 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA machine learning workflow to address credit default prediction
Mar 06, 2024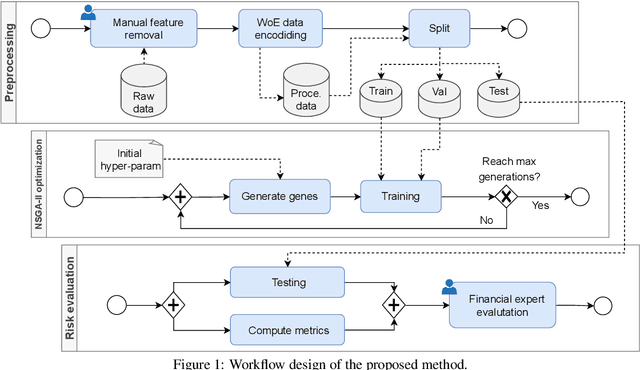

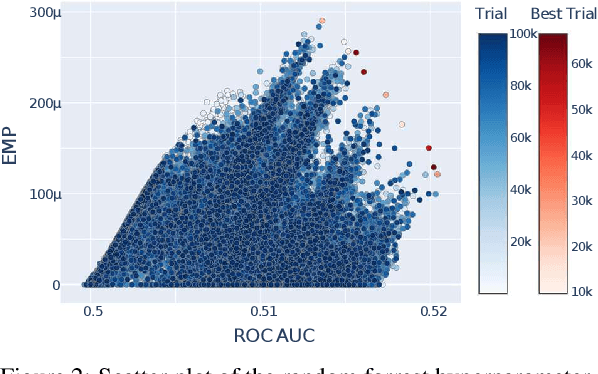
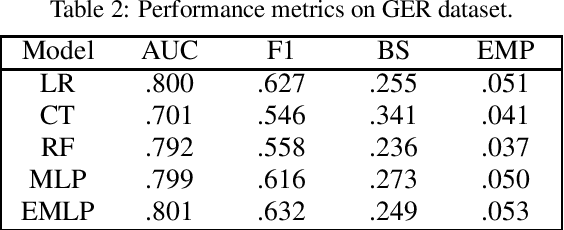
Due to the recent increase in interest in Financial Technology (FinTech), applications like credit default prediction (CDP) are gaining significant industrial and academic attention. In this regard, CDP plays a crucial role in assessing the creditworthiness of individuals and businesses, enabling lenders to make informed decisions regarding loan approvals and risk management. In this paper, we propose a workflow-based approach to improve CDP, which refers to the task of assessing the probability that a borrower will default on his or her credit obligations. The workflow consists of multiple steps, each designed to leverage the strengths of different techniques featured in machine learning pipelines and, thus best solve the CDP task. We employ a comprehensive and systematic approach starting with data preprocessing using Weight of Evidence encoding, a technique that ensures in a single-shot data scaling by removing outliers, handling missing values, and making data uniform for models working with different data types. Next, we train several families of learning models, introducing ensemble techniques to build more robust models and hyperparameter optimization via multi-objective genetic algorithms to consider both predictive accuracy and financial aspects. Our research aims at contributing to the FinTech industry in providing a tool to move toward more accurate and reliable credit risk assessment, benefiting both lenders and borrowers.
Web image search engine based on LSH index and CNN Resnet50
Aug 20, 2021

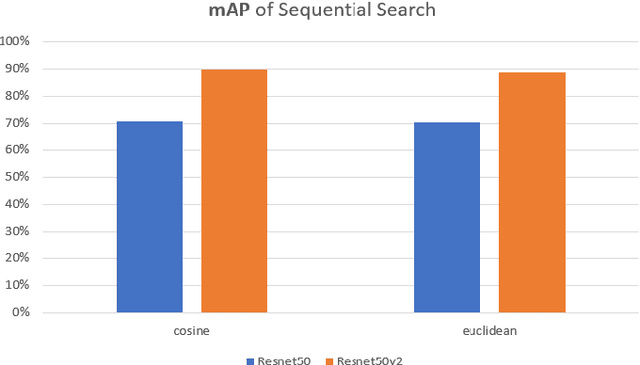
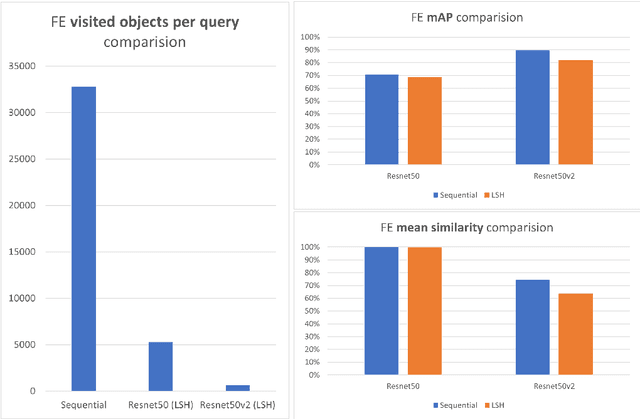
To implement a good Content Based Image Retrieval (CBIR) system, it is essential to adopt efficient search methods. One way to achieve this results is by exploiting approximate search techniques. In fact, when we deal with very large collections of data, using an exact search method makes the system very slow. In this project, we adopt the Locality Sensitive Hashing (LSH) index to implement a CBIR system that allows us to perform fast similarity search on deep features. Specifically, we exploit transfer learning techniques to extract deep features from images; this phase is done using two famous Convolutional Neural Networks (CNNs) as features extractors: Resnet50 and Resnet50v2, both pre-trained on ImageNet. Then we try out several fully connected deep neural networks, built on top of both of the previously mentioned CNNs in order to fine-tuned them on our dataset. In both of previous cases, we index the features within our LSH index implementation and within a sequential scan, to better understand how much the introduction of the index affects the results. Finally, we carry out a performance analysis: we evaluate the relevance of the result set, computing the mAP (mean Average Precision) value obtained during the different experiments with respect to the number of done comparison and varying the hyper-parameter values of the LSH index.