 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData Set Terminology of Artificial Intelligence in Medicine: A Historical Review and Recommendation
Apr 30, 2024Medicine and artificial intelligence (AI) engineering represent two distinct fields each with decades of published history. With such history comes a set of terminology that has a specific way in which it is applied. However, when two distinct fields with overlapping terminology start to collaborate, miscommunication and misunderstandings can occur. This narrative review aims to give historical context for these terms, accentuate the importance of clarity when these terms are used in medical AI contexts, and offer solutions to mitigate misunderstandings by readers from either field. Through an examination of historical documents, including articles, writing guidelines, and textbooks, this review traces the divergent evolution of terms for data sets and their impact. Initially, the discordant interpretations of the word 'validation' in medical and AI contexts are explored. Then the data sets used for AI evaluation are classified, namely random splitting, cross-validation, temporal, geographic, internal, and external sets. The accurate and standardized description of these data sets is crucial for demonstrating the robustness and generalizability of AI applications in medicine. This review clarifies existing literature to provide a comprehensive understanding of these classifications and their implications in AI evaluation. This review then identifies often misunderstood terms and proposes pragmatic solutions to mitigate terminological confusion. Among these solutions are the use of standardized terminology such as 'training set,' 'validation (or tuning) set,' and 'test set,' and explicit definition of data set splitting terminologies in each medical AI research publication. This review aspires to enhance the precision of communication in medical AI, thereby fostering more effective and transparent research methodologies in this interdisciplinary field.
Federated Learning Enables Big Data for Rare Cancer Boundary Detection
Apr 25, 2022Although machine learning (ML) has shown promise in numerous domains, there are concerns about generalizability to out-of-sample data. This is currently addressed by centrally sharing ample, and importantly diverse, data from multiple sites. However, such centralization is challenging to scale (or even not feasible) due to various limitations. Federated ML (FL) provides an alternative to train accurate and generalizable ML models, by only sharing numerical model updates. Here we present findings from the largest FL study to-date, involving data from 71 healthcare institutions across 6 continents, to generate an automatic tumor boundary detector for the rare disease of glioblastoma, utilizing the largest dataset of such patients ever used in the literature (25,256 MRI scans from 6,314 patients). We demonstrate a 33% improvement over a publicly trained model to delineate the surgically targetable tumor, and 23% improvement over the tumor's entire extent. We anticipate our study to: 1) enable more studies in healthcare informed by large and diverse data, ensuring meaningful results for rare diseases and underrepresented populations, 2) facilitate further quantitative analyses for glioblastoma via performance optimization of our consensus model for eventual public release, and 3) demonstrate the effectiveness of FL at such scale and task complexity as a paradigm shift for multi-site collaborations, alleviating the need for data sharing.
The utility of a convolutional neural network for generating a myelin volume index map from rapid simultaneous relaxometry imaging
Apr 24, 2019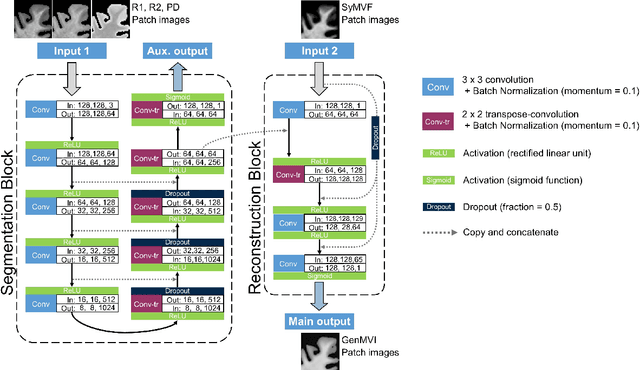
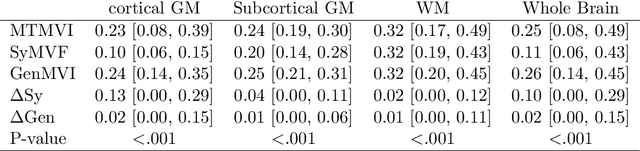
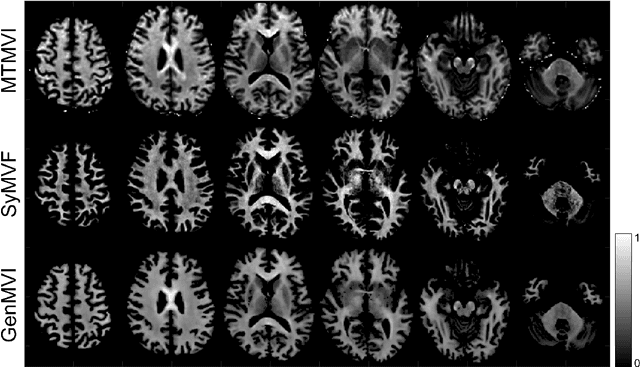
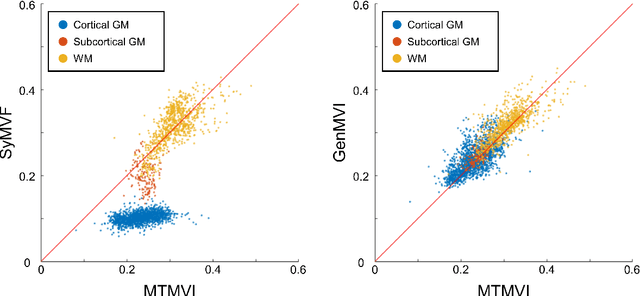
Background and Purpose: A current algorithm to obtain a synthetic myelin volume fraction map (SyMVF) from rapid simultaneous relaxometry imaging (RSRI) has a potential problem, that it does not incorporate information from surrounding pixels. The purpose of this study was to develop a method that utilizes a convolutional neural network (CNN) to overcome this problem. Methods: RSRI and magnetization transfer images from 20 healthy volunteers were included. A CNN was trained to reconstruct RSRI-related metric maps into a myelin volume-related index (generated myelin volume index: GenMVI) map using the myelin volume index map calculated from magnetization transfer images (MTMVI) as reference. The SyMVF and GenMVI maps were statistically compared by testing how well they correlated with the MTMVI map. The correlations were evaluated based on: (i) averaged values obtained from 164 atlas-based ROIs, and (ii) pixel-based comparison for ROIs defined in four different tissue types (cortical and subcortical gray matter, white matter, and whole brain). Results: For atlas-based ROIs, the overall correlation with the MTMVI map was higher for the GenMVI map than for the SyMVF map. In the pixel-based comparison, correlation with the MTMVI map was stronger for the GenMVI map than for the SyMVF map, and the difference in the distribution for the volunteers was significant (Wilcoxon sign-rank test, P<.001) in all tissue types. Conclusion: The proposed method is useful, as it can incorporate more specific information about local tissue properties than the existing method.