chain. This process is used to create a dataset of correct and incorrect reasoning chain chat completions from a large-scale LLM. This dataset is used to train a smaller LLM using Reinforcement Learning from Human Feedback (RLHF), specifically employing the Direct Preference Optimization (DPO) technique. Experimental results demonstrate how the proposed approach balances the trade-off between model size and performance, improving the ability of function calling for reasoning tasks, in smaller models.