Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerating images from caption and vice versa via CLIP-Guided Generative Latent Space Search
Paper and Code
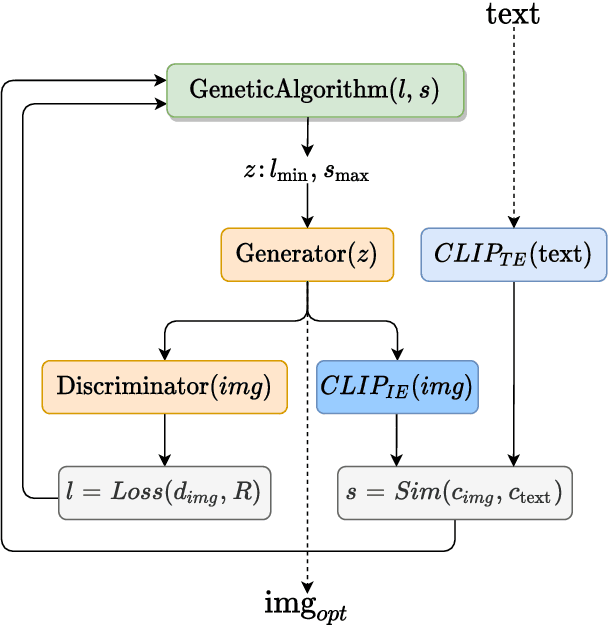



In this research work we present CLIP-GLaSS, a novel zero-shot framework to generate an image (or a caption) corresponding to a given caption (or image). CLIP-GLaSS is based on the CLIP neural network, which, given an image and a descriptive caption, provides similar embeddings. Differently, CLIP-GLaSS takes a caption (or an image) as an input, and generates the image (or the caption) whose CLIP embedding is the most similar to the input one. This optimal image (or caption) is produced via a generative network, after an exploration by a genetic algorithm. Promising results are shown, based on the experimentation of the image Generators BigGAN and StyleGAN2, and of the text Generator GPT2
View paper on